
Migrating MySQL Data to Elasticsearch: A Practical Guide
Introduction
Elasticsearch has become a go-to choice for building fast, intelligent search experiences. But what if your source of truth is a relational database like MySQL? In this blog, we’ll walk through how we migrated structured relational data into Elasticsearch using Python — with company_registry as a working example.
Why Migrate from MySQL to Elasticsearch?
MySQL is great for transactional workloads (OLTP) but when it comes to full-text search, autocomplete, typo tolerance, or complex filtering, it struggles. Elasticsearch shines here with:
- Flexible mappings for search fields
- Support for text analysis (stemming, synonyms, phonetics)
- Millisecond-level query performance
- Easy scaling for large datasets
- To bridge the gap, we need a migration pipeline that fetches data from MySQL, transforms it, and indexes it into Elasticsearch.

pipeline flow diagram
Setting Up the Basics
We’ll use:
- MySQL as the data source
- Elasticsearch (v8+) as the search engine
- Python + official Elasticsearch client for migration
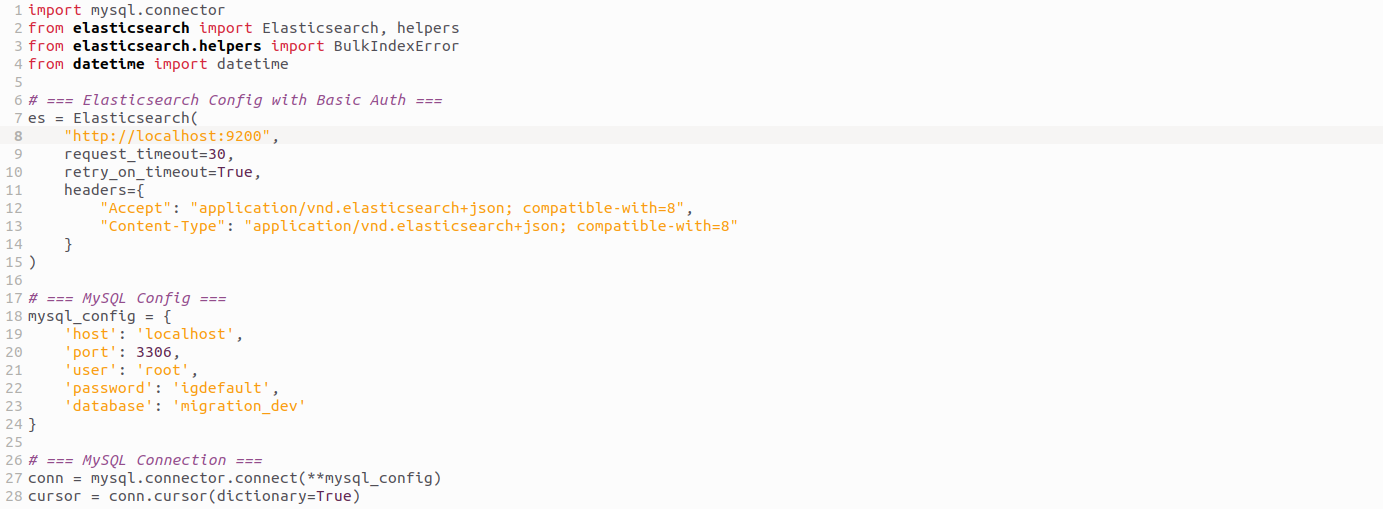
Here we set up secure connections to both MySQL and Elasticsearch
Deleting Old Indices
Before creating new indices, it’s a good practice to remove any outdated ones. This prevents mapping conflicts or duplicate records.This ensures your migration always starts on a clean slate.

Delete index Data
Creating Elasticsearch Mappings
Unlike MySQL, Elasticsearch requires you to define how fields should be indexed. For our company_registry, we use the following mapping:
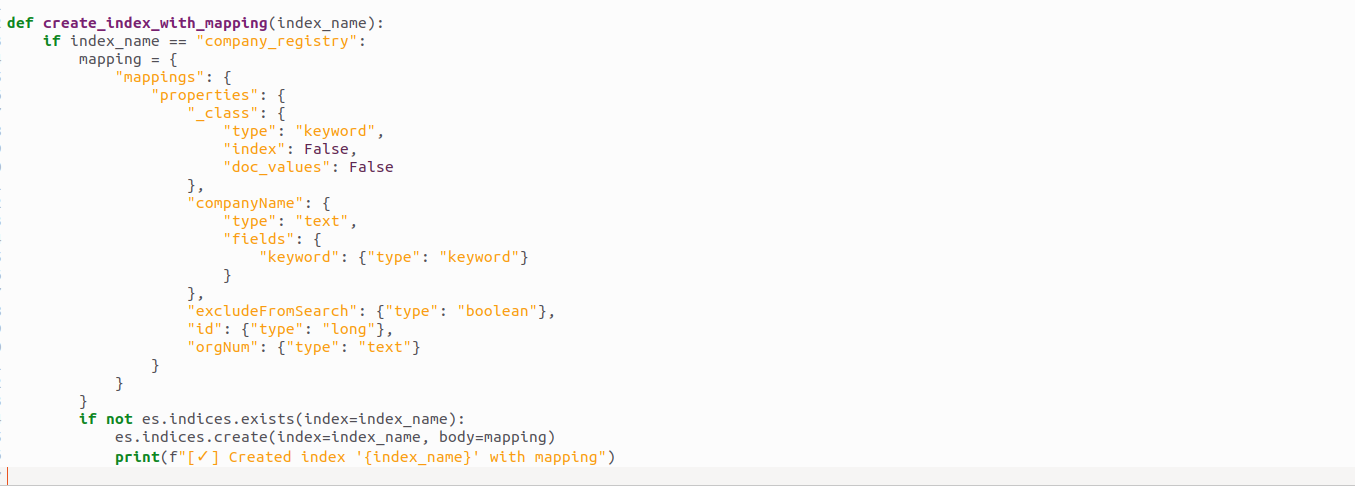
company registry index
This ensures that:
- companyName supports both full-text and exact match queries.
- excludeFromSearch is a boolean flag.
- id is stored as a numeric long.
Transforming the Data
Raw MySQL data doesn’t always map directly to Elasticsearch. We normalize fields before indexing:

