
How to Setup Kubernetes Master HA on CentOS?

This blog describes how to set up a high-availability (HA) Kubernetes cluster. This is an advanced topic and setting up a truly reliable, highly available distributed system requires few steps to be performed. We will go into each of these steps in detail, but a summary will help the user as a guide.
Here’s what the system should look like when it’s finished:
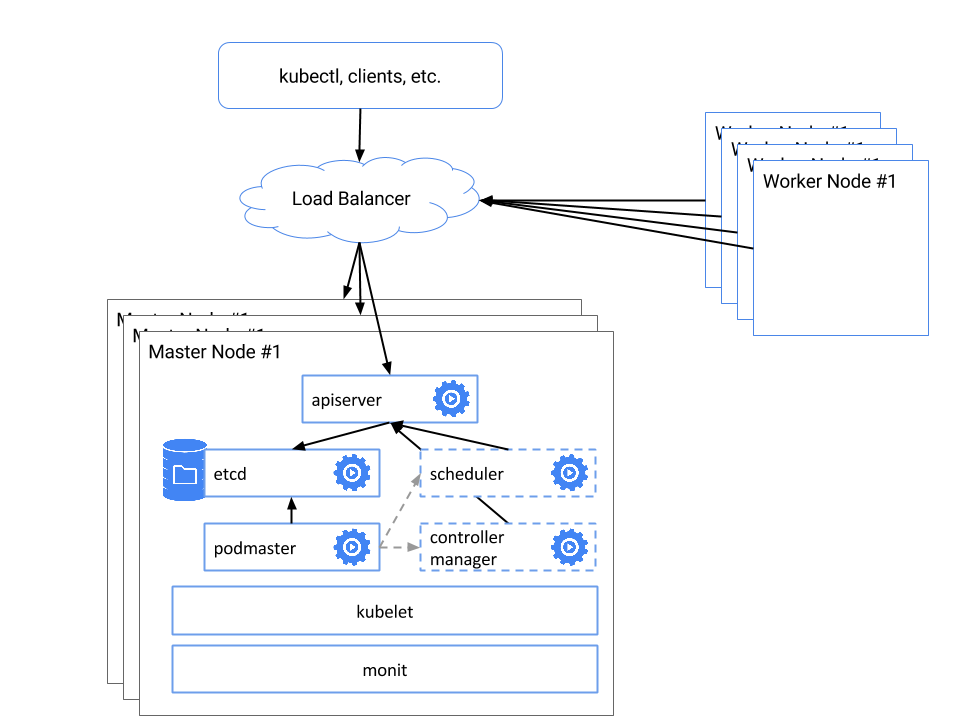
Prerequisites: You should have an existing Kubernetes Cluster on Bare Metal on CentOS. It means Master1 is already configured for the cluster but we need to make some changes on existing master to create ETCD cluster. Refer to this blog to learn how to setup a Kubernetes cluster on CentOS.
Assumptions: We are taking following assumptions for the blog:
[js]Master1: 172.16.0.1
Master2:172.16.0.2
Master3: 172.16.0.3[/js]
Steps to configure Kubernetes Master HA
1. Install Kubernetes on Master2 and Master3: Create a new repo for Kubernetes using the following command:
[js]vi /etc/yum.repos.d/virt7-docker-common-release.repo
[virt7-docker-common-release]
name=virt7-docker-common-release
baseurl=http://cbs.centos.org/repos/virt7-docker-common-release/x86_64/os/
gpgcheck=0[/js]
Now Install Kubernetes:
[js]yum -y install –enablerepo=virt7-docker-common-release kubernetes etcd flannel[/js]
The above command also installs Docker and cadvisor.
2. Create ETCD Cluster using following etcd configuration: ETCD configuration file is located at /etc/etcd/etcd.conf
For Master1
[js]# [member]
ETCD_NAME=infra0
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="http://172.16.0.1:2380"
ETCD_LISTEN_CLIENT_URLS="http://172.16.0.1:2379.http://127.0.0.1:2379"
#
#[cluster]
ETCD_INITIAL_CLUSTER="infra0=http://172.16.0.1:2380,infra1=http://172.16.0.2:2380,infra2=http://172.16.0.3:2380"
ETCD_INITIAL_CLUSTER_STATE="new"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_ADVERTISE_CLIENT_URLS="http://172.16.0.1:2379"
[/js]
For Master2
[js]# [member]
ETCD_NAME=infra1
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="http://172.16.0.2:2380"
ETCD_LISTEN_CLIENT_URLS="http://172.16.0.2:2379.http://127.0.0.1:2379"
#
#[cluster]
ETCD_INITIAL_CLUSTER="infra0=http://172.16.0.1:2380,infra1=http://172.16.0.2:2380,infra2=http://172.16.0.3:2380"
ETCD_INITIAL_CLUSTER_STATE="new"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_ADVERTISE_CLIENT_URLS="http://172.16.0.2:2379"
[/js]
For Master3
[js]# [member]
ETCD_NAME=infra2
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="http://172.16.0.3:2380"
ETCD_LISTEN_CLIENT_URLS="http://172.16.0.3:2379,http://127.0.0.1:2379"
#
#[cluster]
ETCD_INITIAL_CLUSTER="infra0=http://172.16.0.1:2380,infra1=http://172.16.0.2:2380,infra2=http://172.16.0.3:2380"
ETCD_INITIAL_CLUSTER_STATE="new"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_ADVERTISE_CLIENT_URLS="http://172.16.0.3:2379"
Restart etcd in all the master nodes using following command:
systemctl restart etcd
Run the following command in any one of the etcd node to check if etcd cluster is formed properly:
etcdctl cluster-health
[/js]
3. Configure other Kubernetes master components: Let’s start with Kubernetes common config
On Master
[js]vi /etc/kubernetes/config
# Comma separated list of nodes running etcd cluster
KUBE_ETCD_SERVERS="–etcd-servers=http://Master_Private_IP:2379"
# Logging will be stored in system journal
KUBE_LOGTOSTDERR="–logtostderr=true"
# Journal message level, 0 is debug
KUBE_LOG_LEVEL="–v=0"
# Should this cluster be allowed to run privileged docker containers
KUBE_ALLOW_PRIV="–allow-privileged=false"
# Api-server endpoint used in scheduler and controller-manager
KUBE_MASTER="–master=http://Master_Private_IP:8080"[/js]
On Minion
[js]vi /etc/kubernetes/config
# Comma separated list of nodes running etcd cluster
KUBE_ETCD_SERVERS="–etcd-servers=http://k8_Master:2379"
# Logging will be stored in system journal
KUBE_LOGTOSTDERR="–logtostderr=true"
# Journal message level, 0 is debug
KUBE_LOG_LEVEL="–v=0"
# Should this cluster be allowed to run privileged docker containers
KUBE_ALLOW_PRIV="–allow-privileged=false"
# Api-server endpoint used in scheduler and controller-manager
KUBE_MASTER="–master=http://k8_Master:8080"
[/js]
On Master: API Server Configuration needs to be updated on master
Copy all the certificates from existing master to the other two master(with same file permission). All the certificates are stored at /srv/kubernetes/
Now, configure API server as follows:
[js]vi /etc/kubernetes/apiserver
# Bind kube api server to this IP
KUBE_API_ADDRESS="–address=0.0.0.0"
