
Driving Efficiency and Cost Reduction: Kafka Migration to AWS MSK for a Leading Advertising Firm
Introduction
In the world of data management, companies seek to streamline operations and enhance scalability. One key journey involves migrating self-managed Apache Kafka clusters from AWS EC2 to Amazon MSK. We executed such a migration for a client with zero downtime, offering insights and strategies in this blog.
Motivations Behind Migration
- Scalability Limitations: Scaling self-managed Kafka clusters for increasing data volumes and processing demands was challenging, requiring manual intervention for deploying additional EC2 instances, configuring files, and rebalancing partitions.
- Operational Overhead: Self-managed Kafka system requires significant human efforts and knowledge to deploy, configure, and maintain effectively. Security patches, monitoring, and backup plans added to the administrative burden, diverting minds from real business requirements.
- Efficiency Issues: Underutilized resource utilization & over-provisioned capacity, resulted in unnecessary costs and operational inefficiencies.
- Upgrading Issues: Upgrading Kafka versions in self-managed environments was difficult and time-consuming, requiring careful planning, testing, and coordination to minimize blast radius and ensure compatibility with existing applications and infrastructure.
- Security and Compliance Reasons: Of course not upgrading the Kafka cluster resulted in many security & compliance issues. The Kafka version was old and had many security vulnerabilities.
Existing Setup and Cost Analysis
- Kafka Cluster Configurations: The setup included 15 Kafka nodes with m5.2xlarge instances, totaling around 200 TB of disk space. Apache Kafka Version: 0.8.2.
- Zookeeper Node Configurations: 3 Kafka Zookeeper nodes, using c5.xlarge instances with 100 GB disks, managed the Kafka cluster.
- Replication Factor in Kafka: The replication factor refers to the number of copies maintained for each Kafka topic partition across the cluster. In our setup, each message in Kafka was triplicated across 3 brokers, maintaining RF of 3.
- Inter-AZ Data Transfer Costs: Architecture was spanned across 3 AZs in the US-West-2 region on AWS for high availability. However, AWS imposes inter-AZ data transfer costs for communication between Kafka brokers located in different availability zones. The architecture, designed to ensure HA, inadvertently incurred substantial inter-AZ data transfer costs, contributing significantly to monthly AWS expenses.
Problem Statement
Adding all these factors & infrastructure was costing us monthly expenditures, totaling approximately 40,000 US Dollars. The primary cost driver was from inter-AZ data transfer charges, reflecting the substantial volume of data exchanged between Kafka brokers across availability zones. To address this issue, we explored migrating to Amazon MSK for benefits like high availability, quick scaling, and no data transfer costs between brokers across different AZs.
Open Questions
- What applications and other adjustments are necessary to support the new MSK cluster?
- How can we guarantee the performance of the MSK cluster meets our requirements?
- What MSK configurations are optimal for both production and non-production environments?
- How do we reset Data-pipeline offsets to ‘earliest’ before reading from MSK?
- Does MSK require any form of pre-warming before full-scale data transmission just like load balancers in AWS?
- What Rollback plans should be in place if issues arise post-switch to MSK?
While these questions might vary depending on your specific scenario, we will address them comprehensively throughout this blog.
