Big Data in itself brings many challenges; as is the case with anything related to data. Predictive Analysis is one part which takes up much effort and attention as well.
One of the foremost challenge which one comes across is how to get started with the “subject”. I would first like to highlight the basic things which one must know, to start with Predictive Analysis or any data driven analysis.
1. Basic Level Algebra (Linear, Quadratic, Logarithmic equations)
2. Basic Level Calculus (Differential, a bit of Integral)
3. Medium Level Geometry (n-dimensional space i.e. Data Space, Weight Space in n dimensions, intuitive understanding of hyperplane for n-dimension etc.)
4. Medium Level Statistics (intuitive understanding of measures of central tendancy, measures of dispersion)
All of these form a base to go forward with Predictive Analysis. After this, come the big guns. The “Algorithms” for predictive analysis. Following figure would better describe the subject.
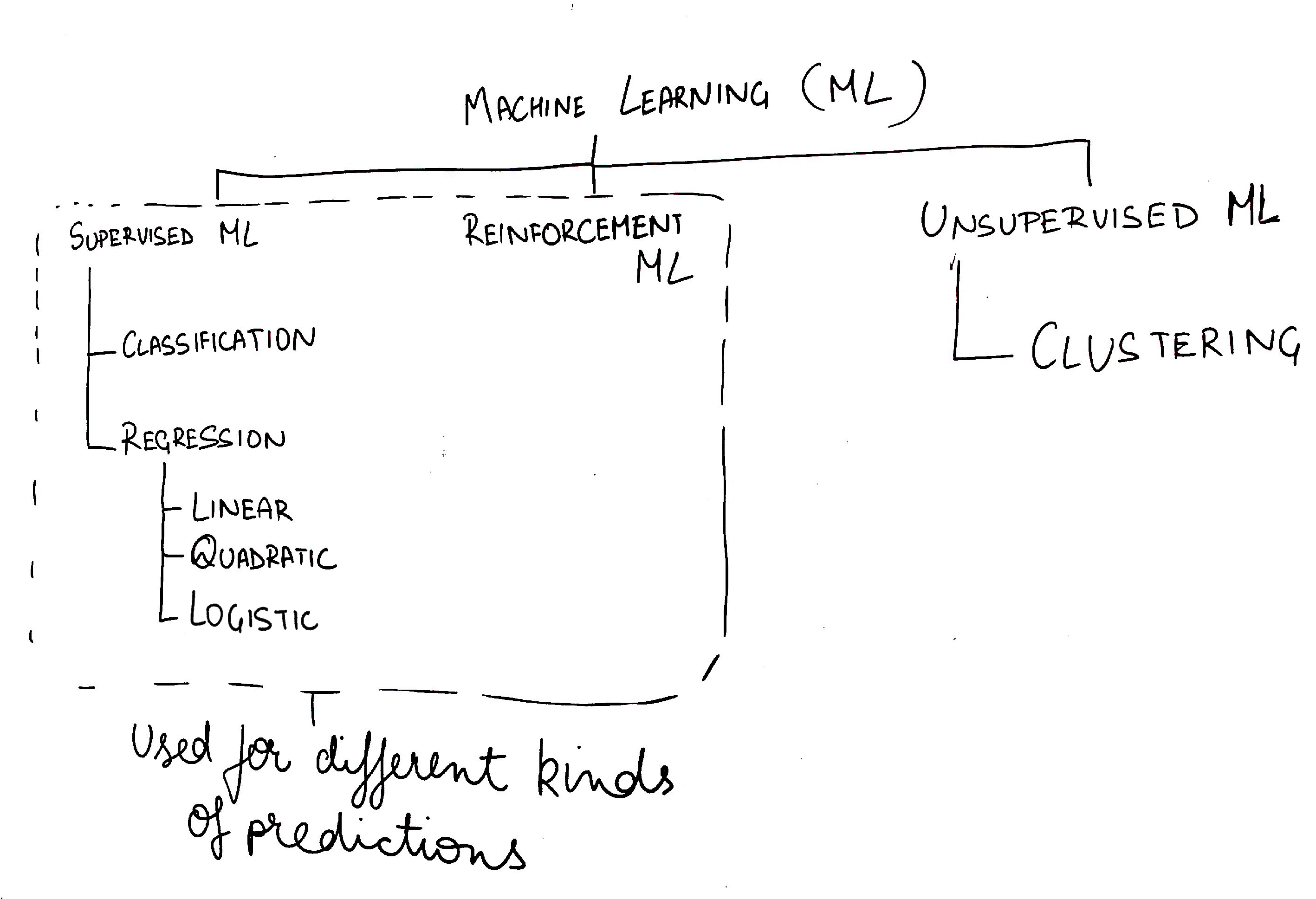
Supervised and Reinforcement Machine Learning algorithms are used for predictions. Unsupervised Machine Learning technique i.e. Clustering also employs many algorithms but is used usually to get an insight of the data, without much knowledge about the sector or industry from which the data has been taken.
