
Fluentd – The Log Collector
Whenever we talk about Log Analysis which is to create some sense out of the computer generated records, we always need some tools which can first collect these logs from different devices, operating systems or any applications. These tools are generally termed as Log Collectors.
There are two popular log collectors – Logstash & Fluentd. Logstash is written in JRuby and is maintained by elastic.co. However, Fluentd is written in CRuby and is maintained by Treasure Data Inc.

Fluentd works on Unified Logging Layer means it tries to structure logs as JSON as much as possible. The idea is to provide an interface which can be used by almost any producer or any consumer of the logs. This helps in all phases of log processing like Collection, Filter, and Output/Display.
Like Logstash, it also provides 300+ plugins out of which only a few are provided by official Fluentd repo and a majority of them are maintained by individuals.
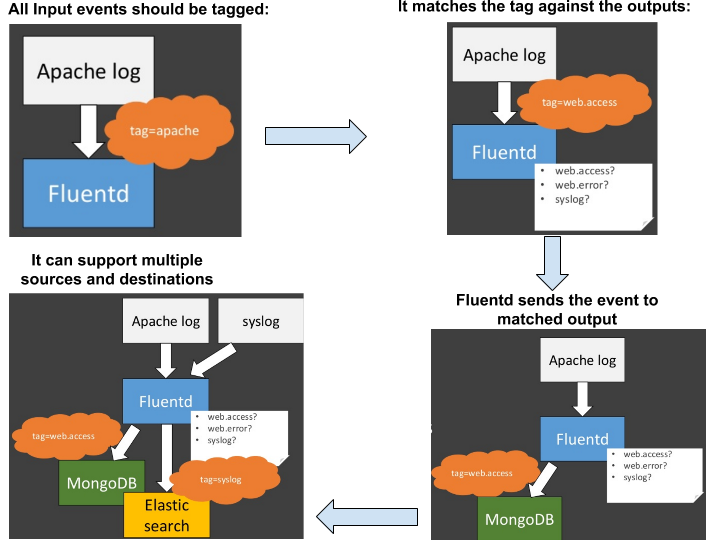
It can easily be replaced with Logstash as a log collector subject to some pros and cons in existing ELK stack making it EFK stack. Unlike Logstash which works with Aggregation of logs from different sources, Fluentd works on Routing on the basis of TAGs assigned on each input.
Lifecycle of Fluentd Event:
Basic Directives Involved
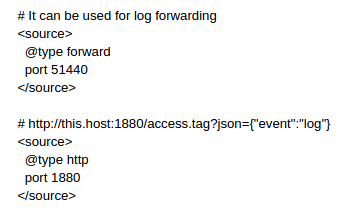
source: This mandatory directive is required to define the type parameter which specifies which input plugin to use:
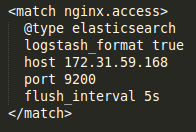
match: “decide what to do !” Each match directive must include a match pattern and a type parameter. Events with a tag matching the pattern will be picked and sent to the output destination. The destination could be Elasticsearch, S3, Mongo or to Treasure Data directly:

filter: It has same the syntax as “match” but “filter” could be used for further processing before pushing it to output. Using filters, event flow is like below:
Input -> filter 1 -> … -> filter N -> Output

In my case, I wanted to forward all Nginx access log to Elasticsearch, I used below configuration using tag ‘nginx.access’:
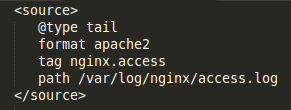
There are multiple pre-defined recipes available on Fluentd which you can utilize. Like Logstash, Fluentd also makes use of Regex patterns for the logs whose format is not known or is not already available with Fluentd. Those patterns can be verified on Fluentular.
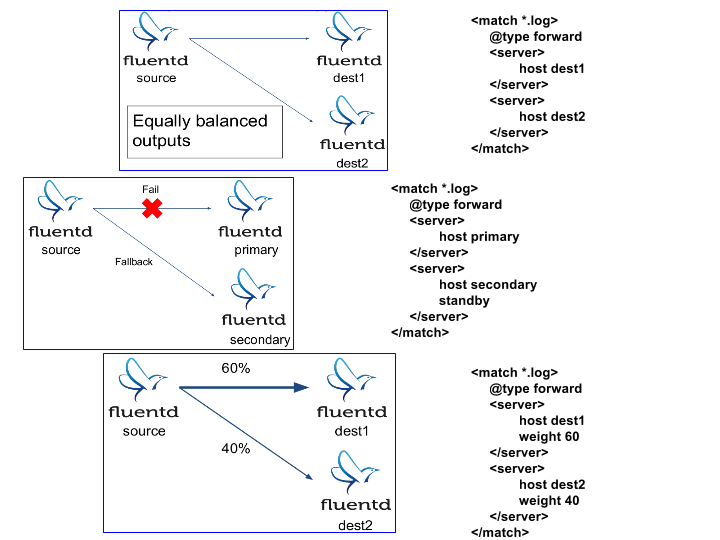
Unlike Logstash, which can only be configured as Active-Standby, Fluentd can be configured as Active-Active (Load Balancing mode), Active-Standby mode, Weighted Load Balancing modes.
Since Fluentd was invented by Treasure Data Inc, TD also provides Fluentd in td-agent form which is a more stable distribution of Fluentd. It supports multiple Installation medium and comes with preconfigured recommended settings.
So when a Simple, Flexible, Reliable Unified Logging tool is required, you can directly choose Fluentd.


