
Designing Scalable AI Systems: RAG vs Long Context Trade-offs Explained
Introduction
Every LLM you’ve ever used is stuck in the past. It knows everything up to its training cutoff and nothing after. It also does not know about your internal documents,your private codebase,or what just happened 5 mis ago.
So if you want a model to actually be useful in a real time production environment,you have to address one problem that is how do you get the right data into the model at the right time?
Two approaches exist. One is an engineering solution. The other is more of a brute-force move. Both work. Both have trade-offs. And right now as context windows is hitting a million-plus tokens, it is worth asking whether the engineering solution is still needed?
What is RAG (Retrieval Augmented Generation)?
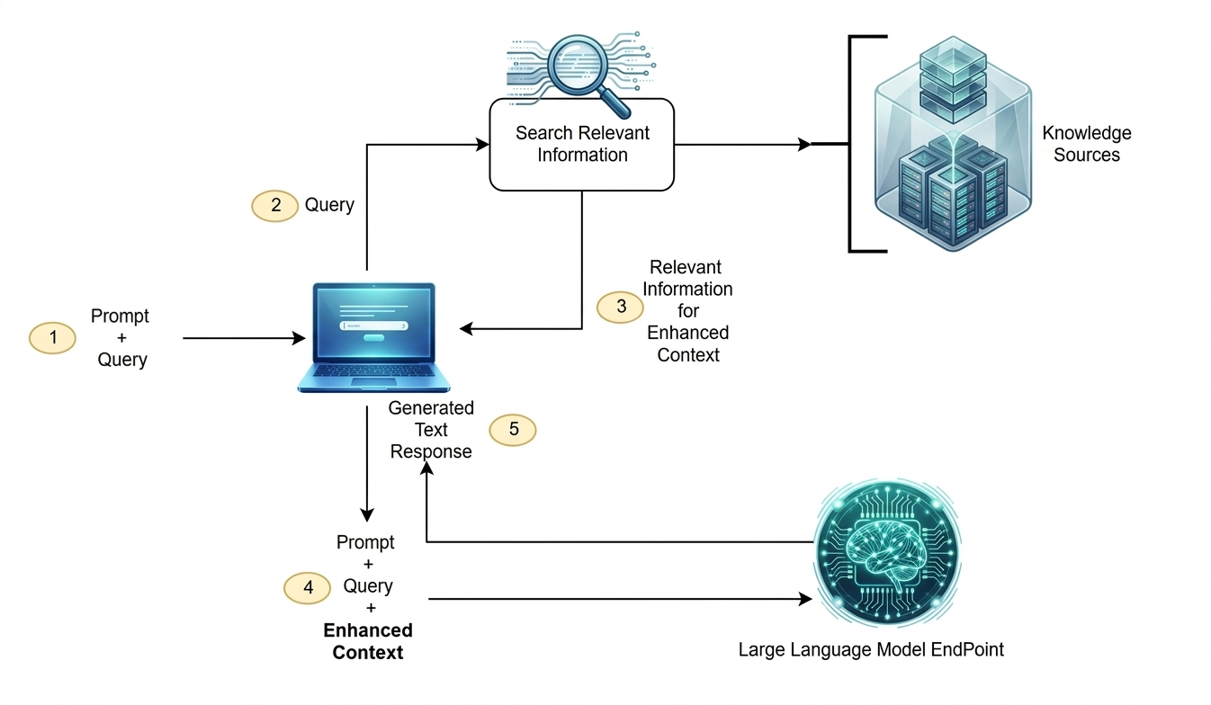
RAG architecture diagram
RAG is the classic solution. It works by taking your documents, PDFs, codebases, books, whatever and chunk them into smaller pieces.These chunks then go through an embedding model,that converts them into vectors (long arrays of numbers). These vectors the gets stored in a dedicated vector database and when a user asks a question, the system does the semantic search against that database to retrieve the most relevant chunks, then injects them into the model’s context window alongside the user’s query.
