
How Rack Awareness in Amazon MSK Saved $36K/Year for a Leading AdTech Company
Introduction
Building and deploying applications that use Apache Kafka for real-time data processing is made simple with Amazon MSK (Managed Streaming for Apache Kafka), a fully managed service by AWS. Rack awareness is one overlooked configuration change that can greatly increase fault tolerance and cost effectiveness, even though MSK takes care of a large portion of the infrastructure for you.
MSK Rack Awareness
In this blog, we will explore what rack awareness is, how Kafka or MSK uses it, and how configuring your Kafka consumers to read from the closest replica rather than the partition leader can result in major cost savings. We did this activity for the Global Advertising Management Platform client, a powerhouse in advertising and connected TVs. With a state-of-the-art Connected TV Advertising Management Platform, they needed a trusted partner to control their cloud bills. In our case, savings were almost $100 per day in the cross-AZ data transfer bill. Let’s get started and explore the solution.
What is Rack Awareness in Kafka?
Rack awareness feature spreads replicas of the same partition across racks (racks or availability zones). Enabling Kafka consumers to fetch data from the closest available replica lowers latency and cross-AZ traffic and guarantees that a failure in one place won’t destroy all partition replicas.
Advantages Of Rack Awareness
- High Availability: Even if an entire AZ fails, partitions continue to function. Data can be fetched from other AZ brokers.
- Resilience: No single AZ becomes a single point of failure.
- Low Data Transfer Costs: Consumers will fetch the data from the replicas in the same AZ, which will result in no cross-AZ data transfer costs.
- Performance: Reading data from the same AZ brokers/replicas will result in low latency and high performance.

Advantages of Rack Awareness
How Amazon MSK Handles Rack Awareness
Amazon MSK automatically maps brokers to different Availability Zones. Each broker has a broker. Rack property set by MSK based on its AZ.
Let’s take a look at the example of the Oregon region in AWS :
Broker 1 → us-west-2a Broker 2 → us-west-2b Broker 3 → us-west-2c Broker 4 → us-west-2a . . . . Broker 15 → us-west-2c
When a topic is created with a replication factor of 3, MSK ensures that the replicas are distributed across different AZs.
Enabling Closest Replica Fetching
While MSK takes care of broker rack assignments, to fully leverage rack awareness, your Kafka consumers must be configured to fetch from the closest replica. This requires configuration changes on both the broker and consumer sides.
Broker Configuration
Enable the following property in your MSK configuration:
replica.selector.class=org.apache.kafka.common.replica.RackAwareReplicaSelector
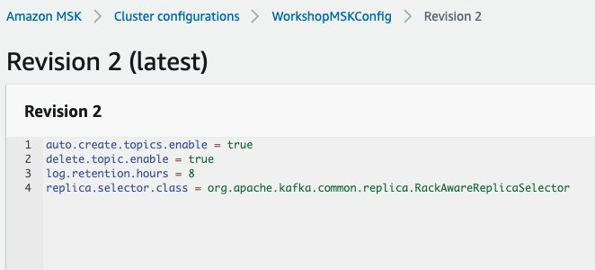
msk configuration
MSK will take ~15 minutes to apply this configuration, but it also depends on the cluster size and data. During this time, the cluster remains fully functional, so it’s completely safe to apply this change anytime.
Before enabling this configuration on the cluster:

Before applying the configuration
After enabling:

After applying the configuration
We can see the property is now applied on cluster, and it now enables Kafka consumers to fetch data from the closest replica instead of always contacting the partition leader, reducing cross-AZ data transfer and latency. The broker uses this value to find the preferred read replica.
Reference: https://docs.aws.amazon.com/msk/latest/developerguide/msk-configuration-properties.html
Consumer Configuration
Set the consumer’s rack ID dynamically by using EC2 Instance Metadata Service (IMDS). In our case, we run the consumer on an Amazon EMR cluster, and we retrieve the AZ ID at runtime using AWS Secrets Manager. This AZ ID is then passed to the client.rack property in the Kafka consumer configuration. For example:
client.rack=us-west-2b
This tells the Kafka client, in our case Java AWS SDK, to prefer replicas in the same AZ. Check out client-side configuration: https://kafka.apache.org/35/documentation.html#consumerconfigs_client.rack
Verifying Rack Awareness
You can verify the broker rack configuration using:
./kafka-configs.sh --describe --entity-type brokers --bootstrap-server <broker-endpoint>
To check that clients are reading from the closest replica, you can monitor network usage patterns or use Kafka metrics via CloudWatch dashboards to identify shifts in traffic distribution after enabling rack awareness.
