In any user facing and real time application, data is of utmost importance as it directly affects any business’s market and revenue. Recently, we were needed to build an OTA for booking hotels; wherein User may book hotel rooms for specific dates. For this, we integrated with multiple Suppliers for fetching hotel information which resulted in a massive amount of data both from internal and external sources. We needed to process the data to add context, relevance and purpose and also show relevant data to end user along with performance being the top most priority.
Consider the case of searching for available hotel rooms. This is something that needs to be kept updated almost every second given the nature of the industry. With the fast changing nature of hotel’s availability, storing and retrieving data from an internal database would more often give stale results.
We were required to search multiple external data sources for availability data based on User’s search criteria (check-in/check-out date, number of rooms, occupancy in each room, etc.) at real-time. Also, aggregate and deduplicate similar results from different sources along with conversion/serialization according to system’s need and then serve it back to the end user. Phew !!
Then also there would be times when we wanted to split the same user request into multiple batches to execute against the same data source/endpoint for different payloads.
If the above was too trippy for you, the below points could provide more insights
- Fetching Data at Runtime from External Sources: Availability data had to be fetched through runtime APIs from the Supplier based on User’s search criteria. This was also essential since storing Supplier Availability Data for different search parameters (check-in/check-out dates, number of rooms, occupancy in each room) in our DBs would have been a cumbersome operation.
- Aggregation and De-duplication: While fetching data from multiple Suppliers, there is a high probability of duplicate data being received from multiple Suppliers (same hotels/same rooms for a single hotel). Therefore, we had to perform deduplication, wherein business logic was applied to remove duplicate data and add relevance to it as per User satisfaction.
- Converters and Serializers: Given the multitude of sources, we would be pulling data from the number of formats that need to be understood, converted and massaged increase considerably. Each source can have their own data definition and response format which might not be universal.
Keep in mind, all of this need to be done within the context of a delightful user experience flow, i.e., nothing that takes more than 500 ms.
After much analysis of different routing frameworks and plug and play ESB solutions, we settled in with Apache Camel.
Apache Camel™ is one of the most popular Enterprise Integration Patterns that allows conditional routing in any of defined domain-specific languages, be it Java, XML or Scala. A Route is a URI that contains flow and integration logic using a specific DSL.
Now let’s look at the above cases and how Apache Camel would be able to provide easy out of the box techniques to achieve them. If you take the above-explained scenario of real time user search, we can take the below figure as a solution for how we can break the problem into smaller parts – aka split() and multicast()
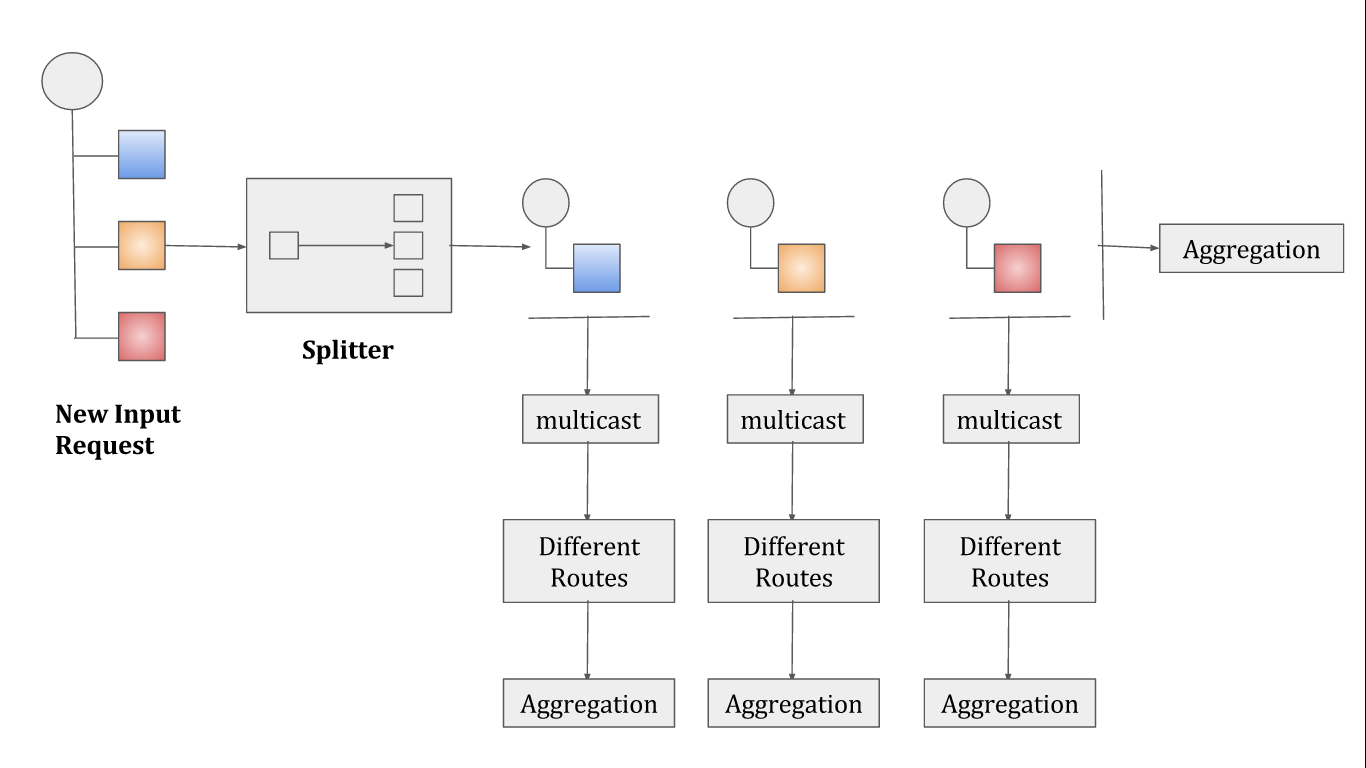
Part 1 ( Splitter )
Here, we have a URI (can be an API endpoint / a bean method, etc.), that takes a particular input parameter and we wish to call the URI with different input parameters parallelly and then aggregate the result.
