In modern user facing and real-time applications, performance is the top concern with usually having data at its core. What if you were able to offload some work from the database and at the same time increase the performance and response times of your application?
Most of the time data handling is done by relational databases which provide access to data. Applications talk directly to the database which at times can have a hot-swappable backup machine. In most cases, the only solution to increase the application performance is to scale it vertically, i.e, increase more RAM, add more CPU power, etc. and that comes at a cost.
What is Software Caching?
In computing, a cache is a hardware or software component that stores data for server future data requests faster. The data stored in a cache can be the result of an earlier computation, or the duplicate of data stored elsewhere.
Why it is needed?
We all are aware of the cache used by CPU/hardware that helps to process faster. What if this concept can be taken to the application/software level. This is where Caching helps.
There are practices prevalent in the industry to use such kind of solutions in many forms, they may be known as key-value stores (Redis, etc.), in-memory databases (Gridgain, etc.) and many more. In fact, one type of software cache that we all might have used someday is Hibernate’s second level caching.
How Caching is done?
Below are few possibilities of handling such scenarios at an architectural level:
1. You would either let the application consult the cache first for data and if it is a miss, then the same application consults the backing store for the data. A schematic diagram is shown below.
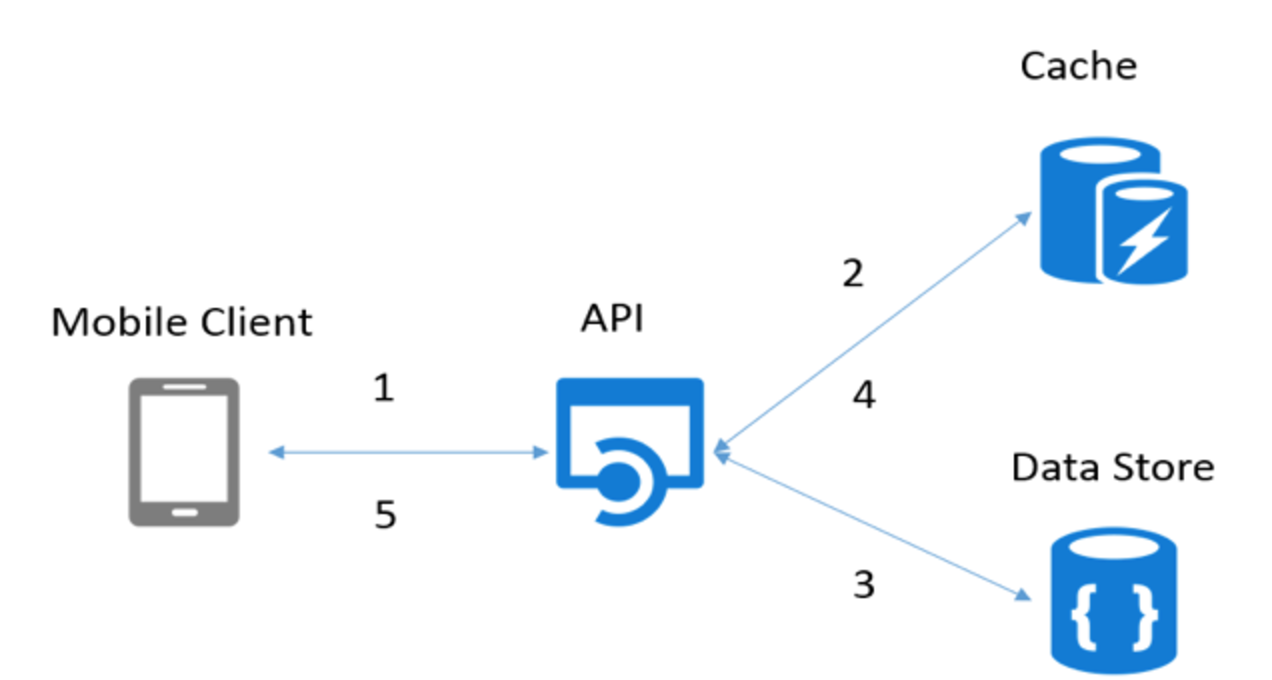
2. Or else, you would take that functionality out from the application into a separate application/process and the application will transparently get data from the 3rd application which will be responsible for fetching data from cache/database and keeping the cache in sync with the backing store. This particular approach is termed as Read-Through/Write-Through approach. Refer Diagram below.
