In my earlier blog on Caching: What, Why and How with Hazelcast we have discussed about the importance of software caching and how to implement it with Hazelcast.
In this blog, we are going to discuss the importance of distributed caching and how to configure Hazelcast to be a full TCP/IP cluster.
What is Cache clustering?
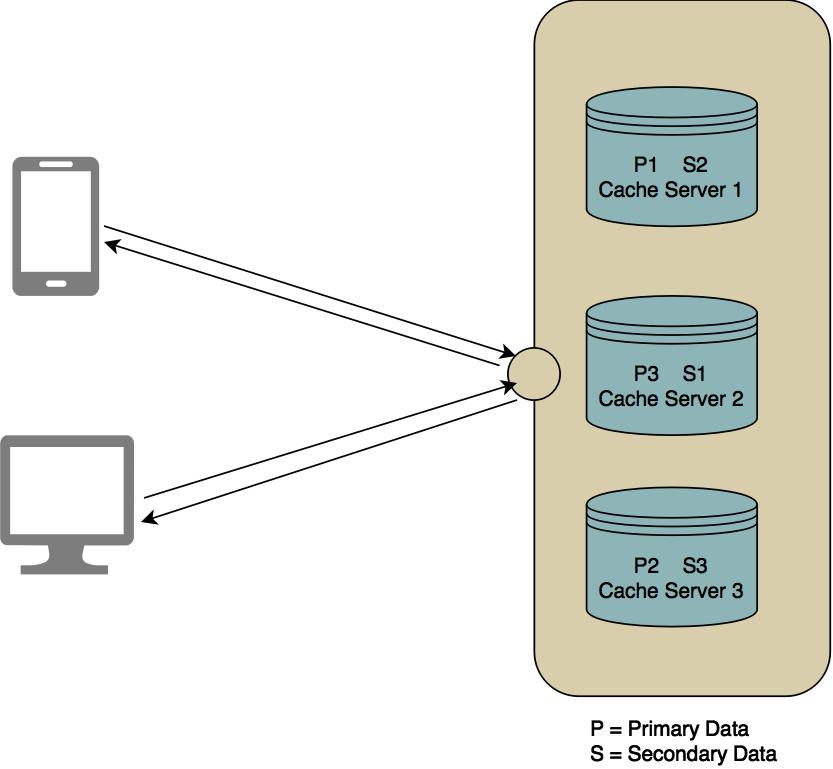
A cache cluster is a network of cluster members to be a Replicated / Distributed cache server to achieve data high availability and fault tolerance. Cluster members (also called nodes) can automatically join together to form a cluster. This automatic joining can take place with various discovery mechanisms that the cluster members use to find each other. After a cluster is formed, communication between cluster members is done always via TCP/ IP regardless of the discovery mechanism used.
Why is cache clustering required?
Recently at TO THE NEW, we came across a product, which as a platform allows its users to broadcast LIVE. It was a real-time application (RTA) where data was changing in very small time frames and it had to be reflected in the application in real time. Users can view personalized content based on their coordinates, geo-location etc. The application was highly performant and had relation and NoSQL databases used in its core as the primary data storage with Hazelcast as a cache server to caching data.
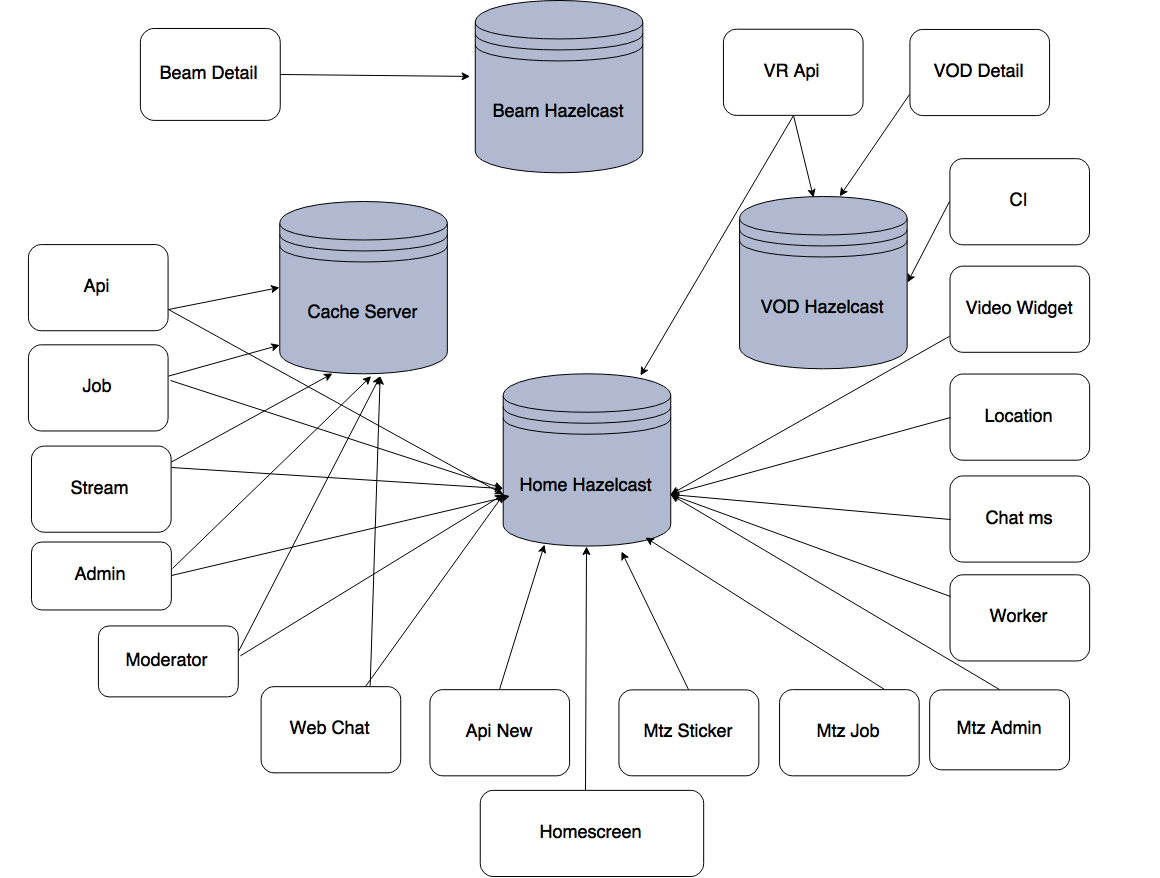
