
How to Analyze Video Data Using Hadoop?

Video is the future of content marketing and reaches a large mass of customers within no time. Digital media environment is evolving rapidly and the increasing usage of smartphones and tablets has changed the overall consumption habits of audiences across the globe. Not just the social networking sites are swamped with videos; even the surveillance cameras that are installed in public places such as roads, malls, shopping complexes generate huge amount of video content every day. Today, even organizations are finding it a challenging task to manage and handle such enormous amount of data efficiently.
Is there an effective way to manage and analyze big data generated from videos?
Well, this blog talks about Hadoop and HIPI technology that helps organization to manage video data efficiently and effectively.
Hadoop is an open-source framework that allows user to store and process data faster in a distributed environment.
Hadoop Architecture:
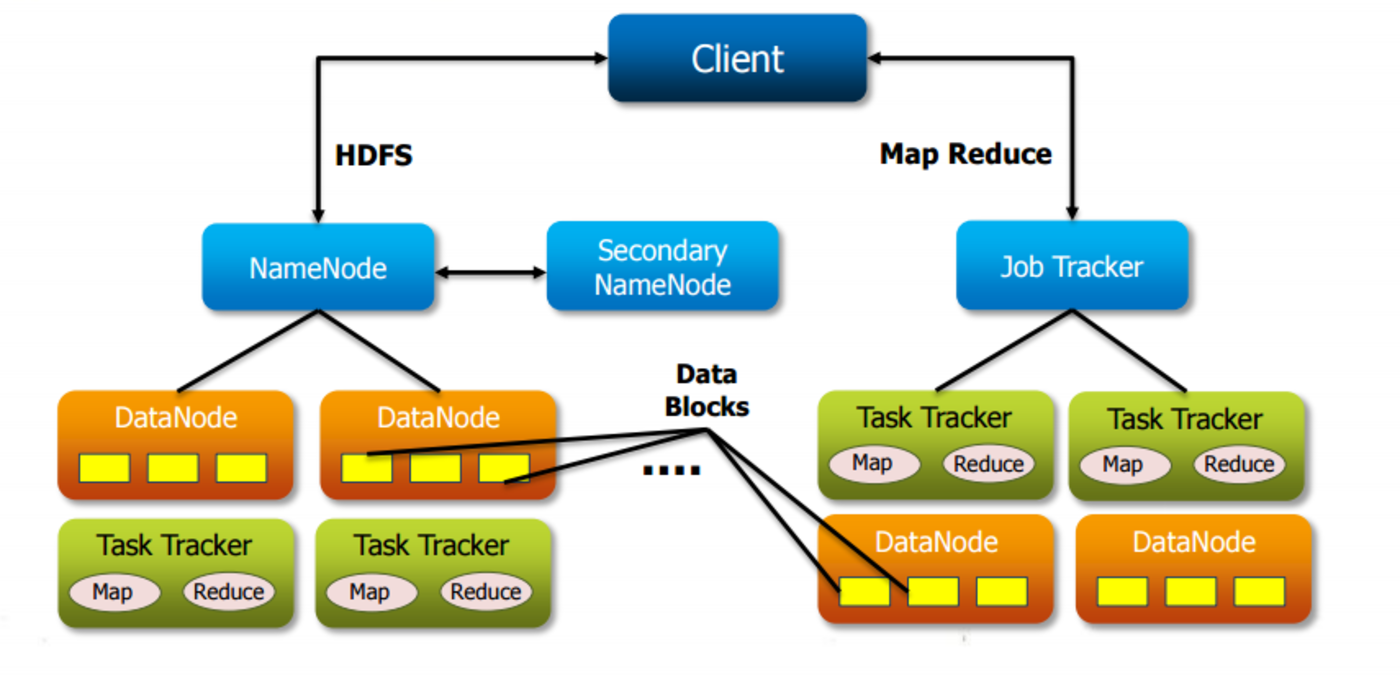
The two core components of Hadoop Framework are Hadoop Distributed File System (HDFS) and MapReduce. The Hadoop Distributed File System (HDFS) is the storage bin which is designed to store large amount of data and MapReduce is the heart of the framework that processes the large set of data. Both HDFS and MapReduce follows the master and slave architecture in which many slaves are monitored by a single master.
