
DataSafe – A Data Archival Tool
#fame is India’s first (and now the biggest) live-streaming app on IOS and Android platforms. This app allows people to create their own beam and go live immediately, or book a slot for future. As time passed, the operational databases of #fame kept on increasing at a great speed. As a result, the disk space utilization of database server reached 80%.
Possible Solutions:
1) Vertical scaling of the server: This would cost a lot of money and require downtime on the database server which was unacceptable.
2) Sharding of MongoDB: This required a lot of time, resources and expertise in sharding.
3) Data Archival: Now in a database, there are few tables in which data is only written but never retrieved. In #fame, more than 70% of the data was only written and was never retrieved. Hence this data can be archived into a warehouse. Apparently, we picked this solution.
DataSafe: DataSafe is a data migration tool built by the Big Data team of #fame which can archive various databases into a Hadoop cluster*. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. DataSafe is a one-click cloud solution which uses the power of parallel processing provided by Apache Spark** to archive data at a very fast pace.
By using DataSafe, one can take backup of GBs of data into the HDFS (Hadoop Distributed File System) in few minutes. DataSafe not only archives the data but also stores it in tabular form so that it can be queried upon as if it were in a Mysql table. This is made possible by importing the data in hive tables. You must be wondering what hive tables are. Apache Hive is a data warehouse infrastructure built on top of Hadoop for providing data summarization, query, and analysis. Hive tables can be queried using HQL (Hive Query Language), which is based on SQL. Hence, retrieval and querying data are pretty easy. Moreover, the Hadoop distribution that we use, namely Cloudera Hadoop distribution, has a UI for querying hive tables called HUE.
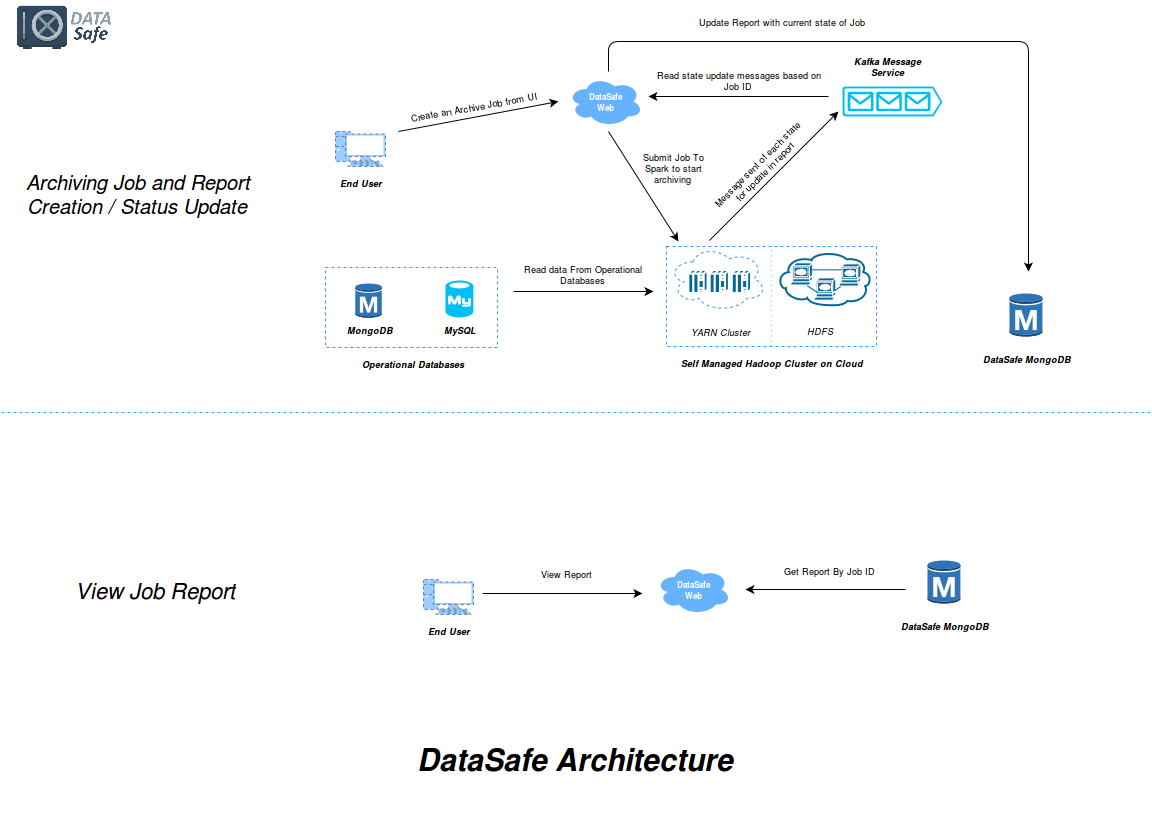
Fig 1: DataSafe Architecture
Steps for data archival:
- DataSafe allows the user to select the datasource for data archival from a list of available data sources. Presently there are 2 data sources available namely, MongoDB and Mysql.
- Next the user has to select the database and the coresponding tables(from Mysql) or collections(from MongoDB) for that database.
- Next the user is required to select the date range for data archival.
- Lastly user has to click on submit to trigger the archival process. User can track the status of the archival process, i.e. a job after submission goes through various stages: Submitted, Started, Running and the final stage can be Completed, Failed or Completed with Failure. DataSafe allows you to track the stage your job is in and time it took while executing at each stage.
DataSafe is designed to provide users a one-click cloud solution for unloading their operational databases so as to relieve the operational database servers of the undesirable tables or collections. DataSafe is fully operational and is being used in #fame for archiving various tables such as notificationHistory(this table stores the details of notifications sent across the users) on a daily basis.