Before enabling this optimization, most of our consumer traffic went to the partition leader, which often resided in a different AZ.
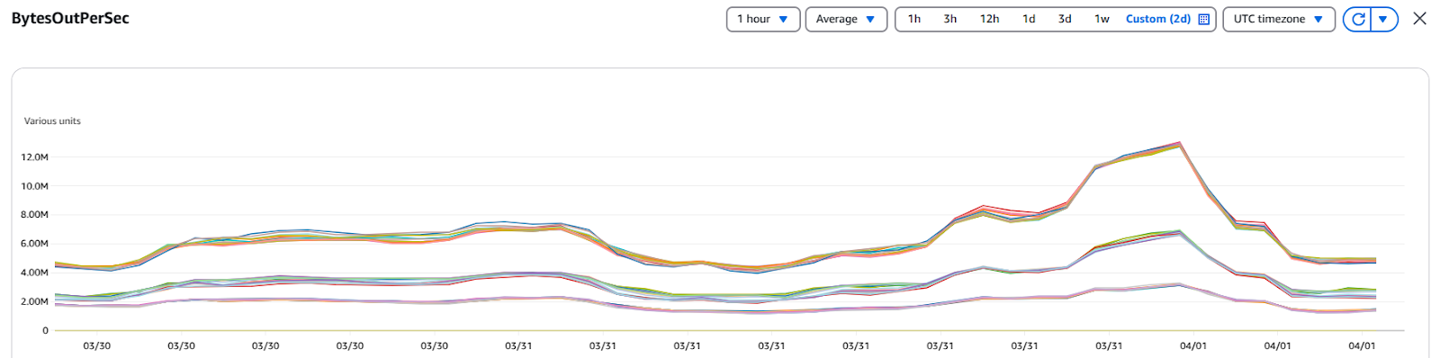
Cloudwatch Metrics Before Enabling Rack Awareness
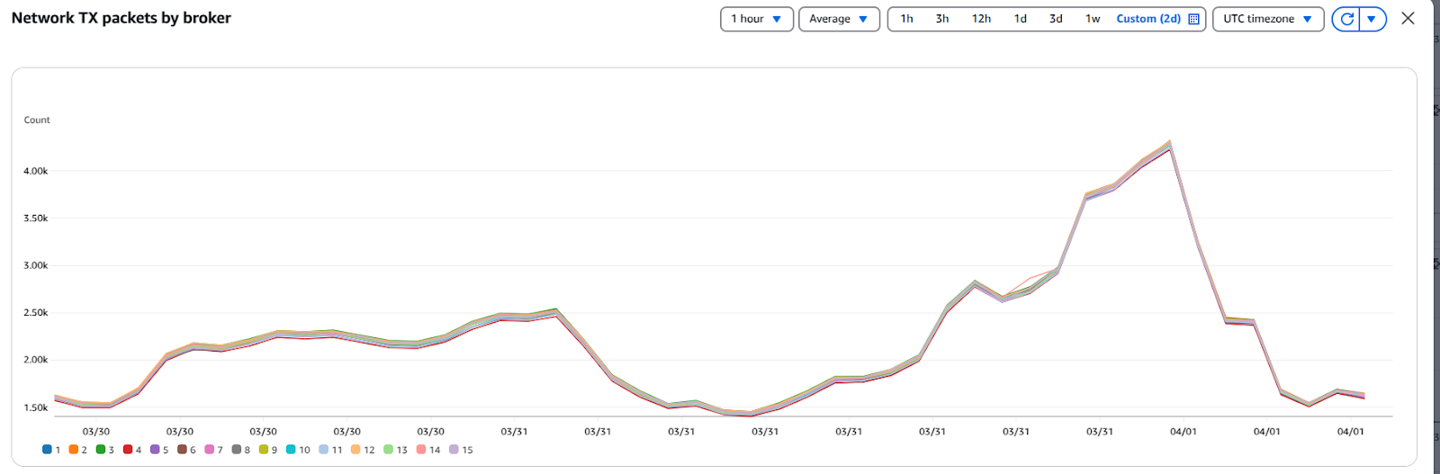
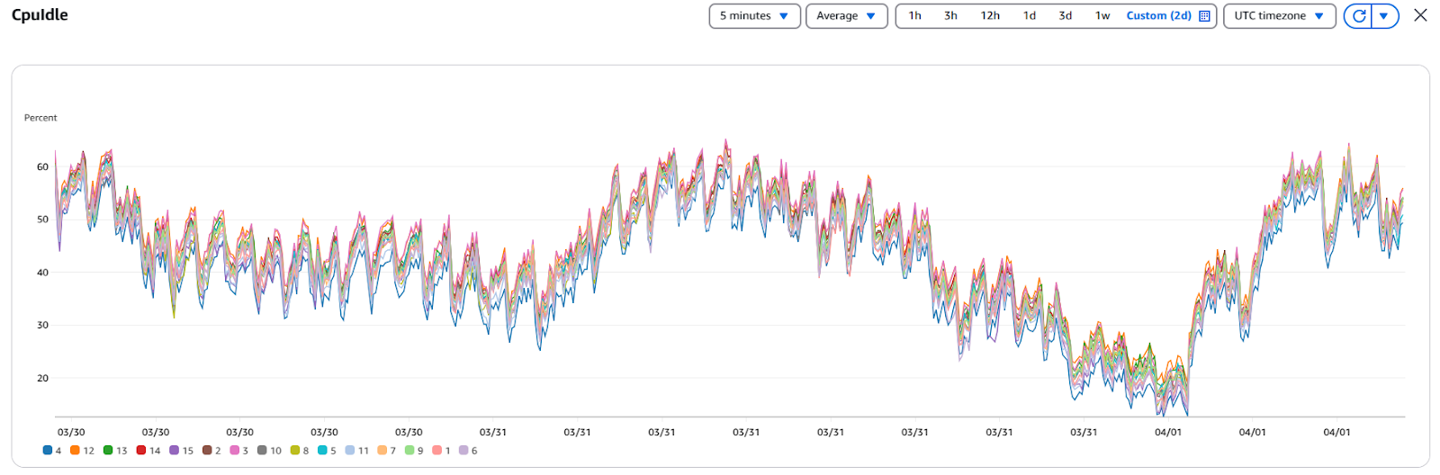