HDFS has two other sub-components namely NameNode – which acts as a master node; other is DataNode – which act as a slave node.
NameNode: In HDFS cluster, a single NameNode controls all the DataNodes present in the cluster. NameNode contains all the metadata which provides information as to which data is stored at which DataNode. The system also provides information on the free DataNode while storing the data in a cluster
DataNode: DataNode stores all the actual data which is also replicated on various DataNodes
Similarly in MapReduce has two sub-components namely JobTracker – which is a master node and TaskTracker – which is a slave node.
JobTracker: In a HDFS cluster, a single JobTracker controls all the other TaskTrackers present in the cluster. The function of a JobTracker is to assign job to the TaskTracker. It also takes care of job scheduling and resource allocation
TaskTracker: TaskTracker acts as a slave daemon that accepts the task assigned by JobTracker. A TaskTracker also sends across a heartbeat to the JobTracker in every 3 seconds to which means that the DataNode is alive.
Operations Performed During Video Analytics using Hadoop
Architecture:
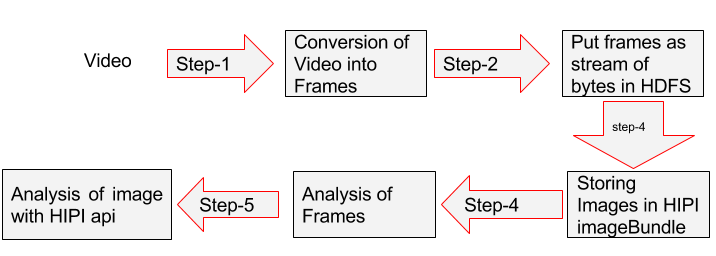
1) Conversion of Video into Frames: JCodec is an open source library for video codecs and formats that is implemented on Java.There are various tools for the digital transcoding of the video data into frames such as JCodec, Xuggler.
The following code is used to convert the video into a frame:
[js]
int frameNo = 785;
BufferedImage frame1 = FrameGrab.getFrame(new File("video.mp4"), frameNo);
ImageIO.write(frame1, "png", new File("abc.png"));
[/js]
2) Put Frames in the HDFS: Putting frames or images in the HDFS using the put command is not possible. So to store the images or frames into the HDFS, first convert the frames as the stream of bytes and then store in HDFS. Hadoop provides us the facility to read/write binary files. So, practically anything which can be converted into bytes can be stored in HDFS.
3) Store images in an HIPI ImageBundle: After the process of transcoding the images, these are combined into a single large file so that it can easily be managed and analyzed. Using the add image method, we can add every image into the HIPI imageBundle. So HIPI ImageBundle can be considered as a bunch of Images. Each mapper will generate an HIPI ImageBundle, and the Reducer will merge all bundles into a single large bundle. By storing images in this way now you are able to work on HIPI framework. Now MapReduce jobs are running on these image Bundles for image analysis.
4) Analysis Of Frame by HIPI Framework: HIPI is an image processing library designed to process a large number of images with the help of Hadoop MapReduce parallel programming framework. HIPI facilitates efficient and high-throughput image processing with MapReduce style parallel programs typically executed on a cluster. It provides a solution to store a large collection of images on the Hadoop Distributed File System (HDFS) and make them available for efficient distributed processing.