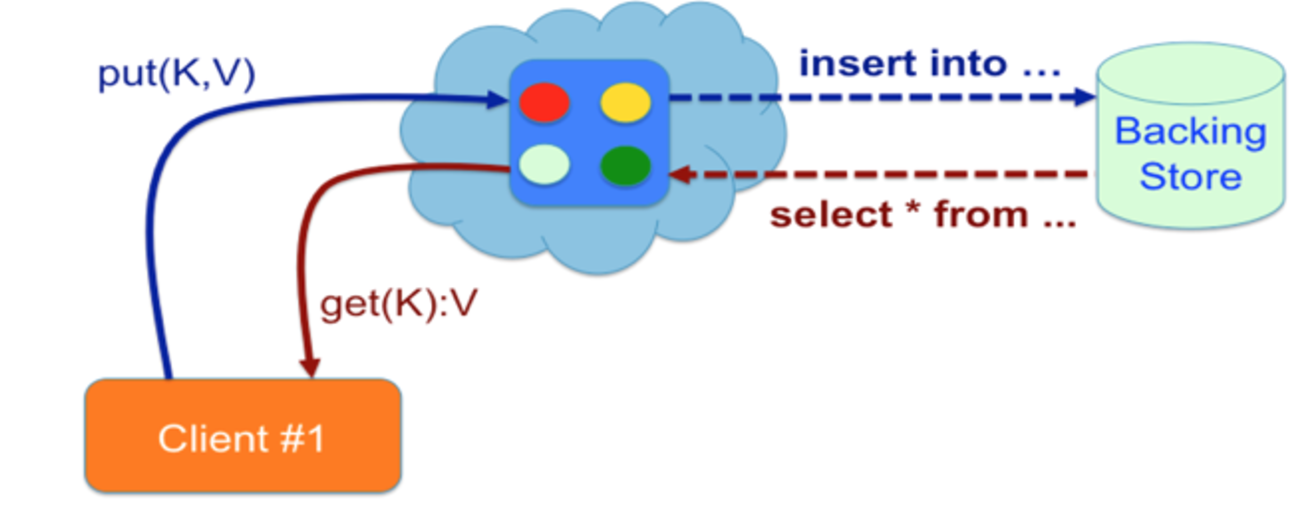
The first approach fails when the database is saturated, or the application performs mostly the “put” operations (writes). Further, this approach is of no use because it offloads the database only from the “get” loads (reads). Even if the applications are read-intensive, there can be consistency problems in case if data changes. This is when concepts like time-to-live (TTL) or write-through comes in.
Also, in the case of TTL, if the access is less frequent than the TTL value, the result will always be a cache miss.
Above discussion/concerns regarding caching can be summarized as under:
- Memory size
- Synchronization complexity:
- Consistency between the cached data state and data source’s original data
- Maintaining consistency in multiple nodes where data is replicated
- Durability :
- Eviction Policy. E.g: LRU, LFU, FIFO
- Eviction Percentage
- Expiration. E.g TTL
Cache Types:
- Local Cache: It is local to particular application server
- Pros:
- Simplicity
- Performance
- No serialisation / deserialisation overhead