Migration Overview Diagram
- Existing Setup
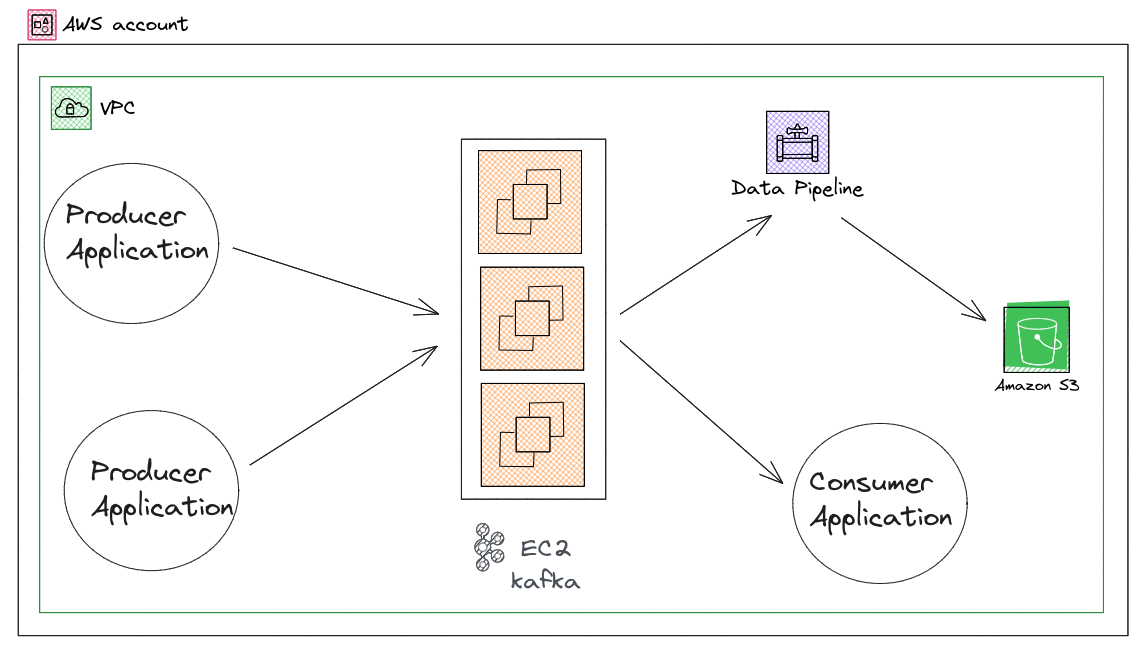
Existing AWS Setup
- During Migration
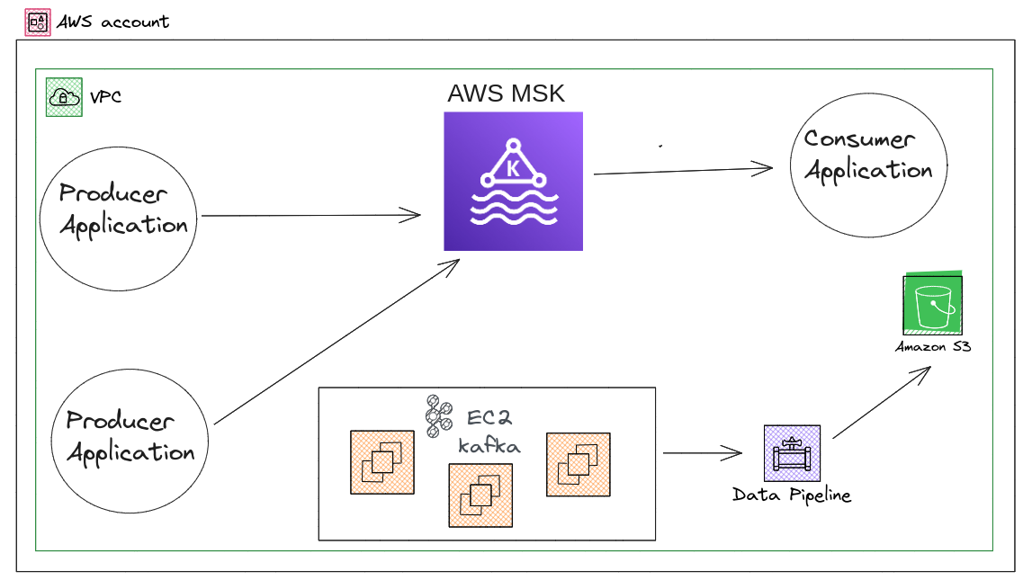
AWS account during migration
- Post-migration
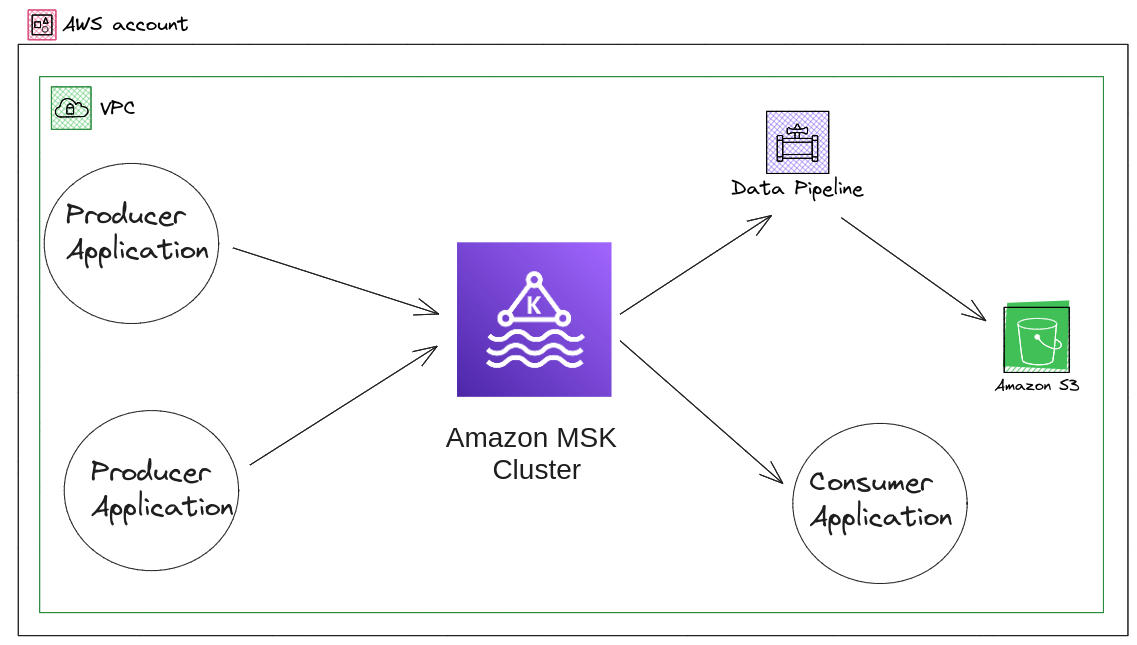
AWS account post migration
Migration Plan
- Provision and Configure MSK Cluster: We started by setting up the MSK cluster in lower environments like QA & dev. Configured it according to your requirements, ensuring optimal performance, security, and scalability. To determine the right number of brokers for your MSK cluster and understand costs, see the MSK Sizing and Pricing spreadsheet. This spreadsheet provides an estimate for sizing an MSK cluster and the associated costs of Amazon MSK compared to a similar, self-managed, EC2-based Apache Kafka cluster.
- Updated Kafka Secrets and Configurations: Updated the AWS Secret Manager and configurations in applications (both consumer & producer) to point to the newly provisioned MSK cluster.
- Performance Testing: We did performance testing using MirrorMaker to validate the performance of the MSK cluster. Evaluated its throughput, latency, and scalability under various load conditions to ensure it meets our organization’s requirements and expectations.
- Validate Application Functionality: Thoroughly tested the functionality of deployed applications on the MSK cluster. Verified the data ingestion, processing, and communication between components function as expected.
- Monitoring MSK Cluster Performance: Continuously monitor the performance of the MSK cluster using tools like AWS CloudWatch and custom monitoring solutions. Kept an eye on key metrics such as throughput, latency, and error rates to identify any anomalies or performance issues.
