
Spark 1O3 – Understanding Spark Internals
In this post, I will present a technical “deep-dive” into Spark internals, including RDD and Shared Variables. If you want to know more about Spark and Spark setup in a single node, please refer previous post of Spark series, including Spark 1O1 and Spark 1O2.
Resilient Distributed Datasets (RDD) – An RDD in is primary abstraction in Spark – a fault-tolerant, immutable distributed collection of objects that can be operated on in parallel. In Spark all work is expressed as either creating new RDDs, transforming existing RDDs, or calling operations on RDDs to compute a result. Under the hood, Spark automatically split data into multiple partitions and distributes the data contained in RDDs across your cluster.
How to create RDD – Spark provides two ways to create RDD, loading an external dataset or parallelizing a collection in your driver program.
[java]
//Create Java Spark Context object
JavaSparkContext sc = new JavaSparkContext();
//Using Spark Context, parallelize existing collection
JavaRDD<String> lines = sc.parallelize(Arrays.asList("pandas", "i like pandas"));
//Using Spark Context, load external storage
JavaRDD<String> lines = sc.textFile("/path/to/README.md");
[/java]
RDD Operations – RDDs support two types of operations: transformations and actions. Transformations are operations on RDDs such as map() and filter() which return a new RDD. Actions are operations which return a result to the driver program or write it to storage, and kick off a computation, such as count() and first().
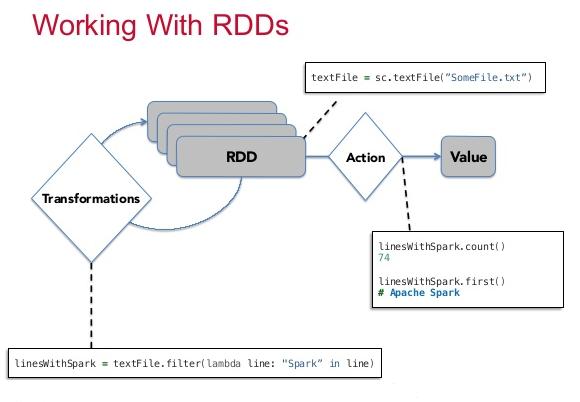
Transformations – Transformations are operations on RDDs that return a new RDD. Although you can define new RDDs any time, Spark computes them only in a lazy fashion. In “Lazy Evaluation”, transformed RDDs are computed lazily, only when you use them in an action.
[java]
//Create RDD from loading external file.
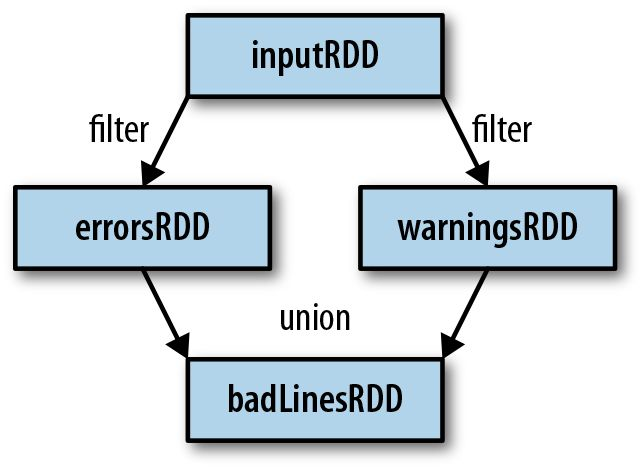
JavaRDD<String> inputRDD = sc.textFile("log.txt");
//Filter object from existing RDD and get a new RDD
JavaRDD<String> errorsRDD = inputRDD.filter( l -> x.contains("error"));
[/java]
Note that the filter() operation does not mutate the existing inputRDD. Instead, it returns a pointer to an entirely new RDD. inputRDD can still be reused later in the program — for instance, to search for other words.
Finally, as you derive new RDDs from each other using transformations, Spark keeps track of the set of dependencies between different RDDs, called the lineage graph. It uses this information to compute each RDD on demand and to recover lost data if part of a persistent RDD is lost.
Actions – We’ve seen how to create RDDs from each other with transformations, but at some point, we’ll want to actually do something with our dataset. Actions are the second type of RDD operation. They are the operations that return a final value to the driver program or write data to an external storage system. Actions force the evaluation of the transformations required for the RDD they were called on, since they need to actually produce output.
[java]
//Count total number of element in RDD
long count = errorsRDD.count();
//Get top 10 element from RDD
List<String> top10 = errorsRDD.top(10);
[/java]
Shared Variables – In Spark Tasks are executed on a remote cluster node, it works on separate copies of all the variables used in the function. These variables are copied to each machine, and no updates to the variables on the remote machine are propagated back to the driver program. Spark does provide two limited types of shared variables for two common usage patterns: broadcast variables and accumulators.
Broadcast Variables – Broadcast variables let programmer keep a read-only variable cached on each machine rather than shipping a copy of it with tasks. Spark also attempts to distribute broadcast variables using efficient broadcast algorithms to reduce communication cost. For example, to give every node a copy of a large input dataset efficiently.
[java]
List<Long> array = Arrays.asList(1L, 2L, 3L);
//In this case array will be shipped with closure each time
rdd.map(i -> array.contains(i));
//Broadcast array to all nodes using Spark Context Object
//use the broadcast object for operations
Broadcast<List<Long>> broadcasted = sc.broadcast(array);
rdd.map(i -> broadcasted.value.contains(i));
[/java]
Accumulators – Accumulators are variables that can only be “added” to through an associative operation. Used to implement counters and sums, efficiently in parallel. Spark natively supports accumulators of numeric value types and standard mutable collections, and programmers can extend for new types. Only the driver program can read an accumulator’s value, not the task.