- Cons:
- Not a fault-tolerant
- Scalability
- Pros:
- Replicated cache: It replicates all its data to all cluster nodes
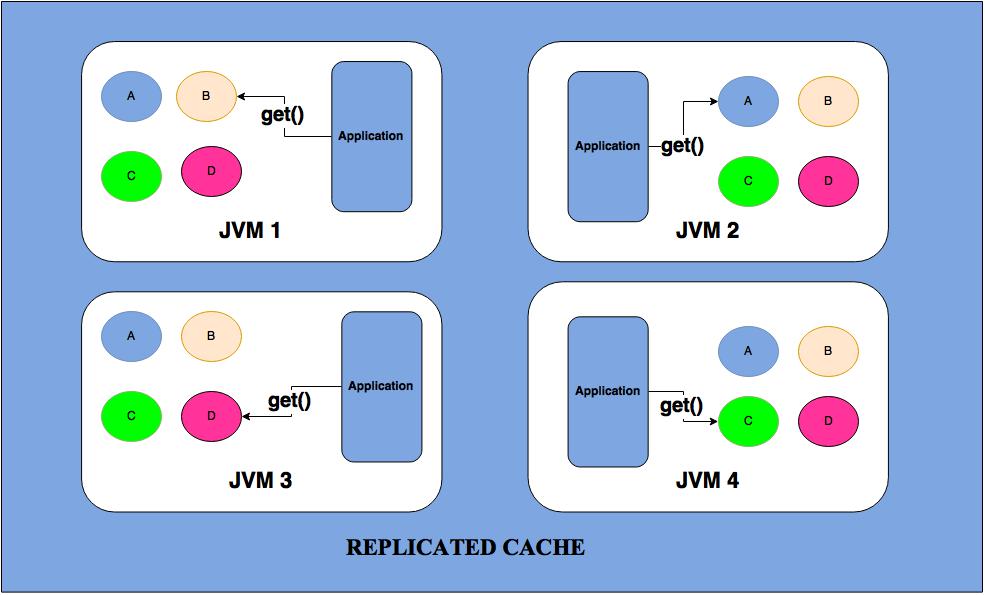
- Data Operation:
Get: As the picture states each cluster node access the data from its own memory, i.e Local read
Put: Pushing the version of data to all cluster node
- Pros:
- Best for read operation
- Fault-tolerant
- Cons:
- Poor write performance
- Additional network load
- Memory consumption
4) Distributed Cache: It partitions its data among all cluster nodes. The data is being sent to a primary cluster node and a backup cluster node if the backup count is 1.
- Data Operation:
- Get: Access goes over the network to another cluster node
- Put: Pushing the version of data to multiple cluster nodes
- Failover: Involves promoting backup data to be primary storage
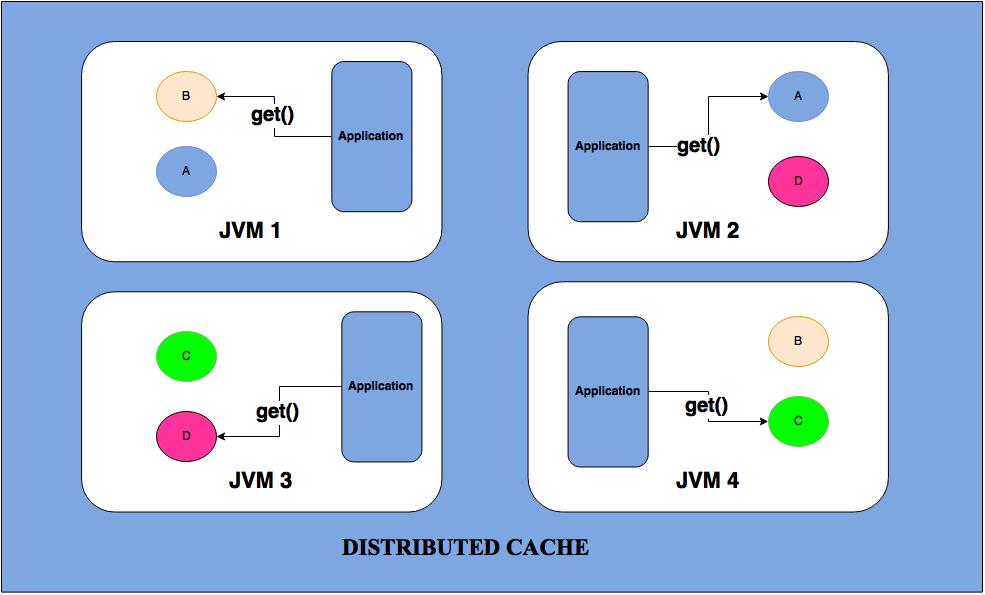
- Pros:
- As the above picture states distributed cache can be configured in a way where data is not fully replicated through out the cluster, thus write performance can be enhanced.
