Introduction
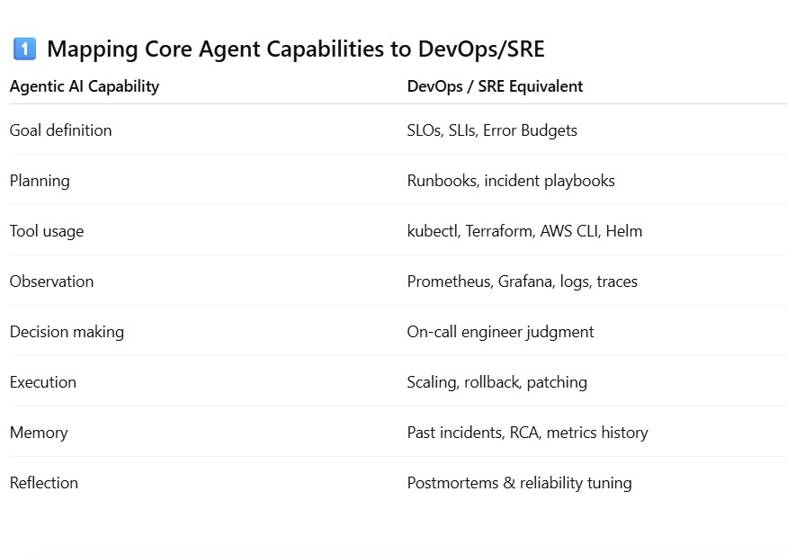
For years, Site Reliability Engineering (SRE) has been built around a simple mission: keep systems reliable at scale. We measure SLOs, manage error budgets, write runbooks, respond to incidents, and automate toil wherever possible.
But even with automation, most SRE work remains fundamentally reactive:
Alerts wake us up.
We investigate dashboards.
We correlate logs and traces.
We execute runbooks.
We verify recovery.
We write postmortems.
Now imagine an AI system that doesn’t just assist with these tasks—but owns the loop.
This is where Agentic AI enters the SRE landscape.
Agentic AI is not another chatbot integrated into Slack. It is a goal-driven autonomous system capable of observing telemetry, reasoning over SLO violations, selecting remediation strategies, executing infrastructure actions, and validating outcomes—without waiting for step-by-step human instructions.
Agentic AI as an “Autonomous SRE”
Think of Agentic AI as a Senior SRE who never sleeps, continuously running this loop:
Observe → Decide → Act → Verify → Learn
Agentic AI and SRE
2️⃣ Agentic AI Lifecycle in SRE Context
🔍 Observe
– Reads:
-Prometheus metrics
-Grafana alerts
-ELK logs
-Traces (Jaeger, Tempo)
Example
Javascript Command
Error rate > 2%
P99 latency spike
Node CPU throttling detected
🧠 Decide
The agent reasons:
Is this transient?
-Is it traffic, infra, or app-level?
-Does this violate SLO?
Human-like reasoning
“Latency spike + CPU throttling + HPA maxed → scale nodes first.”
🛠 Act
Agent executes tools autonomously:
-Increase node group size
-Adjust HPA
-Roll back bad deployment
-Restart unhealthy pods
✅ Verify
-Checks metrics again
-Confirms error rate drops
-Confirms latency normalizes
-If not → replan
🧾 Learn
-Stores outcome:
-“Scaling alone insufficient → memory leak”
-Updates future decision weights
-Improves runbook automatically
3️⃣ Concrete Use Cases (Very Real)
🚨 Autonomous Incident Response
Traditional
-Alert → Wake human → Diagnose → Fix
Agentic
-Alert → Diagnose → Fix → Notify human
Example
“502 spike detected → recent deploy → rollback → confirm recovery → Slack update.”
♻️ Self-Healing Infrastructure
-Detects unhealthy nodes
-Cordons & drains
-Recreates infra via Terraform
-Verifies cluster health
No pager. No manual SSH.
📈 Intelligent Auto-Scaling (Beyond HPA)
Agent uses:
-Traffic forecasts
-Business hours
-Past incidents
Instead of reactive scaling:
“Black Friday approaching → pre-scale infra.”
🔐 Security + Reliability Combo
-Agent:
-Detects abnormal API access
-Correlates with infra stress
-Blocks IP
-Rotates secrets
-Files incident ticket
Conclusion
Agentic AI = Autonomous SRE that enforces SLOs, executes runbooks, heals infrastructure, and learns from every incident.