Reinforcement Machine Learning algorithms are used usually to predict the best behaviour of an artificial object in the real world space. A classic example of this type of learning is Chess, which tries to predict the next best move each time the algorithm is run. This type of machine learning is hard to implement, and is a subject in itself.
The most commonly used algorithms for predictive analysis, fall under the category of Supervised Learning.
To start with the predictive analysis, I would recommend, that one should start with Regression Algorithms, and then move over to Classification.
Regression deals with continous data, i.e. data which involves numbers; while, Classification deals with discrete data. An example is shown alongwith some popular algorithms for both.
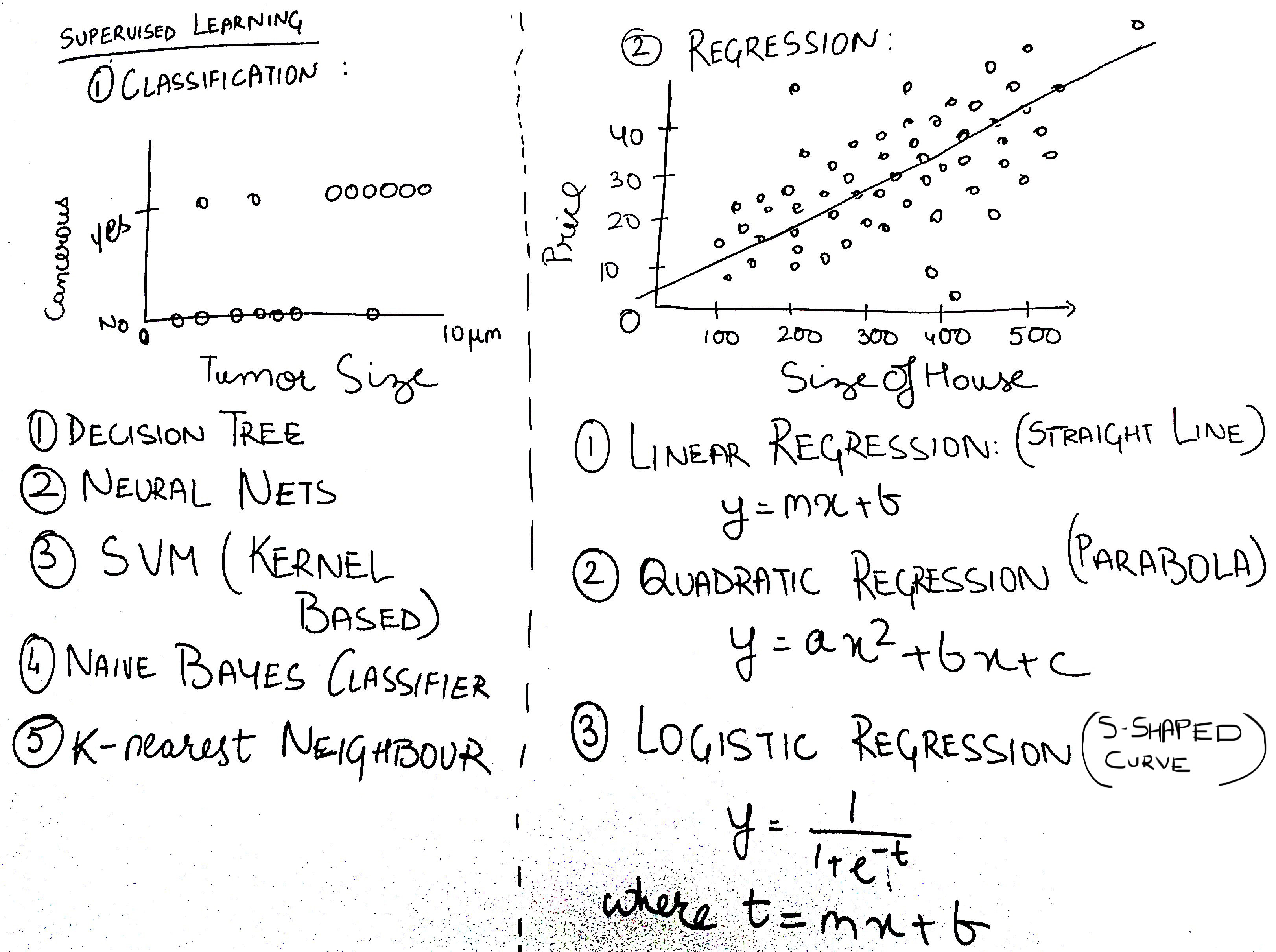
It is pretty evident in the above figure that, Classification is dealing with data like “Yes” or “No”, while Regression is dealing with numeric data like Price of House, Size of House. Classification is trying to predict if a tumour of a particular size will be cancerous or not; Regression is trying to predict what could be the best selling price of a house, with a particular size.
This post was introductory, and only touched upon the various topics in the subject. I hope to write and discuss about the same in detail, in future.