
Mystery Behind S3 Costing
AWS S3 is a Simple Storage Service provided by Amazon that can store any amount of data, at any time, from anywhere on the web. It is one of the most heavily used AWS Service. It is not just used as a storage service, it is also used for hosting websites with static content. It is easily integrated with many other AWS services and tools.
When it comes to S3 Pricing, there are basically three factors that are used to determine the total cost of using S3:
- The amount of storage.
- The amount of data transferred every month.
- The number of requests made monthly.
In most cases, only the storage amount and data transferred make much of a difference in cost. However, in the case of data transfer that occurs between S3 and AWS resources within the same region, the data transfer costs is zero.


Use-Case
While analyzing S3 costs I have always wondered how these costs are actually calculated and if there is a way one could actually match these costings with the billing. The blog shows how to analyze S3 bucket logs to find out the following details about the buckets hosted in S3:
- Total number of each type of requests received by each bucket.
- Total size on each bucket.
- Total data transfer from S3.
Requirements:
- S3 bucket logging should be enabled on each bucket.
- Python ( boto module )
- AWS Account ( Access Key Id, Secret Key Id)
- s3cmd
Steps
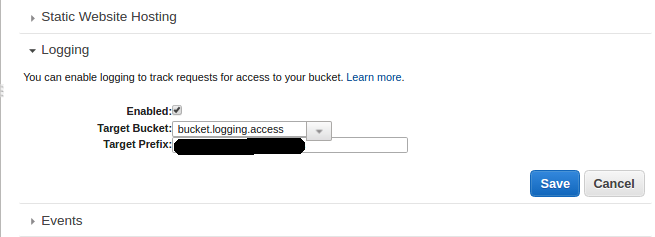
1. Enable bucket-logging on each bucket.
Log into AWS console, and go to S3 service. Select the bucket and under properties, select logging. Select enabled in logging and provide a name for the target bucket. The target bucket stores the logs for each bucket. Each bucket has a separate folder where its logs are stored.
2. Download and merge the logs
Install s3cmd using command apt-get install s3cmd, and configure it by providing the AWS Access Key and AWS Secret Key in the .s3cfg file created in the home directory of the user.
Following command is used to download logs from the log-bucket:
s3cmd sync –delete-removed –preserve s3://bucket.logging.access/ <Path/to/store/logs> –exclude “*” –include “test-bucket2016-06*”
- “test-bucket2016-06*” is a string that filters logs for the bucket, named “test-bucket”, for the month of JUNE in year 2016.
- filters like –include and –exclude can be used to download specific logs from logging-bucket.
- –preserve is a switch that prevents the logs from being overwritten, so newly created logs are only added to the log folder
Concatenate logs of all buckets into one file. So that all our further operations can be performed on one specific file. This concatenation can be carried out using the “cat” command.
cat /path/to/log1 /path/to/log2 /path/to/log3 > /path/to/final_log_file
3. Format of the logs
The logs for PUT request are shown in this format:
The logs for LIST request are shown in this format: **Important point to note is that a LIST request is logged as REST.GET.BUCKET in logs
**Important point to note is that a LIST request is logged as REST.GET.BUCKET in logs
The logs for COPY request are shown in this format:
The logs for GET request are shown in this format:
The logs for HEAD request are shown in this format:
4. Calculating the number of requests
A simple grep function with wc -l filter is used to count the number of each type of request in the logs. Following commands are used to count each type of request:
- PUT: grep REST.PUT </path/to/final_log_file> | wc -l
- POST: grep REST.POST </path/to/final_log_file> | wc -l
- LIST: grep REST.GET.BUCKET </path/to/final_log_file> | wc -l
- COPY: grep REST.COPY </path/to/final_log_file> | wc -l
- GET: grep REST.GET </path/to/final_log_file> | wc -l
- HEAD: grep REST.HEAD </path/to/final_log_file> | wc -l
As it happened in my case, calculating number of GET and LIST requests with the following methods (wrong method):
- GET: grep GET </path/to/final_log_file> | wc -l
- LIST: grep LIST </path/to/final_log_file> | wc -l
gave me results that were not even close to the number of requests shown in my billing, so it is important to know that, in order to calculate the number of GET requests we need to subtract, the number of LIST requests from the number of GET requests that we calculated. As the LIST request is logged as a type of GET request only. A LIST request is logged as REST.GET.BUCKET whereas a GET request is logged as a REST.GET in the logs.