The model sees: your question + retrieved snippets. It answers from there.
It works. But it depends entirely on one thing going right: the retrieval step actually returning the correct chunks.
What is Long Context?
Long context skips the whole database setup. You just dump your documents straight into the context window and let the model’s attention mechanism find what it needs.
For years this wasn’t practical. Early LLMs had 4K token context windows. You couldn’t fit a long document in there.
That’s changed now.Some models today handle a million tokens or more.A million tokens is roughly around 700,000 words,enough for the entire Lord of the Rings trilogy and The Hobbit,with space left over.
So the obvious question: if you can just paste all your docs into the prompt, why bother with embedding models and vector databases at all?
Three Reasons Long Context Wins-
1. Infrastructure collapses to almost nothing: A production RAG setup has a lot of moving parts. You need a chunking strategy. You need an embedding model to encode the data. You need a vector database to store it. You need a reranker to sort results. You need to keep all the vectors in sync as your source documents change.
Any of those pieces can fail. Most eventually do.
Long context removes all of it. The architecture becomes: get the data, send it to the model. That’s the whole stack.
2. No retrieval means no silent failures: RAG has a failure mode that’s easy to miss: silent failure. The answer exists in your data. The model just never sees it because the retrieval step returned the wrong chunks.
Semantic search is probabilistic. For all sorts of reasons — chunking decisions, embedding quirks, query phrasing — the right document might not rank high enough to make the cut.
With long context, there’s no retrieval step. The model sees everything.
3. It can reason across the whole document, not just fragments: Here’s one RAG genuinely can’t handle well: questions that require comparing two complete documents.
Say you have a product requirements doc and a set of release notes. You ask: which security requirements were left out of the final release?
RAG’s vector search will find chunks about security and chunks about requirements. It cannot retrieve the gap between them. The model never sees enough of either document to spot what’s missing.
Long context solves this by dropping both full documents into the window. The model has everything it needs to do the comparison.
Three Reasons RAG is Still Around
1. Reprocessing everything on every query is expensive: If your file or documents has 500 pages, that’s roughly 250K tokens. Every time a user asks a question, you’re asking the model to process all 250K tokens again from scratch.
RAG pays that processing cost once at indexing time. After that, retrieval is cheap.
Prompt caching offsets some of this for static documents, but for data that changes frequently, you’re paying full price every time.
2. Bigger context windows don’t always mean better recall: There’s a reasonable assumption that if data is in the context window, the model will use it. Research says otherwise.
As context grows — especially past 500K tokens — the attention mechanism gets diluted. A specific paragraph buried in the middle of a 2,000-page document often gets missed or hallucinated around.
RAG sidesteps this by giving the model less to look at. Retrieve the top five relevant chunks, and you’ve removed the haystack. The model focuses on the signal instead of drowning in noise.
3. Enterprise data doesn’t fit in any context window: A million tokens sounds large until you’re dealing with an actual enterprise data lake. Those are measured in terabytes, sometimes petabytes.
No context window can hold that. If your dataset is effectively infinite, you need a retrieval layer to filter it down to something that fits. There’s no way around it.
So Which One Should You Use?
Bounded dataset, complex reasoning across the full thing a legal contract, a specific book, a single codebase? Long context. Simpler setup, better global reasoning.
Massive, constantly growing, enterprise-scale dataset? You still need RAG for that. The vector database isn’t dead. It’s just handling a different problem.
Most real setups probably end up using both at different layers anyway.
Conclusion
The debate between RAG and long context is less about which approach is better and more about what you’re actually trying to do.
Long context genuinely does simplify the stack and handles whole-document reasoning better than RAG ever will. But it doesn’t make the infinite enterprise dataset problem disappear, and it doesn’t fix the fact that you’re reprocessing the same documents over and over.
RAG has a real overhead cost. It also has a retrieval failure rate that’s easy to underestimate. But for large, dynamic data at scale, nothing else currently works.
Pick the one that fits your data size and update frequency or figure out where they need to coexist.