# Port that kube api server listens to.
KUBE_API_PORT="–port=8080"
# Port kubelet listen on
KUBELET_PORT="–kubelet-port=10250"
# Address range to use for services(Work unit of Kubernetes)
KUBE_SERVICE_ADDRESSES="–service-cluster-ip-range=10.254.0.0/16"
# Add your own!
KUBE_API_ARGS=" –client-ca-file=/srv/kubernetes/ca.crt –tls-cert-file=/srv/kubernetes/server.cert –tls-private-key-file=/srv/kubernetes/server.key"
[/js]
On Master: Configure Kubernetes Controller Manager
[js]vi /etc/kubernetes/controller-manager
KUBE_CONTROLLER_MANAGER_ARGS="–root-ca-file=/srv/kubernetes/ca.crt –service-account-private-key-file=/srv/kubernetes/server.key"
[/js]
On Master and Minion: Configure Flanneld
[js]vi /etc/sysconfig/flanneld
# etcd url location. Point this to the server where etcd runs
FLANNEL_ETCD="http://k8_Master:2379"
# etcd config key. This is the configuration key that flannel queries
# For address range assignment
FLANNEL_ETCD_PREFIX="/kube-centos/network"
# Any additional options that you want to pass
FLANNEL_OPTIONS=""
[/js]
Only one master must be active at any particular time so that the cluster remains in the consistent state. For this, we need to configure Kubernetes Controller Manager and Scheduler. Start these two services with –leader-elect option.
Update their configuration file as follows:
[js]vi /etc/kubernetes/controller-manager
KUBE_CONTROLLER_MANAGER_ARGS="–root-ca-file=/srv/kubernetes/ca.crt –service-account-private-key-file=/srv/kubernetes/server.key –leader-elect"
vi /etc/kubernetes/scheduler
KUBE_SCHEDULER_ARGS="–leader-elect"
[/js]
4. Create a Load Balancer(Internal) as follows:
[js]
_____ Master1 Port 8080
|
Load Balancer Port 8080 — —- Master2 Port 8080
|
—– Master3 Port 8080
_____ Master1 Port 2379
|
Load Balancer Port 2379 — —- Master2 Port 2379
|
—– Master3 Port 2379
[/js]
5. Now Replace Master IP in /etc/hosts of all Minion by IP address of Load Balancer and restart all kubernetes service in Minions.
At this point, we are done with the master components. If we have an existing cluster, this is as simple as reconfiguring our kubelets to talk to the load-balanced endpoint, and restarting the kubelets on each node. If we are turning up a fresh cluster, we will need to install the kubelet and kube-proxy on each worker node, and set the –apiserver flag to our replicated endpoint.

Has anyone tested HA for ETCD? I asked this because I’m planning to put it into production.
Could anyone elaborately explain how to set up a load balancer, Currently I am testing HA setup in local vagrant environment.
You can easily set up HAproxy on different machine, you need only 2 cores, 1GB RAM and 5 minutes for reading tutorial.
Can anyone elaborate how to set up Load Balancer, currently I am testing the HA setup locally, with vm’s created by vagrant
I have followed the steps as give. I have setup 3 masters, however i am able to start ETCD only on 1 server. On the other two servers(infra1 and infra2) i am getting below error message:
————————–
–initial-cluster must include infra2=http://localhost:2380 given –initial-advertise-peer-urls=http://localhost:2380
May 22 13:50:23 ha-master-03 etcd[2276]: forgot to set –initial-advertise-peer-urls flag?
———————————
I have checked the etcd config several times, there are no issues with them. Would you happen to know what could be the issue?
Sajeesh, I had the same issue. Looks like we have to make two changes to the etcd.conf:
1) ETCD_LISTEN_CLIENT_URLS=”http://172.16.0.1:2379,http://127.0.0.1:2379”
(Note the comma , rather than the period . )
2) ETCD_INITIAL_ADVERTISE_PEER_URLS=”http://172.16.0.1:2380″
(Replace 172.23.0.1 with the IP of each node)
Run systemctl restart etcd on each master again.