
Incident Management in Cloud MSP: From Alert to Resolution (A Real World Approach)
1. Introduction
In a Cloud Managed Services Provider (MSP) ecosystem, incident management is a critical function that directly impacts service availability, SLA adherence, and customer experience.
With modern cloud architectures (AWS, hybrid, microservices), incidents are no longer isolated—they are multi-layered and interdependent. This demands a structured, fast, and practical approach to incident handling.
This paper presents a real-world, operations-driven framework for managing incidents effectively—from detection to resolution and prevention.
2. Incident Management in Cloud MSP
Incident Management is:
The process of restoring normal service operations quickly while minimizing business impact.
Cloud-Specific Complexities
- Dynamic infrastructure (auto-scaling, ephemeral instances)
- Multiple alert sources (metrics, logs, traces)
- External dependencies (CDNs, APIs, third-party services)
- Result: Higher alert volume + faster response expectations
3. Incident Lifecycle (Operational Flow)
Below is a simplified real-world lifecycle followed in MSP environments:
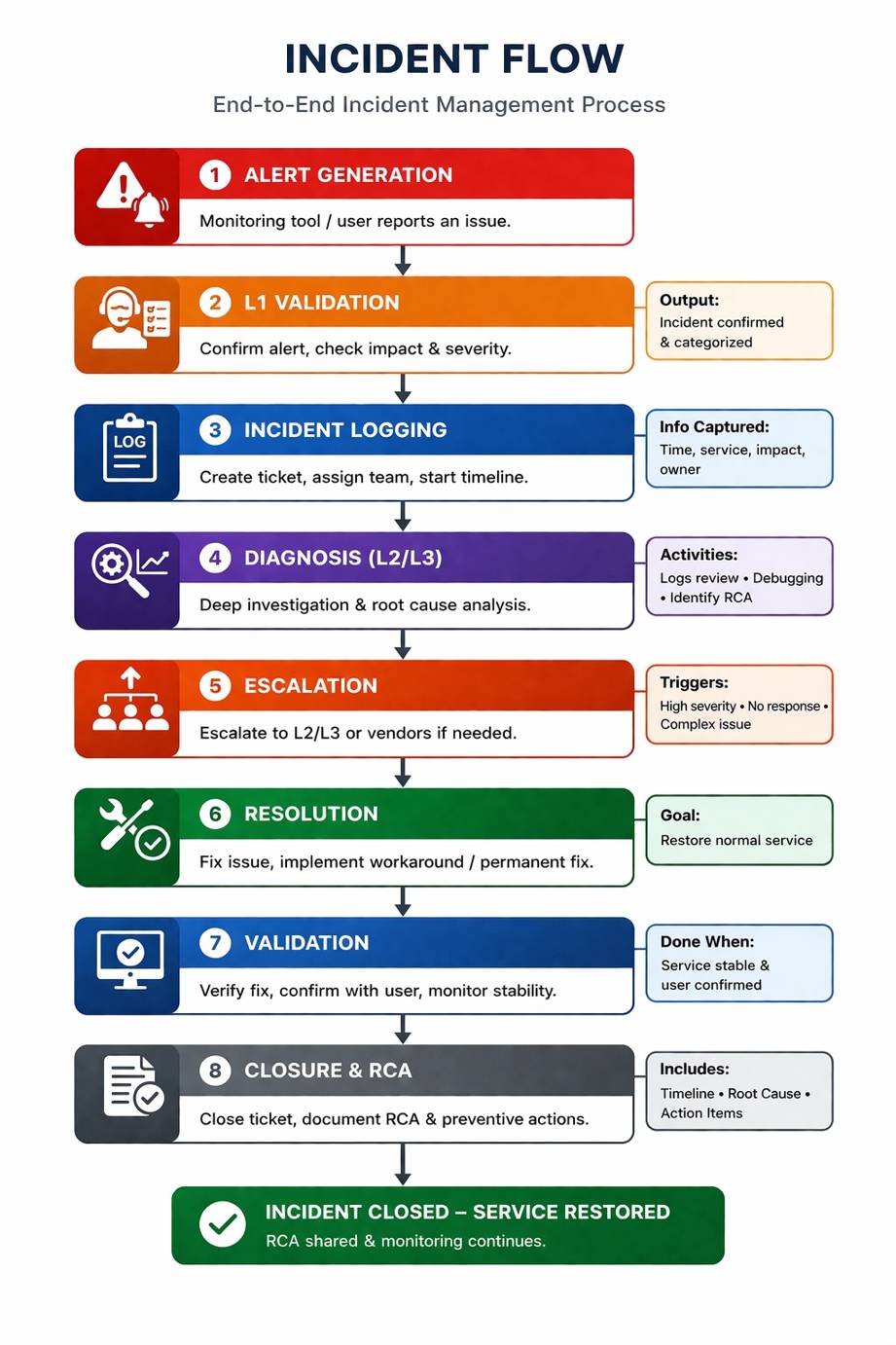
Incident Flow
Step-by-Step Flow
a. Alert Generation
Monitoring tools (CloudWatch, Datadog, Prometheus) trigger alerts based on thresholds like CPU, latency or error spikes.
