R is the most common platform for predictive analysis. Rattle library is an extension of R which takes the predictive analysis to another level.
This blog is focused towards people who have some experience in R.
Rattle is the library provided for R language that is used for data mining process, where you can apply different type of clustering, classification types algorithm. Here you can transform the data as per requirements, can evaluate the relation between the datasets like co-relation, distributions etc. It provides a very fine tuned user interface to perform a large amount of data mining operations.
Steps to install/use the Rattle:
- install.package(“rattle);
- rattle();
Use Case: We have datasets of sales which contains different types of field like price, qty, shipping cost, item name, discount and many more. We can apply different types of algorithms as per our target variable. Let’s got through Rattle UI to perform different type of operations
- Datasets: We need to upload the datasets using Rattle. We can upload data in different format, partitioning the data like training, test data sets.
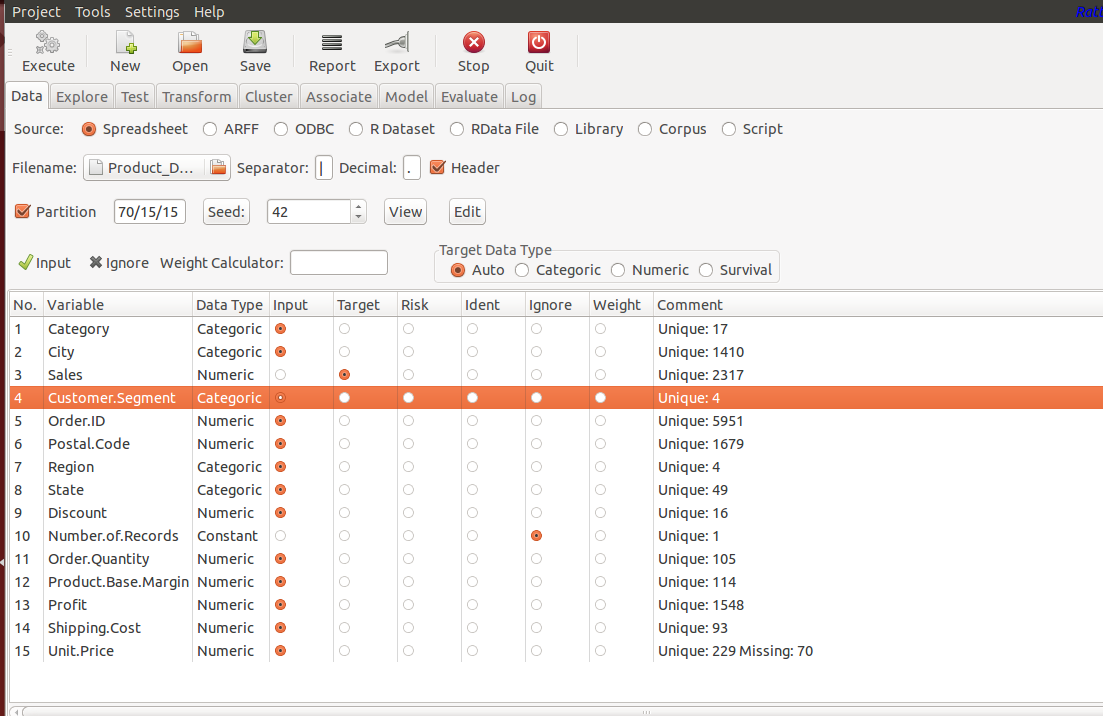
Input type variables, target type and their data type are automatically detected by Rattle. You can adjust it as per your requirements.
- Explore : You can explore the data like summarized datasets, check correlations, apply principle components etc. Here major one, to check the correlation of our datasets to remove the less importance variable from the input datasets.
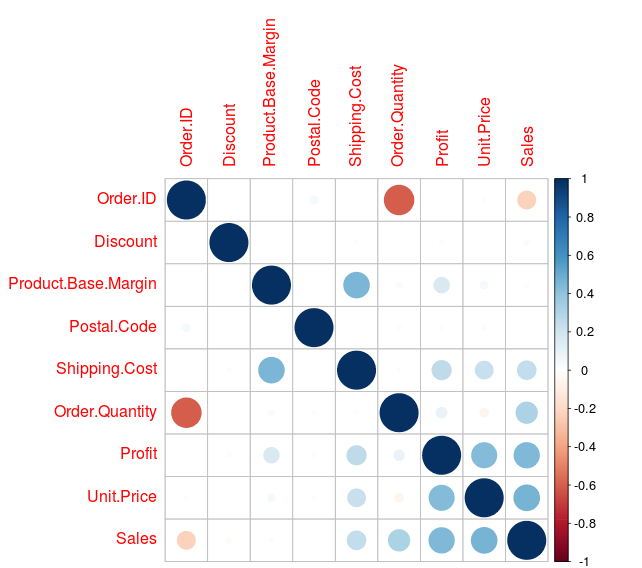
Here you can see the correlation between different types of variables, you can adjust your input variable as checking by correlations.