As above diagram states back-end is distributed into several small applications, each application serving a specific purpose. All user interaction and authentication done through application named API and a user can broadcast their content through application named Stream. The personalized content was served through Homescreen and Location applications and accessed data from the cache server, also it was precomputed in real time by few worker modules like Job , Worker . Users would communicate to each other on any Live content through Chat module, and all chat messages were checked for profanity before sending it to the user in real time.
Since different applications like Homescreen, Job, API, admin, vod, stream, beam detail, monetization modules accessing different cache server, it leads to some major issues,
- Infra cost: Since there are multiple cache servers named Home Hazelcast, Vod Hazelcast, Cache Hazelcast, Beam Hazelcast, to achieve data high availability i.e horizontal scaling a.k.a x-axis scaling for each cache server, more RAM and CPU power, etc. is needed and that comes at a cost.
- Accessing multiple cache server instance: As application like Homescreen needs to serve Live content data (comes from Home Hazelcast) and Vod data (comes from Vod Hazelcast) at the same time, the application needs access to both the cache servers, which increases application’s external dependencies.
- Tightly coupled: On-demand data is being exchanged among the applications through either polling/ webhook or API call, which tightly couple the applications to each other.
- Data out of synchronization: There is some part of data that is shared amongst the cache servers and the data changes rapidly. So it is hard to maintain data synchronization, which can be easily done through Hazelcast Pub/Sub model if all cache server is grouped into a cluster.
