
Apache Solr 5.1.0
Apache Solr is an open source search platform built upon a Java library called Lucene.
Solr is a popular search platform for Web sites because it can index and search multiple sites and return recommendations for related content based on the search query’s taxonomy. Solr is also a popular search platform for enterprise search because it can be used to index and search documents and email attachments.
Solr works with Hypertext Transfer Protocol (HTTP) Extensible Markup Language (XML). It offers application program interfaces (APIs) for Javascript Object Notation (JSON), Python, and Ruby. According to the Apache Lucene Project, Solr offers capabilities that have made it popular with administrators including:
Advanced Full-Text Search Capabilities
Optimized for High Volume Web Traffic
Standards Based Open Interfaces – XML, JSON and HTTP
Comprehensive HTML Administration Interfaces
Server statistics exposed over JMX for monitoring
Linearly scalable, auto index replication, auto failover and recovery
Near Real-time indexing
Flexible and Adaptable with XML configuration
Extensible Plugin Architecture
Overview
In this blog of Apache Solr ,we will show you how to install the latest version of Apache Solr 5.1.0 configuration and perform the index using a data file. Apache Solr supports indexing from different source formats including various databases, PDF files, XML files, CSV files etc.
We will look how to index basic data from a CSV file by using apache solr.
There is recent changes in directory structure of solr from previous versions solr 4.x for reference follow link.
[js]https://lucene.apache.org/solr/5_0_0/changes/Changes.html#v5.0.0.upgrading_from_solr_4.x[/js]
Download the Apache solr latest version from below link on your system:
[js]wget http://apache.mirrors.ionfish.org/lucene/solr/5.1.0/solr-5.1.0.zip[/js]
[js]unzip solr-5.1.0.zip[/js]
[js]cd solr-5.1.0[/js]
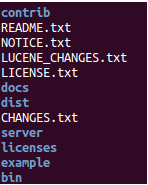
Apache solr directory Structure Overview:
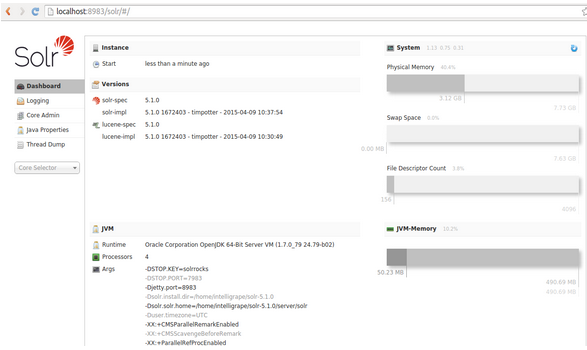
Start Solr
[js]bin/solr start -p 8983[/js]
-p specifies port number (by default port number 8983)
Core Creation
When the Solr server is started in Standalone mode the configuration is called core and when it is started in SolrCloud mode the configuration is called Collection. In this we will discuss about the standalone server and core.
SolrCloud Collection mode
solr create_collection [-c collection] [-d confdir] [-n configName] [-shards #] [-replicationFactor #] [-p port]
Standalone Mode
solr create_core [-c core] [-d confdir] [-p port]
[js]bin/solr create_core -c power1 -d sample_techproducts_configs -p 8983[/js]
This will create core power1 for solr running on port 8983 with example configuration with many optional features enabled to demonstrate the full power of Solr.
Now all your cores created <ApacheSolr_Home>/server/solr/ folder.(like i have created power1)
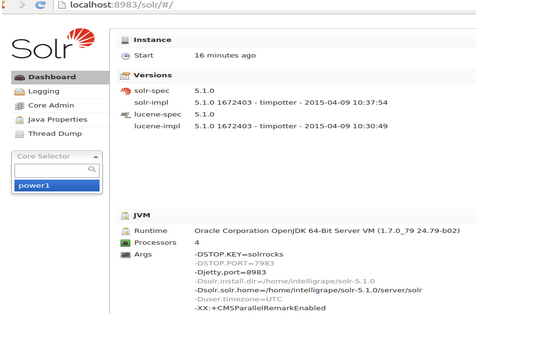
As you see in below screenshot Core power1 has been created when you select the Core Selector.
