
Python Borrowing Resources using Fabric
In my previous blog post, I wrote about Cost Optimizations for the various AWS resources. The script consisted of six methods and the overall time required for the script to execute was roughly about 15-20 mins. While the script is running, it used to slow down my system.
Also, there was a time consumption due to many reasons like network discrepancies, computation, and the creation of CSV, & XLS files. When I run this script along with other such several scripts in consolidation on my local machine, they do a lot of computation and as a result, my system becomes slow due to high usage of compute and memory power for the execution. I have no option but to wait for it to complete. To overcome this problem there were 3 ways:
- Increase the compute or memory capacity of the local machine but it is not always feasible and not very handy.
- Using a high resource machine altogether. Copy and run the whole script(s) on a different machine with high resources and then get the output on our local machine, but in this case, the all the logs generated would be on the remote machine and it will keep you engage with another machine.
- We execute the script on our own system but run parts of the scripts in multiple (idle) machines utilizing their resources and get the output in our own system.
So, I chose the 3rd option. Yes, I ran my script on my own machine which made use of multiple idle machines utilizing their resources and generated the final output on my own machine. The only thing is to divide and run the parts of the script (defined as functions) as per available idle machines dynamically.
To address this, I made use of fabric with the help of multiple remote machines. A Fabric is a library present in python which is basically used for ssh automation over multiple servers. Using it we can execute commands remotely like uploading and downloading files from the server or other computational jobs.
The main reason was to divide the methods and run them separately on multiple machines at the same time so that we can utilize the computation power of other idle machines keeping my own machine free from any load and I can work parallel on other jobs. To use fabric you need to create a fabfile.py in which tasks are defined as shown below:
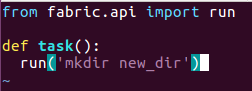
To run the task use the following command, for example:
![]()
‘remote’ is the address of remote machine(s)
This command will execute the task on the remote machine and create a directory named ‘new_dir’ in the remote machine or any task you want.
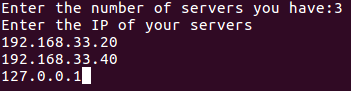
For my script, I decided to make use of 2 other servers apart from my own machine so the workload for my machine limited to only one third. It can be designed in such a way that it asks the user to enter any number of IP’s of the servers where you want that script to run depending upon the number of parts/functions of the script you want to divide. For my use-case, I made the script work with a total of 3 IP’s entered including my localhost:
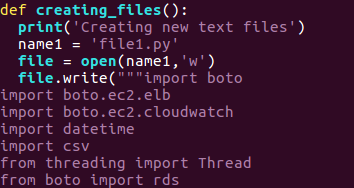
In my script, I had following 6 methods. The output of these functions (CSVs) is aggregated to have a single spreadsheet containing the results.
- idle_elb()
- idle_rds_instances()
- underutilized_ebs_volume()
- legacy_instance_type()
- low_utilization_ec2()
- idle_eip()
The main script, when executed with 3 IPs will create 3 files by the name file1.py, file2.py, file3.py containing 2 methods each.
main script:
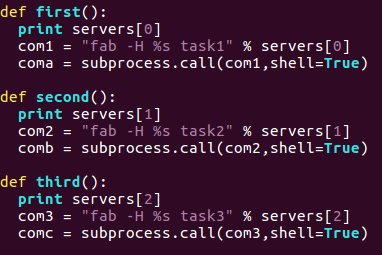
Since I have created 3 tasks in the fabfile.py each of the tasks are called using the main script for execution. The IP’s are stored in an array and the tasks in the fabfile are executed using subprocess so that we can run the shell command in python.
fabfile.py :
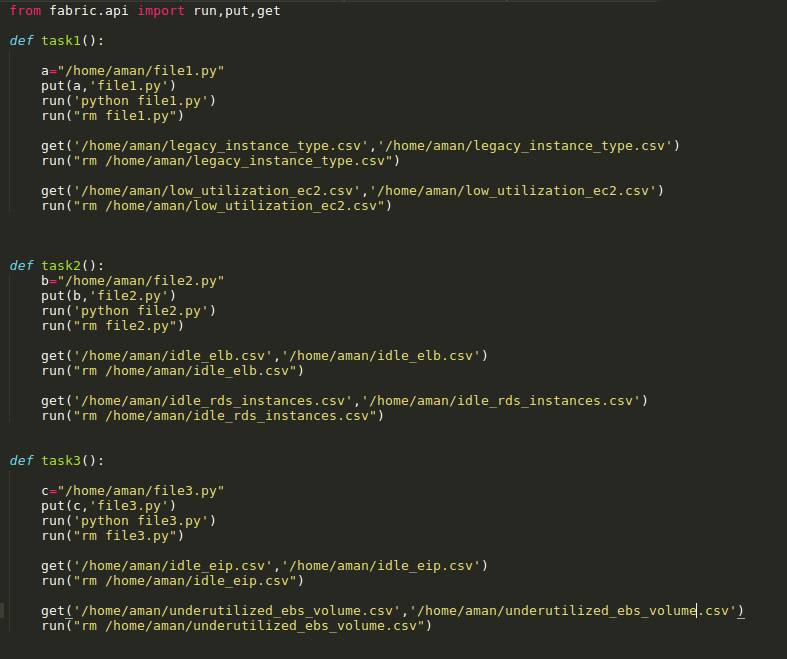
The output generated (CSVs) on remote servers at the specified location are copied over to my local machine once all computational work is completed for final aggregation to a spreadsheet and then are deleted from the remote servers. The important thing to note here is that all this happens in a single SSH session with each machine thus saving from network latencies.
The main script uses multithreading for parallel execution of methods on the remote machines. At last, final aggregation happens locally and the final xls file is generated in my local system itself.
Prerequisites for running the script:
- Boto (Version=’2.40.0′) should be installed in the system and configured
- AWS Account (Access Key Id, Secret Key) with READ ONLY access.
- To review the created CSV file, a xlwt package is required to be installed
- The ssh authentication method to the machines should be key based
Happy Coding 🙂


