Apache Flume is an open source project aimed at providing a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large volume of data. It is a complex task when moving data in large volume. We try to minimize the latency in transfer; this is achieved by specifically tweaking the configuration of Flume. First, we’ll see how to setup flume.
Setting Up Flume :
- Download flume binary from http://flume.apache.org/download.html
- Extract and put the binary folder in globally accessible place. For e.g. /usr/local/flume (Use “tar -xvf apache-flume-1.5.2-bin.tar.gz” and “mv apache-flume-1.5.2-bin /usr/local/flume”)
- Once done, set the global variables in the “.bashrc” file of the user accessing Flume.
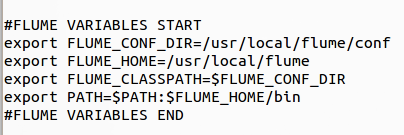
- Use “source .bashrc” to set the new variables in effect. Test by running command “flume-ng version”.
- Once the command shows the right version, Flume is set to work on the current system. Please note “flume-ng” represents, “Flume Next-Gen“
Flume Agent is the one which takes care of the whole process of taking data from “source“, putting it on to the “channel“, and finally dumping it in the “sink“. “Sink” usually is HDFS.
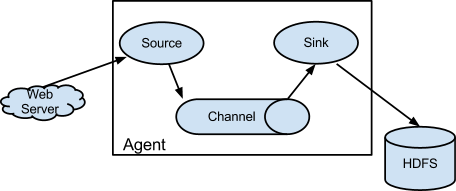
Basic Configuration :
Apache Flume takes a configuration file every time it runs a task. This task is kept alive in order to listen to any change in the source, and must be terminated manually by the user. A basic configuration to read data taking “local file system” as the source, keeping channel as “memory“, and “hdfs” as sink, could be:
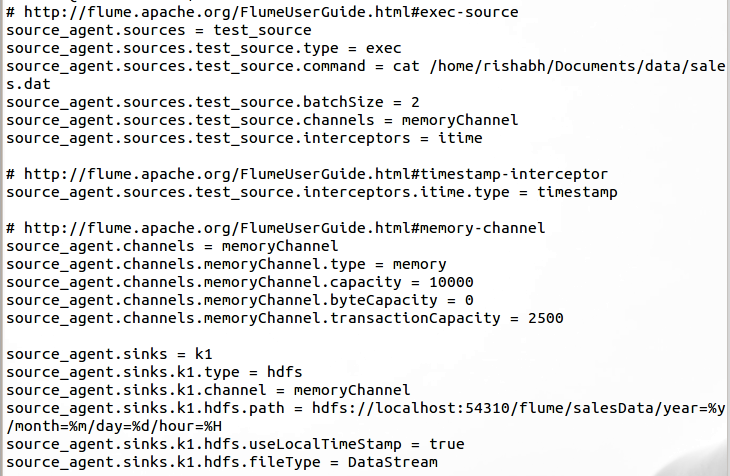
Sources could be anything like an Avro Client being used by Log4JAppender as well.
It is worth noting, the above given configuration will produce separate files of 10 records each by default, taking timestamp ( an interceptor ) as the point of reference of last update of the source.
The file so created be saved as flume.conf, and can be run as :
flume-ng agent -f flume.conf -n source_agent
Performance Measures, Issues and Comments:
- Memory leaks in log4jappender when ingesting just 10000 records.
- Solved by making thread sleep after every 500 records, thus decreasing the load on the channel
- GC Memory Leak (Flume level)
- Solved by keeping transactionCapacity of channel low and capacity of channel high enough
- Avro’s Optimized data serialization is not expolited when using log4jappender
- Solved by directly pushing the file onto avro-client (inbuilt in flume-ng)
- Due to memory leaks, could not write more than 12000 records from log4jappender
- Solved in points 1 & 2
- Did performance analysis of data ingestion directly from file as well as avro client of 14000 records when only 10 records rolled up per file in HDFS
- Using Avro Client –> Total time – 00:02:48
- Directly from File System –> Total time – 00:02:44
- When using avro client, realtime update to the file was not taken into account
- Unsolved problem
- When ingesting directly from file, realtime updates were automatically registered, on the basis of timestamp for last modification
- Used the following configuration
source_agent.sources.test_source.interceptors = itime
# http://flume.apache.org/FlumeUserGuide.html#timestamp-interceptor
source_agent.sources.test_source.interceptors.itime.type = timestamp
- Used the following configuration
- Flume could only create files to write at max 10 records in a single file by default. This decreased the ingestion rate, thus increasing the ingestion time
- Solved by changing the rollCount property of the HDFSSink to the desired number of events/records per file; this increased the ingestion rate, thus decreasing the ingestion time.
- Also made rollSize and rollInterval as 0, so that they are not used.
- While controlling the channel capacity, encountered Memory Leaks
- Solved by changing the rollCount(HDFSSink) and transactionCapacity(channel) so that the channel is cleared for more data
- Did performance analysis of data ingestion directly from file after applying solutions from 8 & 9 of 20000 records
- Total time – 00:00:04 (Previously around 00:02:30)
- How to trigger notification on HDFS update from flume
- Can be potentially solved by Oozie Coordinator
This covers the very basics of setting up Flume and mitigating some of the common issues which one encounters while using it.