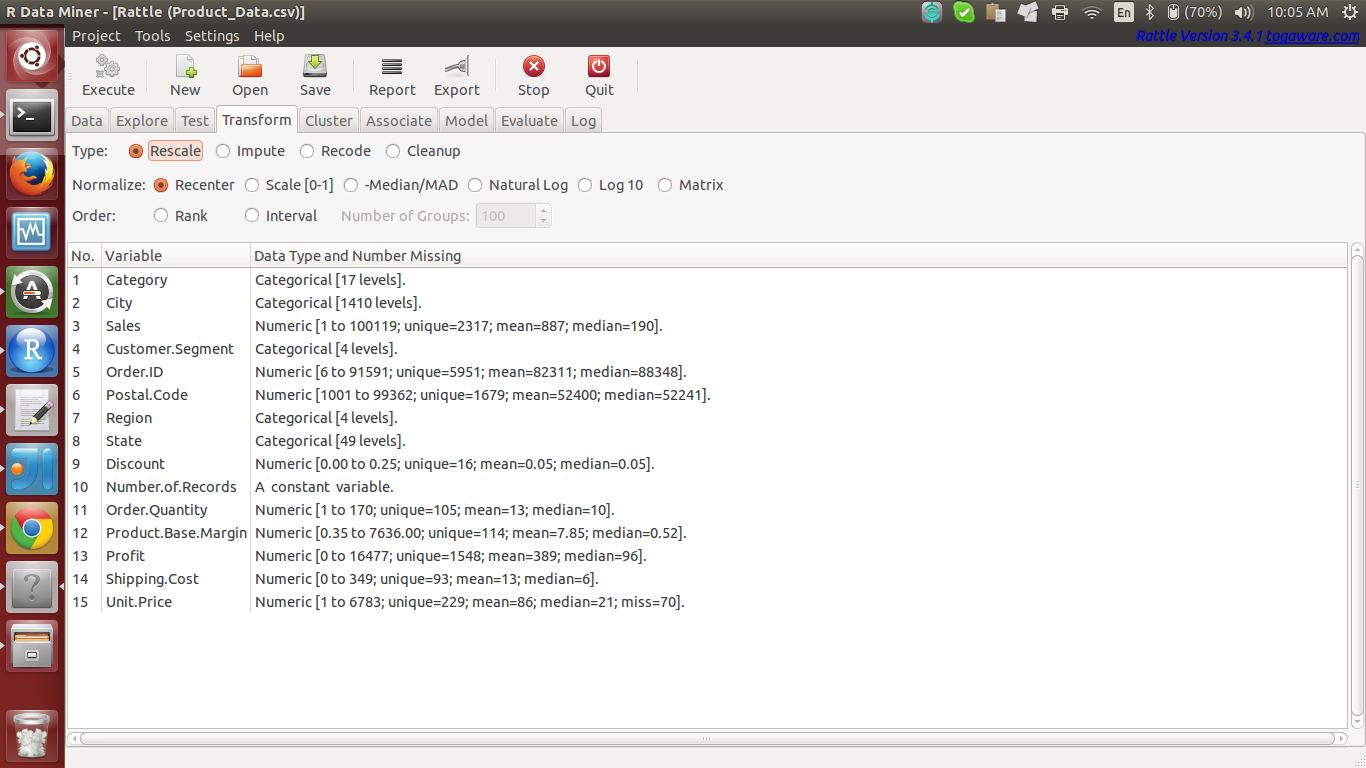
- Transform: Sometimes we need to transform the data like remove the observations that having missing data, to clean up data, Re-scale the data using different types of filters, these all features are provided in Rattle UI under transform tab.
- Clustering: Apply different types of cluster like k-means, Bi Cluster, plot clusters, check the stats of the data using cluster algorithm.