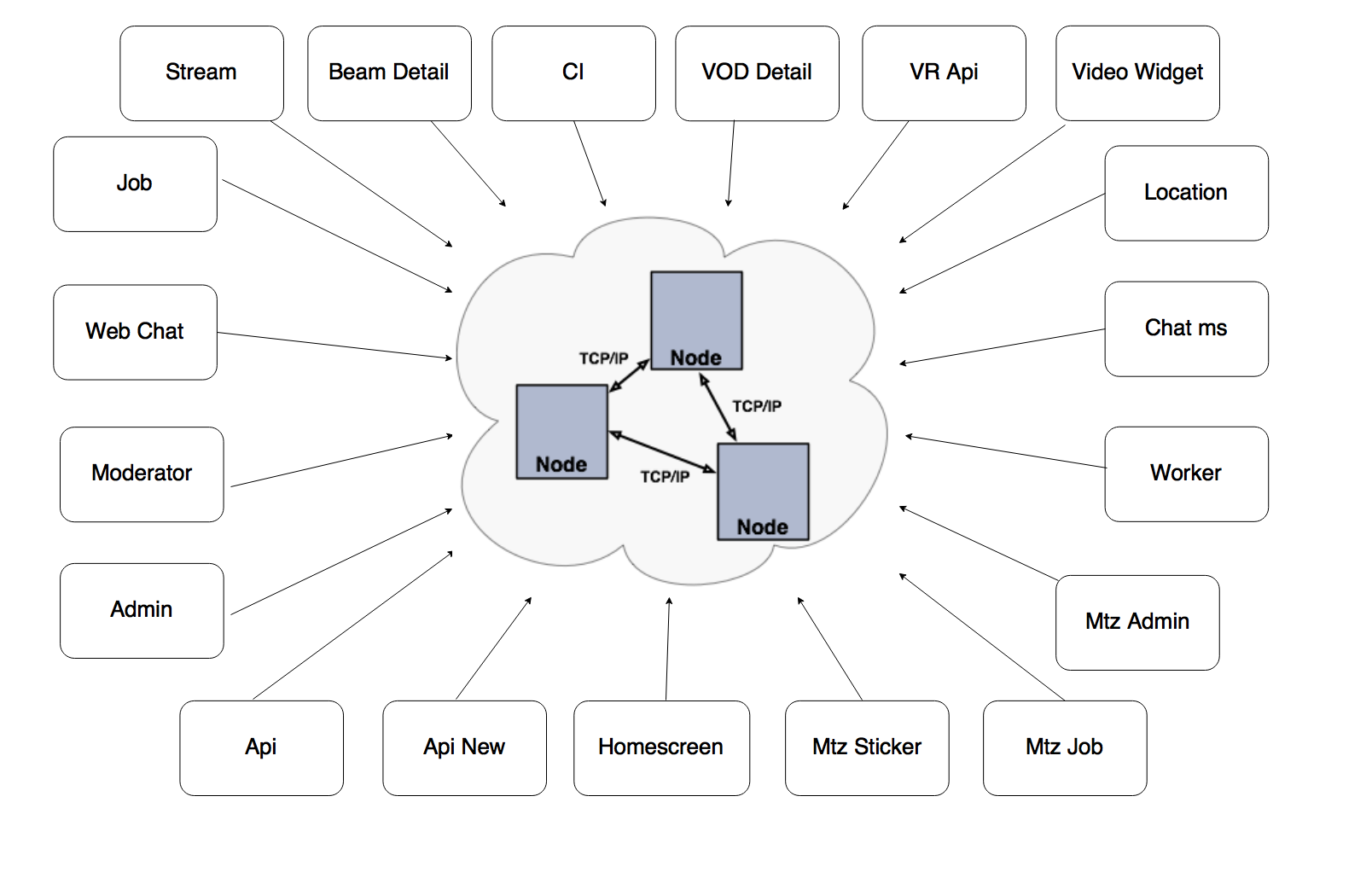 How to configure cache cluster with Hazelcast?
How to configure cache cluster with Hazelcast?
You can find all the information for configuring cluster in the official documentation of Hazelcast. Hazelcast cluster can be configured in with many discovery mechanisms like Multicast, TCP, EC2 Cloud, jclouds etc. The main configuration file is hazelcast.xml and we can continue with the default values for most of the configuration attribute. For simplicity, I have created a tested and workable project to provide configuration for Hazelcast to be a full TCP/IP cluster with a minimum configuration which fulfills our most use cases.
Step 1: Clone the project git@github.com:bjpaul/hazelcast-cluster-setup.git or download zip into one of your servers, extract it. Download the latest version of Hazelcast from https://hazelcast.org/download/ and place the hazelcast-all-3.*.jar under hazelcast-cluster-setup/server-config/lib directory.
Step 2: Move to Hazelcast-cluster-setup/server-config/bin directory location and run sh start.sh. As a result, a new Hazelcast instance will start on that server.