Transforming Data
Fetching and Indexing Data
Here’s the migration logic for company_registry:
- Fetch rows from MySQL
- Apply transformations
- Push them into Elasticsearch in bulk (faster than single inserts)
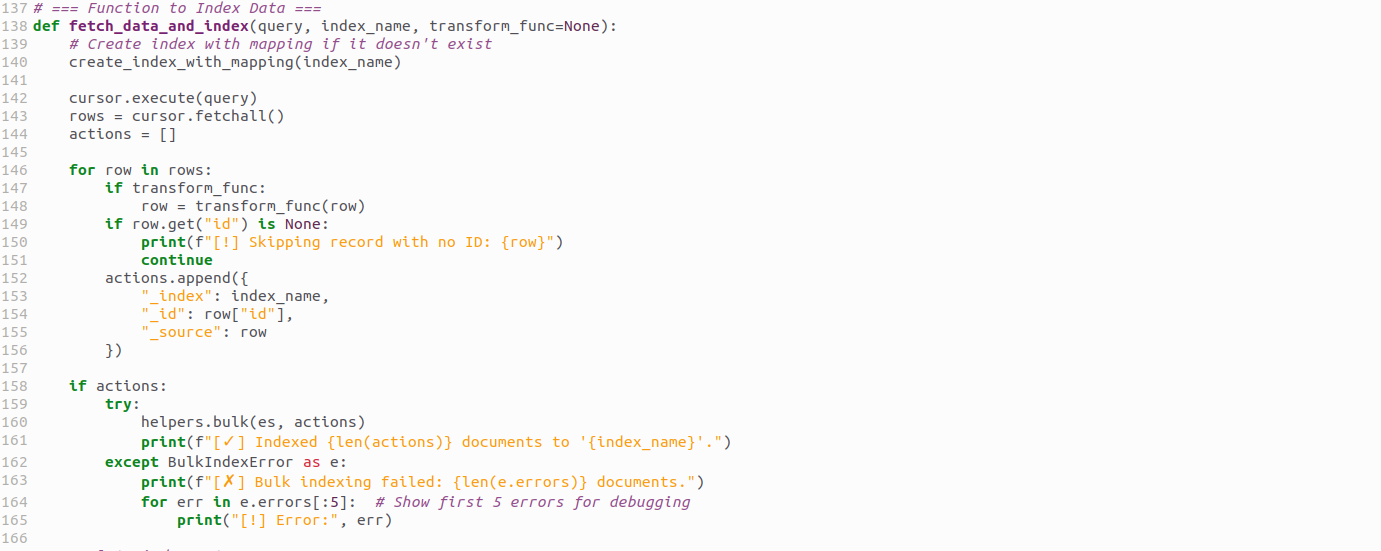
Fetching and Indexing Data
Running the Migration
Finally, execute the migration:

Running Migration
When run, this script will:
- Delete any old index (if needed)
- Recreate the index with proper mappings
- Migrate rows from MySQL into Elasticsearch
Key Lessons Learned
- Always define explicit mappings otherwise ES may misinterpret your fields.
- Transform booleans & dates — MySQL often stores them as TINYINT or DATETIME, which ES won’t parse correctly without conversion.
- Use bulk indexing for performance.
- Index per table — each MySQL table can map to its own index (e.g., company_registry, user, etc.).
Conclusion
By building a simple migration pipeline with Python, we successfully moved company_registry data from MySQL into Elasticsearch. Once indexed, the data can be leveraged for autocomplete, fuzzy search, typo handling, and blazing-fast queries — things MySQL alone struggles with.This approach is flexible: just extend the transformation functions for other tables like user or company_order and you have a reusable ETL pipeline for all your entities.


