In the modern data ecosystem, speed and efficiency are paramount. Whether you’re building real-time analytics pipelines or scaling distributed systems, the bottleneck often lies in data serialization and transport. Enter Apache Arrow Flight—a high-performance RPC framework designed to move large datasets efficiently using the Arrow memory format.
What is Apache Arrow Flight?
Apache Arrow Flight is a high-performance RPC framework designed for fast data transfer built on top of the Apache Arrow columnar memory format. It addresses the bottlenecks of traditional data exchange methods (like REST or JDBC/ODBC) by enabling efficient, parallel, and zero-copy streaming of Arrow-formatted data between systems.
Why Arrow Flight?
Traditional data transfer protocols like REST or gRPC often struggle with large tabular datasets due to serialization overhead. Apache Arrow Flight solves this by:
- Eliminating serialization bottlenecks via Arrow’s columnar in-memory format.
- Using gRPC under the hood for fast, scalable communication.
- Supporting parallel data streams, enabling high-throughput transfers.
This makes it ideal for use cases like:
- Distributed query engines
- ML model training pipelines
- Real-time dashboards
- Data lake integrations
Architecture Overview
Here’s a simplified view of Arrow Flight’s architecture:
Apache Arrow Flight Architecture
1. Client-Server Model
Arrow Flight uses a gRPC-based client-server architecture where:
- Flight Server hosts data endpoints
- Flight Client connects to the server to request or send data
2. Core Components
- Flight Server
- Implements Arrow Flight service
- Hosts endpoints for data access
- Can support multiple parallel streams
- Flight Client
- Initiates requests to the server
- Uses descriptors to identify datasets
- Retrieves data using tickets
- FlightDescriptor
- Identifies the dataset or query
- Can be a path or command (e.g., SQL query)
- FlightInfo
- Metadata about the dataset
- Includes schema, endpoints, and tickets
- Flight Stream
- Token used to retrieve data
- The actual data transfer channel using Arrow RecordBatches.
How It Works
- Client sends a FlightDescriptor to the server.
- Server responds with FlightInfo, including endpoints and schema.
- Client initiates a FlightStream to fetch or upload data.
- Data is transferred as Arrow RecordBatches, avoiding costly serialization.
This design allows for zero-copy reads, parallelism, and streaming, making it ideal for high-performance data systems
Code Snippet: Building a Simple Flight Server and Client
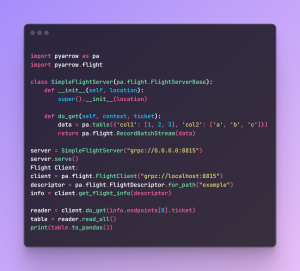
Arrow Flight Code Snippet
Performance Benchmarks
Arrow Flight has shown 10x–100x performance improvements over traditional REST APIs for large datasets. This is due to:
- Columnar format: Optimized for CPU cache and vectorized operations.
- Streaming: Avoids loading entire datasets into memory.
- Parallelism: Multiple streams can be used simultaneously.
Integration Possibilities
Arrow Flight integrates seamlessly with:
- Apache Spark: For distributed data processing.
- Pandas & NumPy: For data science workflows.
- DuckDB & Dremio: For in-memory analytics.
- Cloud-native systems: Via gRPC and TLS support.
Conclusion
Apache Arrow Flight is a game-changer for data engineers and system architects looking to optimize data movement across distributed systems. Its combination of Arrow’s efficient memory format and Flight’s RPC capabilities makes it a powerful tool for building scalable, high-performance data platforms.
If you’re working with large datasets, real-time pipelines, or distributed analytics, it’s time to give Arrow Flight a serious look.