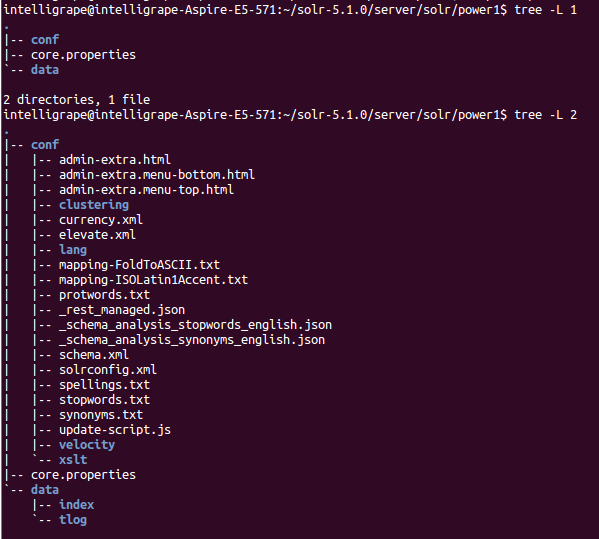
Core Power1 Directory structure
Create the Sample CSV File to index and save it as testing.csv
Content of testing.csv

[js]cat,_version_,price_c,series_t,id,author,rank,price,sequence_i,name,author_s,inStock,genre_s
book,1503669092110827520,&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;7.99\,USD&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;,A Song of Ice and Fire,0553573403,George R.R. Martin,1.2,7.99,1,A Game of Thrones,George R.R. Martin,true,fantasy
book,1503669092137041920,&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;7.99\,USD&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;,A Song of Ice and Fire,0553579908,George R.R. Martin,2.3,7.99,2,A Clash of Kings,George R.R. Martin,true,fantasy
book,1503667880901738496,&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;17.99\,USD&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;,Foundation Novels,0553293354,Isaac Asimov,,17.99,1,Adobe_ttn,Isaac Asimov,true,scifi
book,1503667880903835648,&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;6.99\,USD&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;,the Chronicles of Amber,0380014300,Roger Zelazny,,6.99,1,Nine Princes In Amber,Roger Zelazny,true,fantasy
book,1503667880904884224,&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;5.99\,USD&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;,The Chronicles of Prydain,080508049X,Lloyd Alexander,,5.99,2,The Black Cauldron,Lloyd Alexander,true,fantasy
book,1503667880905932800,&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;15.03\,USD&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;,The Chronicles of Prydain,080508056X,Ankit,,15.03,2,The Black Cauldron,Ankit,true,fantasy
book,1503667880906981376,&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;16.99\,USD&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;quot;,snapper,0812550706,Orson Scott Card,,16.99,1,snapper_ttn,Orson Scott Card,true,scifi[/js]
Schema.xml
It is usually the first file you configure when setting up a new Solr installation.
The schema declares:
- what kinds of fields there are
- which field should be used as the unique/primary key
- which fields are required
- how to index and search each field
Now we need to make change in schema.xml (server\solr\power1\conf) which provide by default by solr while using the sample_techproducts_configs (Example configuration with many optional features enabled to demonstrate the full power of Solr) as per the our content in file testing.csv put on solr for indexing.We define the field which we are going to use in our testing.csv.
Edit the schema.xml file in the \server\solr\power1\conf folder and add the following contents after the uniqueKey element.