- Linear performance scalability for reads and writes
- Cons:
- Increased latency of reads (due to network round-trip and serialization / deserialization expenses)
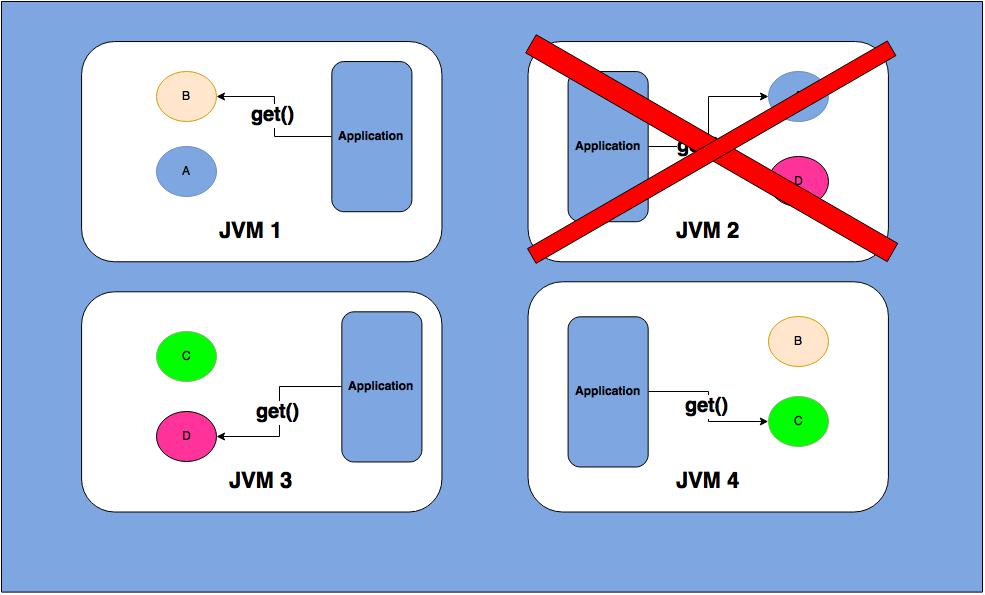
Fault-tolerant: As the above picture states in both replicated and distributed cache on the absence of node 2 data can be served from the other node.
We can conclude that an ideal cache would combine TTL and write-through features with distributed cluster mode with data consistency and provide high read-write performance.
Hazelcast Caching

Hazelcast is a brand new approach to data, and it is designed around the concept of distribution. Also, Hazelcast shares data around the cluster for flexibility and performance. It is an in-memory data grid for clustering and highly scalable data distribution.
One of the main features of Hazelcast is not having a master node. Each node in the cluster is configured to be the same in terms of functionality by sharing the metadata called partition table of the cluster. It consists of several information like members detail, cluster health, backup information, re-partitioning, etc. The first node created in the node cluster manages the cluster members, i.e. automatically performs the data assignment to nodes. If the oldest node dies, the second oldest node will manage the cluster members.
All clients are by default smart client, i.e they also have the metadata about the cluster but with restrictive information. So, a client can directly connect to primary data holding member to reduce the network lagging.
Another main feature of Hazelcast is the data being held entirely in-memory. In the case of a failure, such as a node crash, no data will be lost since Hazelcast distributes copies of data across all the nodes of the cluster.
Hope this will help to understand the importance of caching, in-memory-data-grid and distributed caching in the modern application.
If you are keen to know How to Integrate Hazelcast with Grails, read through this blog – Getting started with Hazelcast using Grails in 10 minutes
Stay tuned for more on:-
- Sharing the Load: Cache Clustering with Hazelcast
- Hazelcast as secondary level cache
- Hazelcast as Spring Data cache
I hope you enjoyed this blog and it was helpful. Here is another interesting blog on Enhancing throughput of Java apps performance by optimization of object deserialization and distributed query.
Thanks for reading, see you next time.
Here’s a quick reference to –
Distributed Caching with Hazelcast
Grails Plugin Contributions by experts @ TO THE NEW
For more reference:
high-quality content!
Thank you for sharing
Very informative. Nice comparisons.
Great Comparison of different approaches to caching (y)