Through this blog, I would be explaining how to automate Docker deployments in AWS ECS using a Use Case.
Prerequisite: Basic understanding of how Docker and AWS ECS works would be helpful.
In the given use case, we have used microservices architecture, and earlier deployments were done manually. It used to take 15-20 minutes per service per deployment. After exploring different Docker Orchestration Tools, we were able to reduce deployment time by 90% without any downtime using AWS ECS. During the initial stage, the toughest part was designing the Docker build and deploy pipeline. In our case, we are using AWS ECS. Therefore deployment script is specific to AWS ECS, but the deployment logic remains the same for any orchestration tool.
After going through the official Docker documentation, we were able to crack our complete Docker build, test, and deploy story. Please find below diagram showing complete build, test and deploy process:
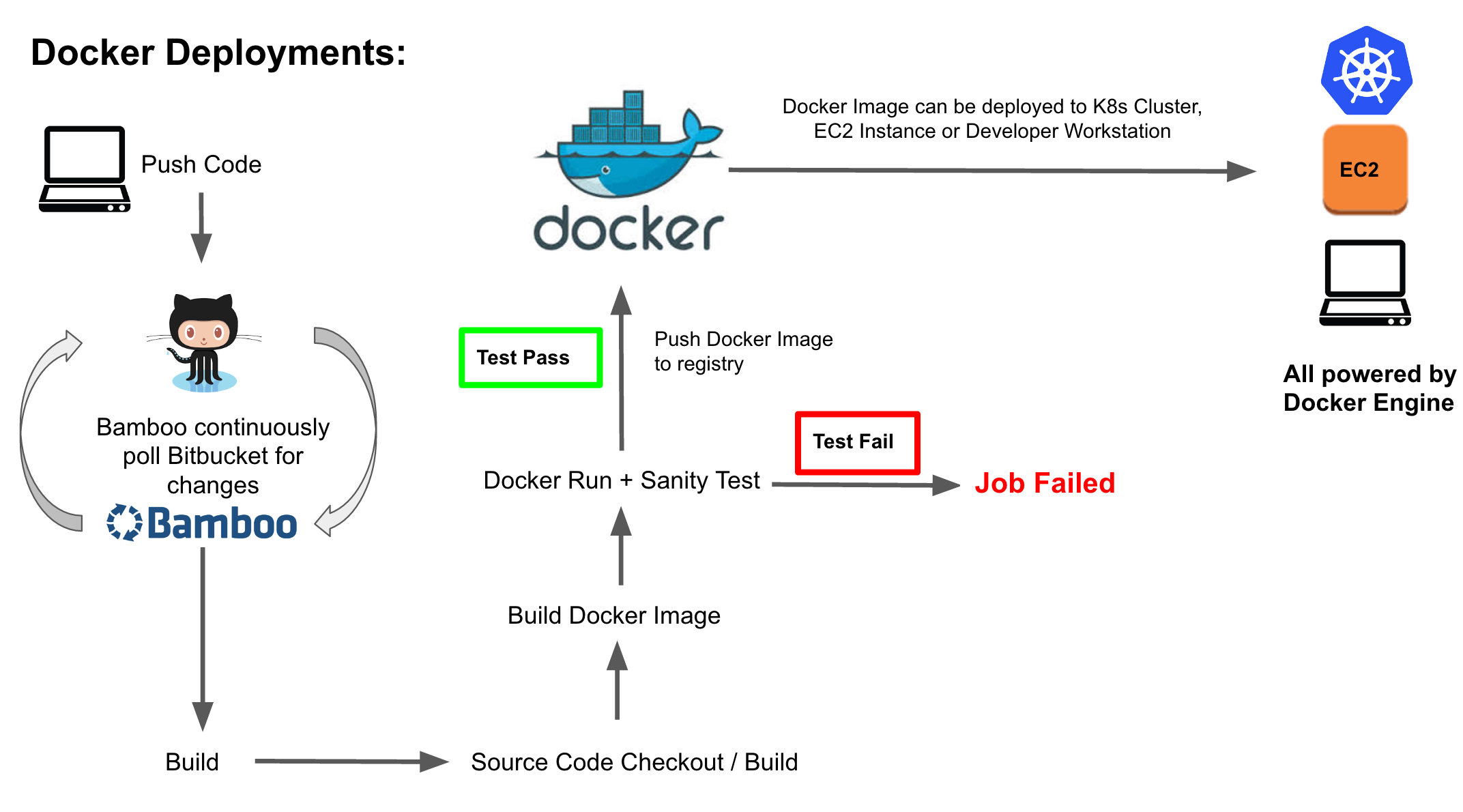
As you can see in the above diagram, we have a bamboo agent polling Git repo at regular intervals to check if there are any changes and if there is a change detected, bamboo will run the build plan. In the build plan, we create artifact i.e. jar or war, then using Docker plugin we build Docker image with build number as the tag. Post that we run newly created Docker image with the stub jar (stub jar is a single jar file that carries all the dependencies and test cases for the application) to do sanity test. If newly created Docker image passes sanity test, we push the image to private Docker registry otherwise, build process fails and send out a notification to the DevOps team. This process is quite seamless.