<field name=”name” type=”text_general” indexed=”true” stored=”true”/>
<field name=”cat” type=”string” indexed=”true” stored=”true” multiValued=”true”/>
<field name=”price” type=”float” indexed=”true” stored=”true”/>
<field name=”inStock” type=”boolean” indexed=”true” stored=”true” />
<field name=”store” type=”location” indexed=”true” stored=”true”/>
<field name=”rank” type=”float” indexed=”true” stored=”true”/>
<field name=”title” type=”text_general” indexed=”true” stored=”true” multiValued=”true”/>
<field name=”subject” type=”text_general” indexed=”true” stored=”true”/>
<field name=”author” type=”text_general” indexed=”true” stored=”true”/>
<field name=”keywords” type=”text_general” indexed=”true” stored=”true”/>
<field name=”category” type=”text_general” indexed=”true” stored=”true”/>
<dynamicField name=”*_t” type=”text_general” indexed=”true” stored=”true”/>
<dynamicField name=”*_s” type=”text_general” indexed=”true” stored=”true”/>
Note: As we are using sample_techproducts_configs so field name and dynamic Field already present in schema.xml we need to check it before adding line in schema.xml.
Repetition will throw error at the time of indexing.
Attribute indexed to true. This specifies the field is used for indexing and the record can be retrieved using the index. Setting the value to false will make the field only stored but can’t be queried with.Another attribute called stored and set it to true. This specifies the field is stored and can be returned in the output. Setting this field to false will make the field only indexed and can’t be retrieved in output.
For Indexing in solr please reference the below link
[js]http://www.solrtutorial.com/basic-solr-concepts.html[/js]
After changes in schema.xml restart the solr
[js]bin/solr restart -p 8983[/js]
Indexing the content
Solr includes a simple command line tool for POSTing various types of content to a Solr server. The tool is bin/post. The bin/post tool is a Unix shell script
[js]bin/post -c power1 testing.csv -p 8983[/js]
bin/post -c core_name <file_name_to_index> -p <Port_number>
For more details use bin/post -help
Search Indexed File
Search the indexed by using the schema browser option available on apache solr dashboard.
Select the required field name for result.
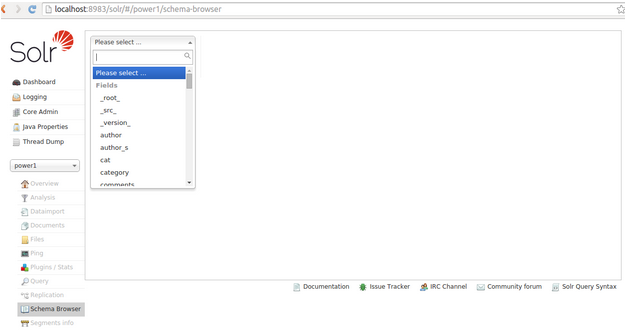
We selected the author field to fetch the required details from solr
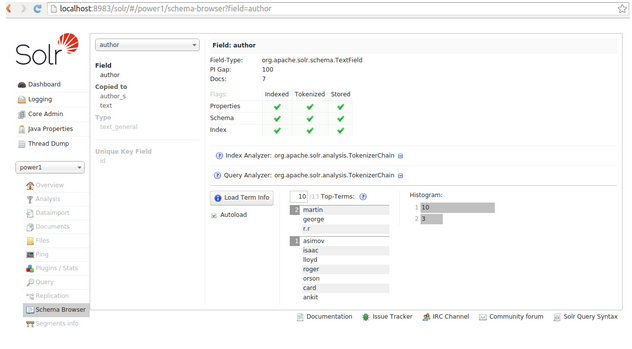
Select required author available in author field name to get the details
i.e we have selected author ankit to get respective details
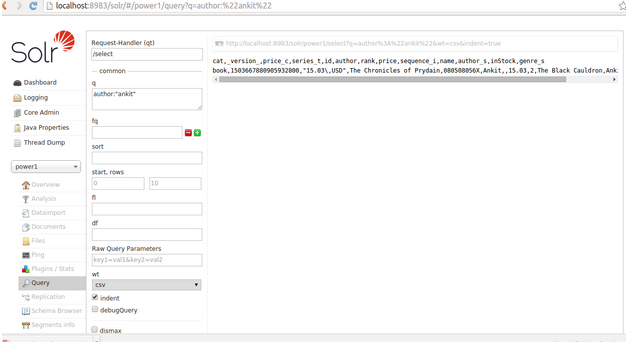
We have option available to view data in different format json,xml,csv etc.