b. L1 Validation
- Check false positives
- Identify known issues
- Perform initial triage using runbooks
c. Incident Logging
Ticket creation in Jira/ServiceNow with:
- Severity (P1–P4)
- Impact scope
- Affected services
d. Diagnosis (L2/L3)
- Log analysis (ELK, Cloud logs)
- Metric correlation
- Dependency validation
e. Escalation
Defined path:
- L1 → L2 → L3 → Engineering
f. Resolution
Typical actions:
- Restart services
- Scale infrastructure
- Rollback deployments
- Fix configurations
g. Validation
Ensure system stability and monitor for recurrence.
h. Closure & RCA
- Root Cause Analysis
- Preventive action planning
4. Severity Classification (Practical MSP Model)
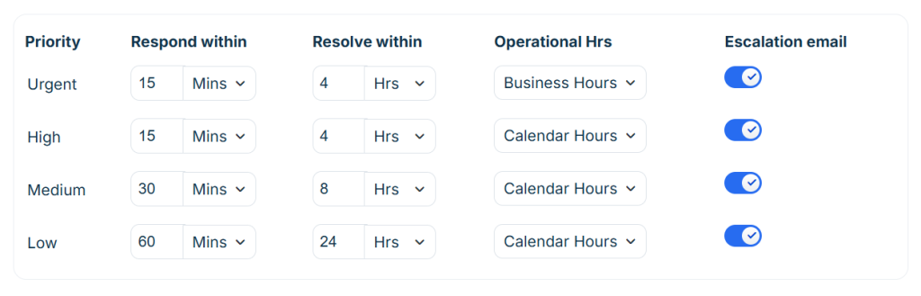
SLA
5. Key Challenges in MSP Environment
a. Alert Noise
Too many alerts → delayed response
Solution: Threshold tuning, alert correlation
b. No Standard Runbooks
Dependency on individuals
Solution: Documented SOPs for L1/L2
c. Cross-Team Dependencies
Infra + App + Network overlap
Solution: Clear ownership model
d. SLA Pressure
High expectation for rapid resolution
Solution: Automation + proactive monitoring
e. Recurring Incidents
Weak RCA leads to repetition
Solution: Structured PIR (Post Incident Review)
6. Best Practices (Real MSP Experience)
- Unified Monitoring: Metrics + Logs + Traces
- Runbook-Driven Operations: Faster L1 resolution
- Automation First Approach: Auto-remediation (restart, scale)
- Clear Communication: Timely stakeholder updates
- Continuous Improvement: RCA → Prevention
7. Real-World Incident Example
Incident: API latency spike in production
Execution Flow:
- Alert triggered via monitoring tool
- L1 validated → raised P2 incident
- L2 identified DB connection saturation
- Immediate fix: Scale DB resources
- Permanent fix: Optimize connection pooling
Outcome:
- SLA met
- RCA documented
- Monitoring enhanced
8. Key Metrics (MSP Performance Indicators)
- MTTD – Mean Time to Detect
- MTTR – Mean Time to Resolve
- SLA Compliance %
- First Response Time
- Incident Recurrence Rate
9. Conclusion
Incident management in a Cloud MSP is not just an operational necessity; it is a business-critical capability.
A mature system ensures:
- Faster recovery
- Reduced downtime
- Improved customer trust
- From a Service Delivery standpoint, the focus must evolve from:
Reactive resolution → Proactive prevention