We have prepared custom base Docker images for Spring Boot, Tomcat, and Node. We use these base Docker images in the Bamboo build plan as it helps us in reducing build time in case we need to add/modify/remove any configurations. This can be done by using base images, rather than updating all the images. I am not a big fan of sed command in startup scripts, therefore we use ep command in our startup scripts to generate configuration files using environment variables in the Docker Containers. EP is a small utility written in Ruby that replaces environment variables in the file. For more details click here. You can just add below mentioned line to your Dockerfile and start using it in place of sed command:
[js]
RUN curl -sLo /usr/local/bin/ep https://github.com/kreuzwerker/envplate/releases/download/v0.0.8/ep-linux && chmod +x /usr/local/bin/ep
[/js]

Sample Dockerfile:
[js]
FROM neerajaws/java:1 # Custom base image with tools, newrelic etc
ADD target/app.jar app.jar # Adding jar file to the Docker image
ADD startup-env-v2.sh /startup-env-v2.sh # Startup script that replaces variables in configuration files and generates startup command using environment variables
RUN curl -sLo /usr/local/bin/ep https://github.com/kreuzwerker/envplate/releases/download/v0.0.8/ep-linux && chmod +x /usr/local/bin/ep
RUN chmod +x /startup-env-v2.sh
EXPOSE 8080
CMD ["bash","/startup-env-v2.sh"] [/js]
Next, we have is the deployment process, so the Docker image we build can be used in any environment i.e. QA, staging, production by just tweaking the environment variables in the Docker run command. We are using AWS ECS as orchestration tool for managing Docker Containers and therefore we can now do deployments using AWS CLI. You can do manual deployments in ECS by creating new task definition, updating Docker image and updating service with the latest task definition and deployment will happen based upon min and max percentages defined in deployments. I wrote small script that uses AWS CLI and jq to extract existing task definition into a JSON, update task definition with latest Docker image and update service with latest task definition and script can be found below:
[js]
#!/bin/bash
TASK_FAMILY= "ttn-qa-webapp-task"
SERVICE_NAME= "ttn-qa-webapp-service"
NEW_DOCKER_IMAGE="ttn-qa-webapp:${bamboo.buildNumber}"
CLUSTER_NAME= "ttn-qa-cluster"
OLD_TASK_DEF=$(aws ecs describe-task-definition –task-definition $TASK_FAMILY –output json)
NEW_TASK_DEF=$(echo $OLD_TASK_DEF | jq –arg NDI $NEW_DOCKER_IMAGE ‘.taskDefinition.containerDefinitions[0].image=$NDI’)
FINAL_TASK=$(echo $NEW_TASK_DEF | jq ‘.taskDefinition|{family: .family, volumes: .volumes, containerDefinitions: .containerDefinitions}’)
aws ecs register-task-definition –family $TASK_FAMILY –cli-input-json "$(echo $FINAL_TASK)"
aws ecs update-service –service $SERVICE_NAME –task-definition $TASK_FAMILY –cluster $CLUSTER_NAME
[/js]
In short, Task Definition defines container parameters like docker image, container port, host port, memory, environment variables and few more parameters. The Service allows you to run specified number of docker containers (desired) of a task definition running and ELB is used for service discovery and health checks. In the beginning, we used to create Task Definition, ELB and Service manually. But now we have written scripts that create ELB, task definition and service based on the input parameters specified (docker image URL, host port, container port, ELB name, and environment).
The deployment options available in AWS ECS works on “stop one, start one” pattern, it will start new tasks, and once it passes the ELB health check, it stops the old task. This feature ensures zero downtime during deployments and when it stops the task, it deregisters container instance from the ELB and performs connection draining. The only drawback with AWS ECS deployment is that it doesn’t notify in case new deployment fails.
Using all the above-mentioned features and deployment script, we can now do deployments in production hours without any downtime and we have been able to reduce deployment time from 15-20 minutes to 2-3 minutes.
Very good script and explanation…
you really helped me a lot!
Thanks
Very well written script
Can you please give us a picture of how your Codepipeline looks like and the app spec looks like for the deployment script to be triggered?
Very well documented…
i am very much like to receive DevOps white papaers.