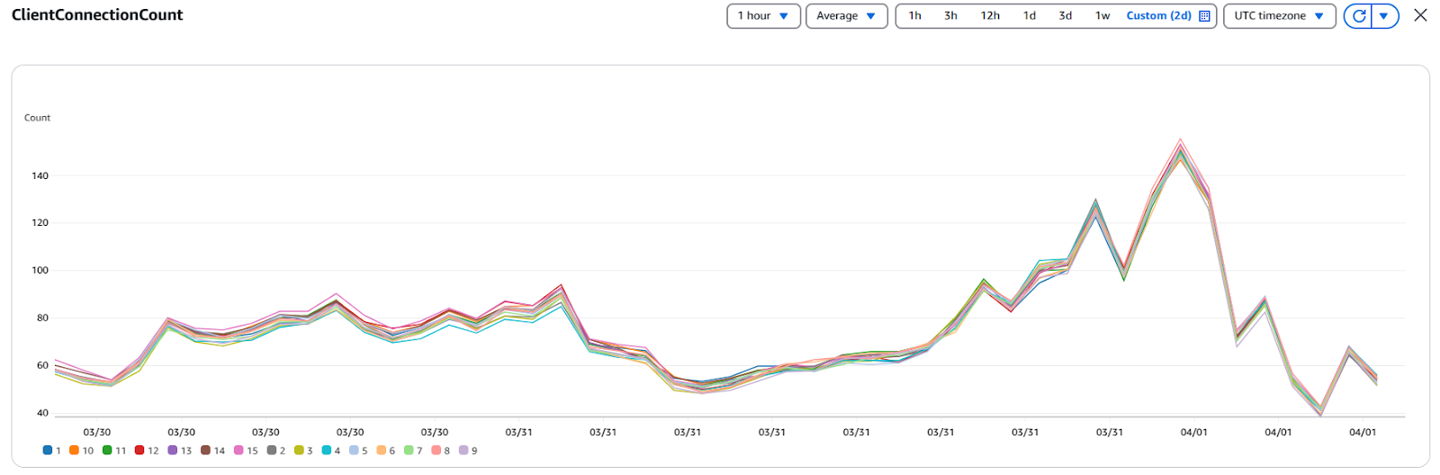
After implementing rack-aware fetching:
- Consumers began reading from in-AZ replicas, and then we observed different cloudwatch metrics patterns now. The data flow and network packet transactions were high on the brokers, which were in the same AZ as of consumer.