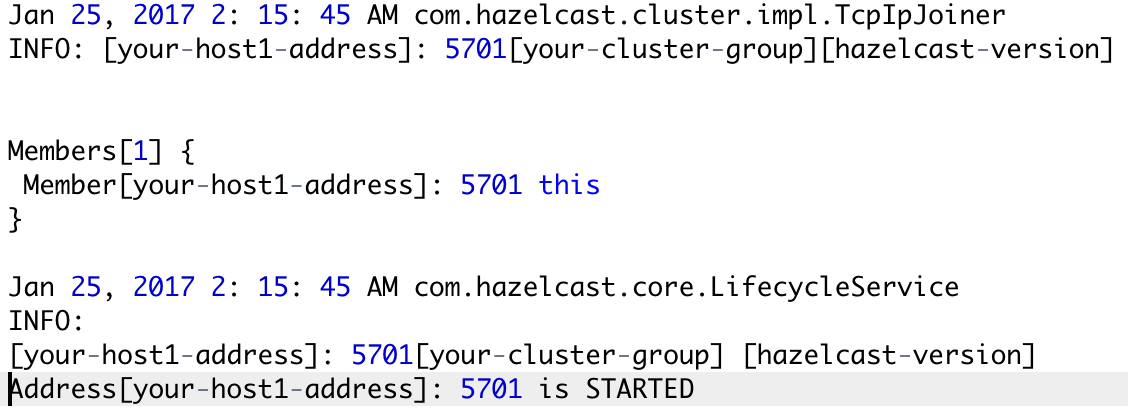
Now repeat the step 1-2 into another server, again a new Hazelcast instance will start and joins the cluster.
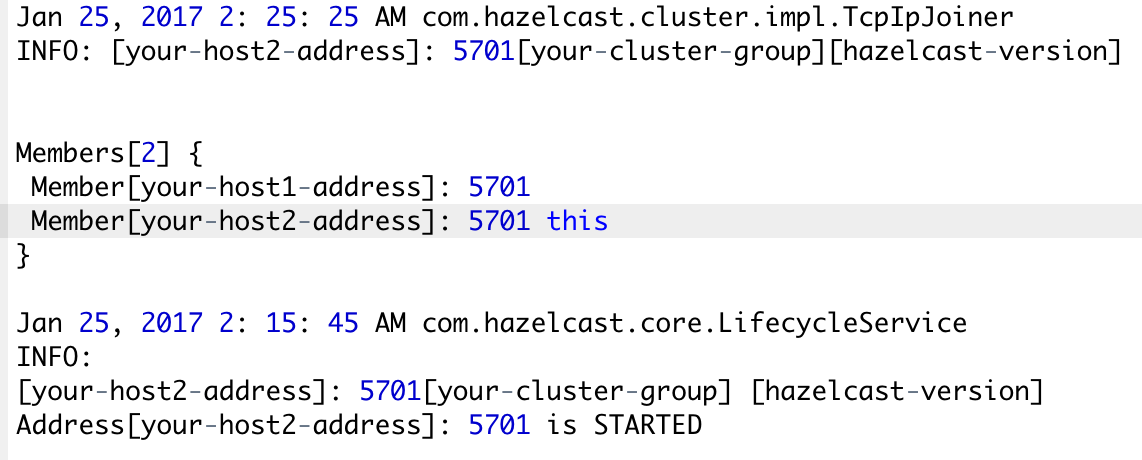 this keyword pointing to the current Hazelcast instance.
this keyword pointing to the current Hazelcast instance.
One of the main features of Hazelcast is not having a master node. Each node in the cluster is configured to be the same in terms of functionality by sharing the metadata called partition table of the cluster. It consists of information like members detail, cluster health, backup information, re-partitioning, etc. The first node created in the node cluster manages the cluster members, i.e. automatically performs the data assignment to nodes. If the oldest node dies, the second oldest node will manage the cluster members.
To test the data accessibility by a client to the cluster I have written a small java program. By default all client applications are the smart clients, i.e they also share the same partition table but with limited access, so the client application can connect directly to primary data holder member to reduce the network lag. To test this functionality we are passing only one server address (i.e host1) to connect the cluster.