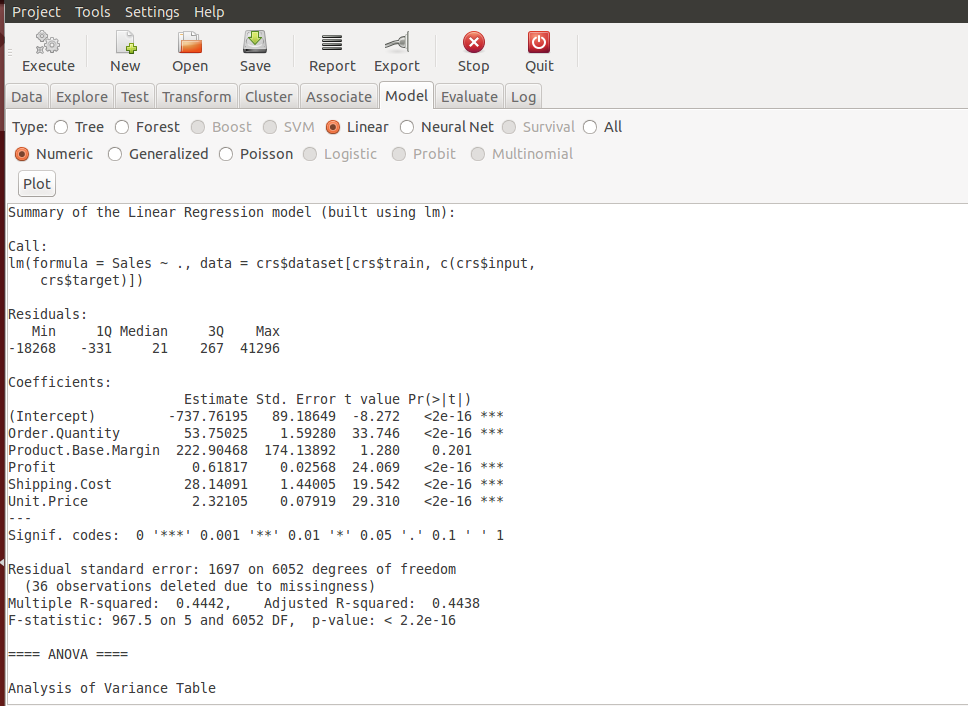
- Models: Use different types of model like tree, random forest, linear regression, neural networks. Choose the best one as per your use case. Our use case is to forecast the sales, so for this linear regression may provide the better results.
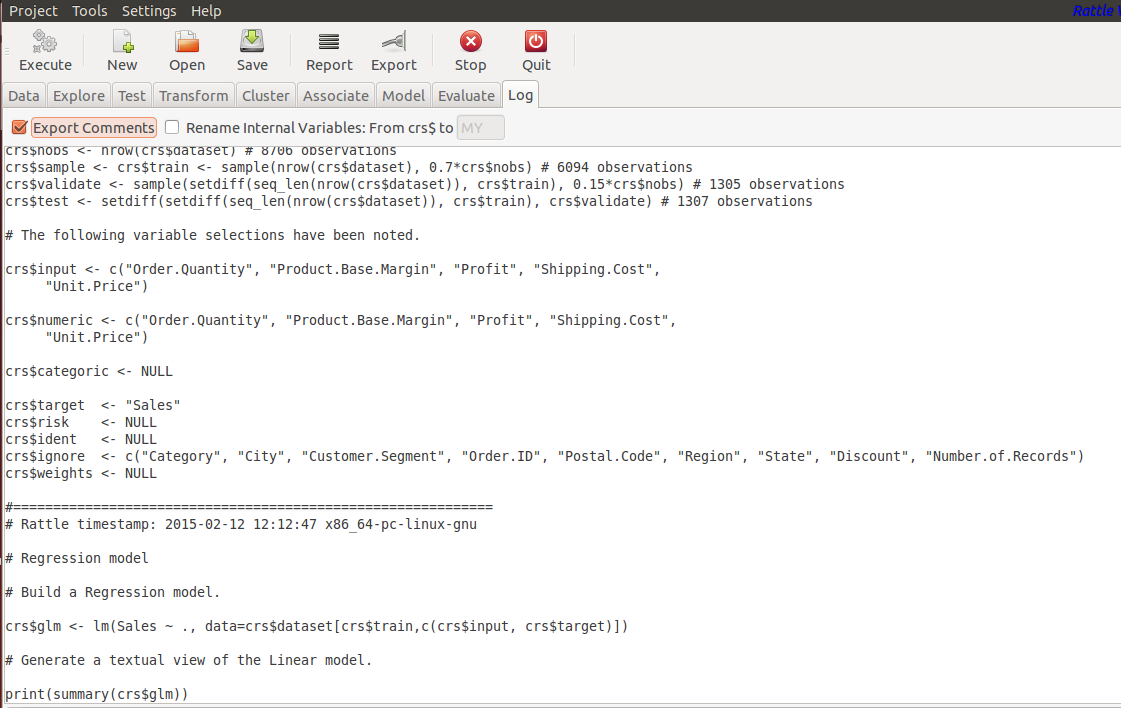
- Logs: Whatever actions you are performing in Rattle, It’ll automatically generate the source code of the action in log tab which you can use later once you have final your data, model and then use same code for the production purpose.
You can see how powerful Rattle is, You can perform various type of data mining operation. You don’t need to worry about the coding part, major part is what is your use-case, what operation need to perform, which model is best suited for you.
Hope this blog will help you to give a basic idea about the rattle.