Cloudwatch Metrics After Enabling Rack Awareness
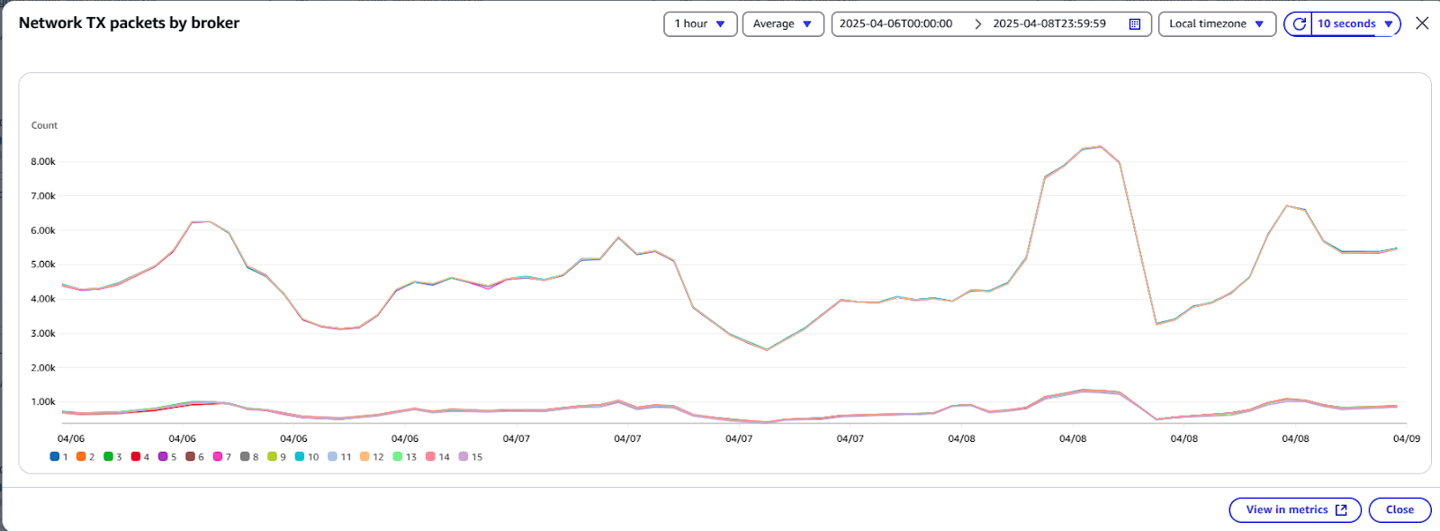
- Cross AZ Data Transfer costs dropped substantially. We now save approximately $100 per day.
- This adds up to $36,500/year in cost savings for just one use case, showing the real financial benefit of deep platform optimization.
Best Practices
- Use at least 3 AZs: Spread brokers across 3 AZs for better fault tolerance.
- Set proper replication factor: Ensure at least 3 replicas per partition.
- Enable rack-aware replica selector: On both brokers and clients.
- Fetch AZ dynamically: Especially if using EMR or autoscaling groups.
- Monitor with CloudWatch: Set up dashboards to track data transfer and broker traffic.
Conclusion
Rack awareness in Amazon MSK is not just a high availability or resilience feature—it’s a powerful cost-saving mechanism when configured properly. By enabling consumers to fetch from the closest replica, organizations can reduce latency and save significantly on cross-AZ data transfer charges.
If you’re using Amazon MSK or Open Source Kafka running on EC2 or some other platform and haven’t looked into rack-aware replica fetching, now is the time. Small configuration changes can lead to big wins in both performance and your AWS bill. Partnering with a managed cloud services provider like TO THE NEW can help you adopt the right architecture and strategies to unlock these savings and improve your Kafka workloads on AWS. Our AWS Certified Architects and DevOps Engineers are committed to saving you time and resources while enhancing business efficiency and reliability.