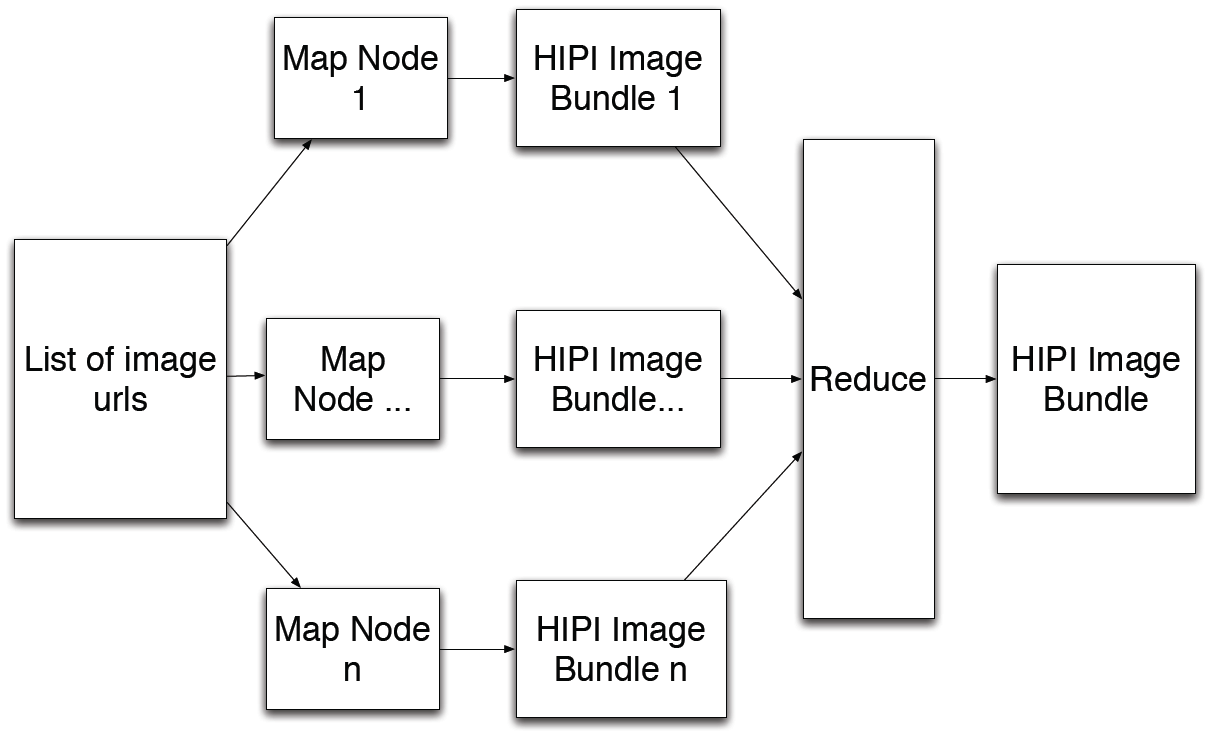
The primary input object of a HIPI program is HIB. An HIB is a collection of images represented as a single file on the HDFS.
(A). Figure shows the formation of HIPI ImageBundle with various images:
(B). Analysis of Hipi ImageBundle:
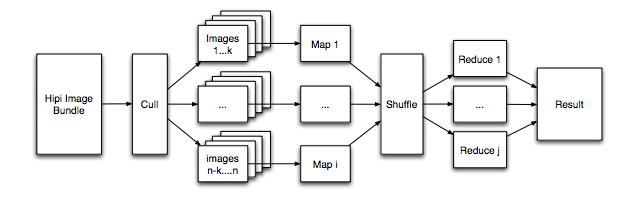
The above images provides a easy way to understand how the videos are ingested in Hadoop cluster and parallel transcoding is performed to create a set of JPEG images using JCodec. When all the images are combined into a bundle, it is also known as HIPI ImageBundle. This is when a user can analyse the images stored in the DataNode using MapReduce programing. The data analyzed from the extracted information can also help in solving many issues such as bank robbery cases, streamlining and controlling traffic and business forgery.
Here is the list with few examples where such video data analytics can be useful
- CCTV camera video footage analysis can help various department to take steps for women security across the country
- Video analysis can help solving a bank robbery case quickly.
- Road traffic video analytics can help streamlining traffic, minimizing road accidents and ensure road safety.

Great Work.Big data is becoming an effective basis for competition in pretty much every industry.I wish you luck as you continue to follow that passion.
Thank you for sharing great article related to hadoop. i am intrested to read the hadoop related blog. thank you.
Thanks for sharing. A very good article.
Great article on Big data Hadoop.
Big data hadoop is an emerging technology and the demand for hadoop professionals also high nowadays.