In the last blog we had a brief introduction to machine learning. We also took a shallow dive in classification problem in machine learning. If you have not read the previous blog, you can read it from here.
Here, we will discuss how do we solve classification problem. We will use k-Nearest Neighbor algorithm (one of the machine learning technique for solving classification problem) to solve the problem of classifying an non-annotated image of either “cat” or “dog”.
In the last blog, we were trying to figure out how to make an algorithm that will take an annotated set of observations and predict the class for an unknown observation. We are going to make an assumption to make things simpler for us. We assume that an image can be represented by a feature vector (x1, y1) as shown below:
Cats : (1,3), (2,1), (2,2),(2,3),(2,4),(3,2)
Dogs : (3,4), (3,5), (4,3),(5,3),(5,5),(6,4)
This mapping is called as feature extraction. We will understand feature extraction in later blogs. Now if we put cats and dogs on a two dimensional plane, it would look as shown in Figure 1.
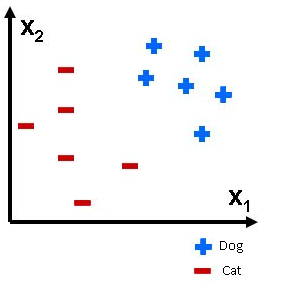
Figure 1: Dataset1
Now we are given a new example and asked to find if it is a cat or a dog. Look at the Figure 2 and see if you can find out if “?” it is a cat or dog.
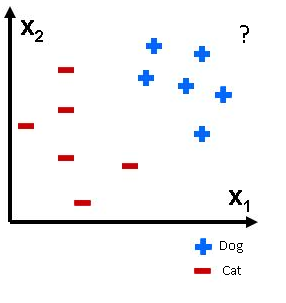
Figure 2 : Find class of?
Yes! You figured out correctly. It’s a dog. Let’s now train our computers to figure it out. One solution to this problem is 1- nearest neighbour. It states that an unknown observation can be classified to same class as its nearest neighbour. To determine the nearest neighbour, we will find the distance of unknown observation “?” with all the other known observations and later assign the class label to unknown observation depending on the nearest neighbour. The coordinates of unknown observation be (6,6). We will be calculating the Euclidean distance between the observations. The Euclidean distance between two points (x1, y1) and (x2, y2) is calculated as : D= ![]()
| Class | X1 | Y1 | Distance from (6,6) |
| Cat | 1 | 3 | 5.8 |
| Cat | 2 | 1 | 6.4 |
| Cat | 2 | 2 | 5.6 |
| Cat | 2 | 3 | 5 |
| Cat | 2 | 4 | 4.4 |
| Cat | 3 | 2 | 5 |
| Dog | 3 | 4 | 3.6 |
| Dog | 3 | 5 | 3.1 |
| Dog | 4 | 3 | 3.6 |
| Dog | 5 | 3 | 3.1 |
| Dog | 5 | 5 | 1.4 |
| Dog | 6 | 4 | 2 |
The nearest observation is (5, 5) which belongs to “Dog” class. Thus we can infer that unknown observation is actually “Dog” class.
It has been observed that 1-nearest neighbor sometimes fail due to various reasons such as noise in input data. A simple modification to same algorithm makes it more robust to any such problems. The solution is instead of taking 1-nearest neighbor, k-nearest neighbors are taken. Among these k-neighbours, majority voting is done to determine the class of unknown observation. The time complexity of k-nearest neighbors algorithm is O(mn), where n is number of example in annotated dataset and m is number of examples with unknown class.
In the above example, we provided our computer a sufficient amount of training data with all the training set classified correctly and then asked our computer to infer the class of an non-annotated input with its experience of annotated data. This is an example of supervised learning. Email Spam filter, Digit Recognition are some example of supervised learning. However, we might get a training data without a desired output label. Here the problem is much harder because in this the goal is to make a computer learn how to do something that we don’t tell it how to do!!
We will discuss them in detail in later blogs.
Footnotes
1 “CIS520 Machine Learning | Lectures / Classification BrowseTitle.” 2015. 30 May. 2016
Great article. Will you be sharing code samples as well?
Can you please share some resources where we may learn further ourselves?