
Scope of Testing in Big Data and Hadoop
We have entered into a digital world where data is scaling every single second. Every digital process and social media platform produce it. Systems, sensors, and mobile devices convey it. The amount of data that’s being created and stored globally is almost inconceivable, and it just keeps on multiplying and multiplying.
Is all the data Big Data?
NO
So what is Big Data?
Big Data is defined and characterized by 3Vs
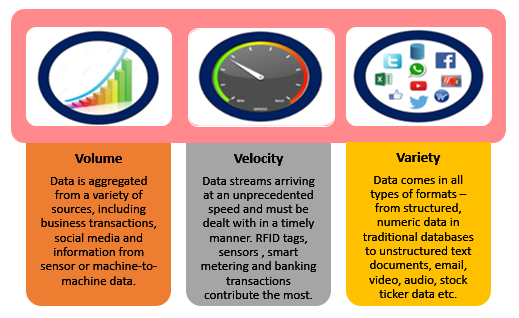
Fig 1: 3Vs of Big Data
“Data which is generated in extremely large quantity (PB/XB) from single/multiple sources at very high pace is termed as Big Data.”
A big problem that crops up with Big Data is its storage, so to overcome this problem we have a sophisticated framework called ‘Hadoop.’
According to Chuck Lam’s “Hadoop in Action”,
“Hadoop is an open source framework for writing and running distributed applications that process large amounts of data.”
Testing Aspects in Big Data:
When we have storage and processing of huge amount of data then there is a definite requirement of thorough testing to eject the ‘Bad Data’ from ‘Big Data’, establish a stable environment and various other aspects discussed as follows:
1. Validation of Structured and Unstructured Data: Data needs to be classified as the structured and unstructured parts.
(i) Structured Data: It is the data which can be stored in the form of tables (rows and columns) without any processing for example database, call details and excel sheets.
(ii) Unstructured Data: It is the data which does not have a predefined data model or structure for example data in the form of weblogs, audio, tweets, and comments.
Adequate time needs to be spent over the validation of the data at an initial stage, and it is the point where we encounter an abundance of bad data from various sources.
2. Ace Test Environment: Efficient test environment ensures that data from multiple sources is of acceptable quality for accurate analysis. Although replicating the complete set of big data into the test environment is next to impossible, so a small subset of the data is created for the test environment to verify the behavior. Careful planning is required to exercise all paths with subsets of data in a manner that fully verifies the application.
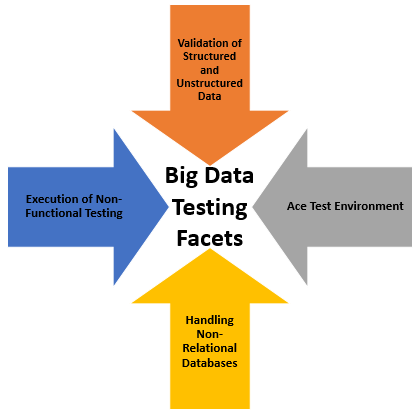
Fig 2: Testing aspects in Big Data
3. Handling Non-Relational Databases: Non-Relational databases form the backbone of the Big Data storage. Since these are the main sources of data retrieval hence require a good portion of testing to maintain the accuracy of the system. Commonly known as NoSQL databases, these DBs are designed in such a manner that they can early handle the Big Data and are different from the traditional RDBMS which are designed on table/key model.
4. Execution of Non-Functional Testing: Non-functional testing plays a vital role in ensuring the scalability of the process. Functional testing focuses on the coding and requirement related issues whereas non-functional testing classifies the performance bottlenecks and validates the non-functional requirements.
Phases of testing in Big data and Hadoop:
Testing of Big Data and Hadoop is an enormous and complex process which is segregated into four phases to squeeze out the best results from testing.These phases are as follows:
1. Pre-Hadoop Processing: It includes the validation of the data which is collated from various sources before Hadoop processing. This is the phase where we get rid of unwanted data.
2. Processing of Map Reduce Job: Map R job in Hadoop is the java code which is used to fetch out the data according to the preconditions provided. Verification of the Map Reduce job is performed to monitor the accuracy of the data fetched.
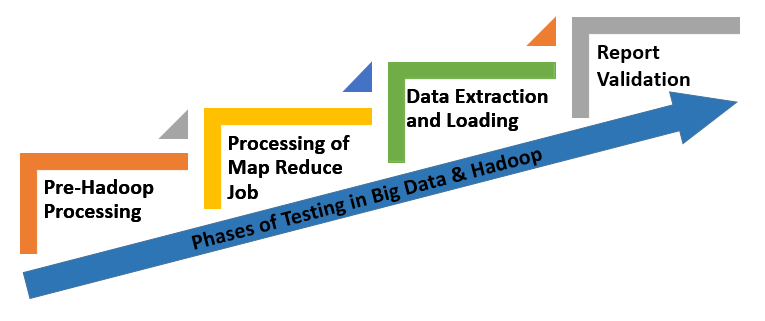
Fig 3: Phases of testing in Big Data and Hadoop
3. Data Extraction and Loading: This process of includes the validation of the data being loaded and extracted from the HDFS (Hadoop Distributed File System) to ensure that no corrupt data occupied in the HDFS.
4. Report Validation: This is the last phase of testing to ensure that the output which we are delivering is meeting the accuracy standards, and there is no redundant data present in the reports.
As of today, most of the IT companies are racing to implement Big Data and Hadoop. A concrete understanding of concepts and hands-on experience will eventually help out in exploring the new verticals of testing in Big Data and Hadoop.
Hope the information provides you an initial insight into the scope of testing in this technology. There is more to come about the testing techniques, understanding a use case, challenges in testing and the approach to overcome those challenges in my upcoming blog.
So stay glued for more updates.

With its real-time graphical presentation and reporting it facilities the team to take a critical decision and corrective actions to minimize and manage costs.
I‘d mention that most of us visitors are endowed to exist in a fabulous place with very many wonderful individuals with very helpful things.
I am planning to learn big data testing, Could you please let me know the future scope and what is the market position for big data testing.
Thanks
There are many aspects of big data that are different than simple application data scenarios. Just the scale is important, of course and both load-time and run-time performance are critical factors. And it’s not just performance — sometimes it’s a question whether loads or queries will run at all — do they run out of resources?
Informative
Very informative, I have always been wondering what role does testing play in big data,hadoop !
Thanks for the post.. It is very helpful.