Following is the snippet, of the code I used to calculate requests each bucket:
region_bucks=boto.s3.connect_to_region('ap-southeast-1')
list_bucket_bucks=region_bucks.get_all_buckets()
for a_bucks in list_bucket_bucks:
bucket_name_bucks=str(a_bucks)[9:-1]
print 'For Bucket : %s ' %(bucket_name_bucks)
post_bucks=subprocess.Popen("grep -r REST.POST /home/mayank/Desktop/s3_costing/s3_logs/access.log | grep "+bucket_name_bucks+" | wc -l",stdout=subprocess.PIPE,shell=True)
post_bucks_f,e=post_bucks.communicate()
print 'Number of POST request on %s : %s' %(bucket_name_bucks, post_bucks_f)
put_bucks=subprocess.Popen("grep -r REST.PUT /home/mayank/Desktop/s3_costing/s3_logs/access.log | grep "+bucket_name_bucks+" | wc -l",stdout=subprocess.PIPE,shell=True)
put_bucks_f,e=put_bucks.communicate()
print 'Number of PUT request on %s : %s' %(bucket_name_bucks, put_bucks_f)
list_bucks=subprocess.Popen("grep -r REST.GET.BUCKET /home/mayank/Desktop/s3_costing/s3_logs/access.log | grep "+bucket_name_bucks+" | wc -l",stdout=subprocess.PIPE,shell=True)
list_bucks_f,e=list_bucks.communicate()
print 'Number of LIST request on %s : %s' %(bucket_name_bucks, list_bucks_f)
copy_bucks=subprocess.Popen("grep -r REST.COPY /home/mayank/Desktop/s3_costing/s3_logs/access.log | grep "+bucket_name_bucks+" | wc -l",stdout=subprocess.PIPE,shell=True)
copy_bucks_f,e=copy_bucks.communicate()
print 'Number of COPY request on %s : %s' %(bucket_name_bucks, copy_bucks_f)
get_bucks=subprocess.Popen("grep -r REST.GET /home/mayank/Desktop/s3_costing/s3_logs/access.log | grep "+bucket_name_bucks+" | wc -l",stdout=subprocess.PIPE,shell=True)
get_bucks_f,e=get_bucks.communicate()
get_only=float(get_bucks_f) - float(list_bucks_f)
print 'Number of GET request on %s : %s' %(bucket_name_bucks, get_only)
head_bucks=subprocess.Popen("grep -r REST.HEAD /home/mayank/Desktop/s3_costing/s3_logs/access.log | grep "+bucket_name_bucks+" | wc -l",stdout=subprocess.PIPE,shell=True)
head_bucks_f,e=head_bucks.communicate()
print 'Number of HEAD request on %s : %s' %(bucket_name_bucks, head_bucks_f)
5. Calculating storage on each bucket
When we calculate the size of the bucket it is not always equal to the size it shows in the AWS billing, that is because the size is calculated by the data that AWS has charged you for, so far. Following is the formulae to calculate the total size shown on the present date:
(Total Size in GB / Total number of days in the month) * (Day of the month)
i.e In my case the storage was calculated to be equal to 5 GB on the 24th of the month and in the AWS billing it showed total size equal to 3.950 GB, so according to the formulae,
(5/30) * 24 = 4 GB, this gives me an error rate of 0.0125%.
Following is the snippet of code i used to calculate, current storage size:
import boto
from boto.s3.connection import Location
def sizeof_fmt(num):
for x in ['bytes','KB','MB','GB','TB']:
if num < 1024.0:
return "%3.1f %s" % (num, x)
num /= 1024.0
region=boto.s3.connect_to_region('ap-southeast-1')
list_bucket=region.get_all_buckets()
array=[]
t_size=0
for a in list_bucket:
bucket_name=str(a)[9:-1]
s3 = boto.connect_s3()
bucket = s3.lookup(bucket_name)
total_bytes = 0
print bucket_name
for key in bucket:
total_bytes += key.size
t_size=t_size+total_bytes
print sizeof_fmt(total_bytes)
total_size=sizeof_fmt(t_size)
TOTAL_SIZE=total_size[:-3]
import datetime
datetime=datetime.datetime.now()
day=datetime.day
print '\n'
size=(float(TOTAL_SIZE)/30) * float(day)
print 'Chargeable size as on current date : %s' %(size)
print '\n'
print 'Storage cost as on current date is : %s' %(float(size)*0.0295)
6. Calculate data transferred from s3
AWS charges for data transfer outside the region. It can be calculated using the logs, as the size of data transferred in each request is present in the log. Following is the snippet of a normal HEAD request, with data transfer size marked in it.
The above shown, request initiated a data transfer of 293 bytes. The data size is mentioned in the 15th column of the log. The total data size can be calculated using the following code:
datatransfer=subprocess.Popen("awk '{print $15}' /home/mayank/Desktop/s3_costing/s3_logs/access.log | awk '{ sum += $1} END {print sum/1024/1024/1024}'",stdout=subprocess.PIPE,shell=True)
datatransfer_f,e=datatransfer.communicate()
print 'Total data transfer is : %s GB' %float(datatransfer_f)
Hope this blog has given you a proper understanding, on how to analyze the S3 bucket logs to get detailed analyses of your buckets hosted in AWS S3.



Gives clarity around data storage calculation and how the cost can be evaluated. Way to go Mayank!