If we have a list of InputRequest objects and we wish to call “prepareOutput” method with each of them parallelly and then return a list of “OutputObjects”, we can use the split functionality of Camel.
Using Java DSL to perform split as follows:
[code language=”java”]
RouteBuilder builder = new RouteBuilder() {
public void configure() throws Exception {
from(‘direct:splitAsyncStart’)
.split(body(), new SplitAggregationClass()).parallelProcessing(true)
.to(‘direct:processInputRequest’).end();
from(‘direct:processInputRequest’)
.bean(InputProcessor.class);
}
}
[/code]
In above JAVA DSL, whenever the endpoint direct:splitAsyncStart is called with payload as a List of “InputRequest” objects, they are split and sent to direct:processInputRequest endpoint as individuals. Response for each of them can be aggregated in the Aggregation class specified (SplitAggregationClass).
[code language=”java”]
public class SplitAggregationClass implements AggregationStrategy {
public Exchange aggregate(Exchange exchange, Exchange exchange1) {
try {
String concatenatedString = ”;
OutputResponse outputResponse = exchange1.getIn().getBody(OutputResponse.class);
int splitIndex = exchange1.getProperty(‘CamelSplitIndex’, int.class);
if (exchange != null) {
concatenatedString = exchange.getIn().getBody(String.class);
concatenatedString += ‘ ‘ + outputResponse.getInputRequest().getName();
} else {
exchange = exchange1;
concatenatedString += ‘Hello! ‘ + outputResponse.getInputRequest().getName();
}
System.out.println(‘Split Index : ‘ + splitIndex + ‘ in Aggregation class with Response : ‘ + outputResponse);
exchange.getIn().setBody(concatenatedString);
} catch (Exception e) {
System.out.println(‘Exception occurred while performing Aggregation’);
}
return exchange;
}
}
[/code]
Part 2 ( Multicast )
Here we have two or more different URIs that need to be hit with the same payload but probably with different request formats. To achieve this, we can use the multicast functionality of Camel. Multicast allows to route the same message to a number of endpoints and processes them in different ways.
Let us illustrate following JAVA DSL :
[code language=”java”]
RouteBuilder builder = new RouteBuilder() {
public void configure() throws Exception {
// Multicast Route Configurations
from(‘direct:multicastAsyncStart’)
.multicast().parallelProcessing(true).aggregationStrategy(new MultiCastAggregationClass())
.to(‘direct:multicastRoute1’)
.to(‘direct:multicastRoute2’)
.to(‘direct:multicastRoute3’)
.end();
from(‘direct:multicastRoute1’)
.bean(MulticastProcessing.class, ‘route1’);
from(‘direct:multicastRoute2’)
.bean(MulticastProcessing.class, ‘route2’);
from(‘direct:multicastRoute3’)
.bean(MulticastProcessing.class, ‘route3’);
}
}
[/code]
In the above example, whenever the point direct:multicastAsyncStart is hit, the same payload is sent to 3 different endpoints (here direct:multicastRoute1, direct:multicastRoute2 and direct:multicastRoute3). The response from all is then aggregated in the aggregation class MultiCastAggregationClass.
[code language=”java”]
public class MultiCastAggregationClass implements AggregationStrategy {
public Exchange aggregate(Exchange exchange, Exchange exchange1) {
if (exchange == null) {
return exchange1;
} else {
String oldExchangeText = exchange.getIn().getBody(String.class);
oldExchangeText += ‘ ‘ + exchange1.getIn().getBody(String.class);
exchange.getIn().setBody(oldExchangeText, String.class);
return exchange;
}
}
}
[/code]
To conclude, we can say that Apache Camel has many advantages over traditional ways of achieving parallel processing, both in terms of code complexity and management. It provides us a structured approach taking care of the semantics and overheads of parallelization and aggregation.
You can also go through a demo application which I had created for illustration of the above-explained strategies – git@github.com:manali14/camelAsyncDemo.git
Hope it helps 🙂