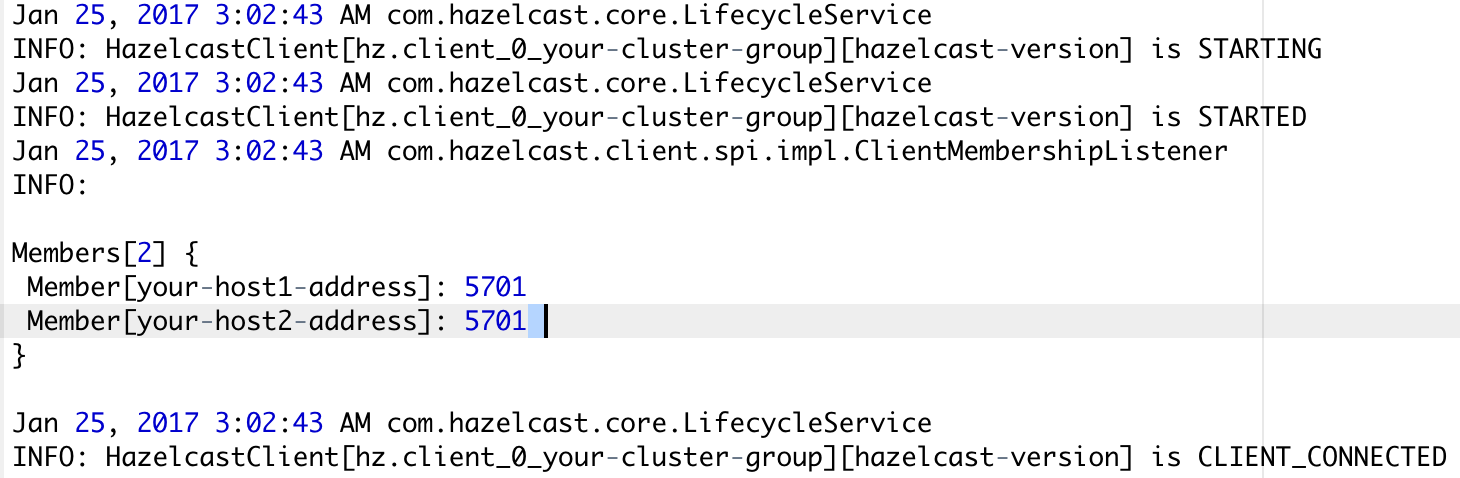
Now stop the host1 and check the client application log.

The client application still manages to access the cluster by discovering other available members, though initially, it has only the address host1 to connect the cluster.
But it is recommended that to access the cluster we should pass all server addresses of a cluster to the client, so it can connect to either of any available member.
Let’s look closely at the configuration attributes for hazelcast.xml.
[sourcecode language=”java”]
<hazelcast xsi:schemaLocation="http://www.hazelcast.com/schema/config hazelcast-config-3.*.xsd"
xmlns="http://www.hazelcast.com/schema/config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<group>
<name>your-cluster-group</name>
<password>password</password>
</group>
<properties>
<property name="hazelcast.tcp.join.port.try.count">5</property>
</properties>
<network>
<port auto-increment="true" port-count="100">5707</port>
<join>
<multicast enabled="false"/>
<tcp-ip enabled="true">
<member-list>
<member>machine1</member>
<member>machine2</member>
<member>machine3:5799</member>
<member>192.168.1.0-7</member>
<member>192.168.1.21</member>
</member-list>
</tcp-ip>
<aws enabled="false"/>
</join>
<interfaces enabled="true">
<interface>10.3.16.*</interface>
<interface>10.3.10.4-18</interface>
<interface>192.168.1.3</interface>
</interfaces>
</network>
</hazelcast>
[/sourcecode]
<group> | Creating cluster groups: By specifying a group name and group password, we can separate our clusters in a simple way. Example groupings can be by development, production, sandbox, stage, etc. Also using this functionality we can implement one a level of authentication on our cluster.
<network>: All network related configuration is performed via the element.network
<port>: We can specify the ports that Hazelcast will use to communicate between cluster members. Its default value is 5701.
<join>: The “join" configuration element is used to discover Hazelcast members and enable them to form a cluster. Here we used the TCP/IP mechanism and disabled all other options.
<properties> | <property> : We can set hazelcast system property using these tags. hazelcast.tcp.join.port.try.count is the number of incremental ports (default is 3), starting with the port number defined in the network configuration (default is 5701), that will be used to connect to a host (which is defined without a port in TCP/IP member list while a node is searching for a cluster).
<member-list> | <member>: These configuration elements are used to set all member list addresses.
<interfaces> | <interface> : We can specify which network interfaces that Hazelcast should use. Servers mostly have more than one network interface, so we may want to list the valid IPs. range characters (‘*’ and ‘-‘) that can be used for simplicity.
Hope this will help to understand the importance of cache clustering and how to configure Cache clustering with Hazelcast. Download the complete project from Github.
If you are keen to know How to Integrate Hazelcast with Grails, read through this blog – Getting started with Hazelcast using Grails in 10 minutes
Stay tuned for more on:-
- Hazelcast as secondary level cache
- Hazelcast as Spring Data cache
I hope you enjoyed this blog and it was helpful. Here is another interesting blog on Enhancing throughput of Java apps performance by optimization of object deserialization and distributed query.
Thanks for reading, see you next time.
Here’s a quick reference to –
Distributed Caching with Hazelcast
For more reference:
the aplicattions only get and put of the master? the other nodes they only function as replicas=
There is no concept of master node in hazelcast cluster, hazelcast cluster work on the peer-to-peer model