- Troubleshooting Issues: Actively troubleshoot issues that arise during the deployment and validation process.
- Validate Results: Validate the successful deployment and operation of applications on the MSK cluster. Verified that application logs are free of Kafka-related errors, and data ingestion and processing rates met expectations.
Performance Testing Plan
We explored the possibility of using MirrorMaker to replicate data from the old Kafka cluster to the new MSK cluster. While MirrorMaker can be used for performance testing, it doesn’t replicate offsets, making it unsuitable for the actual migration process.
MirrorMaker:
Kafka MirrorMaker is a component of Apache Kafka that helps in data replication between Kafka clusters. It enables the replication of topics from one Kafka cluster to another. We used Mirrormaker to replicate data from the production environment kafka running on EC2 to the testing environment AWS MSK & pointed the testing environment applications to it. It helped us in the validation & testing compatibility of applications with AWS MSK with real-time production data.
Check out this blog for more information related to mirrormaker: https://www.tothenew.com/blog/mirror-maker-for-kafka-migration/
Consumer Lag:
- The difference between how the producers place records on the brokers and when consumers read those messages.
We used the Consumer Offset Checker tool to calculate and monitor consumer lag for each partition of a topic & plotted the lag on cloudwatch, helping identify potential bottlenecks or performance issues in consumer processing. Here’s the Python script for calculating consumer lag.
We automated the execution of Python script using Jenkins & AWS SSM, employing a scheduled cron job for seamless integration into our workflow. This automation enabled us to execute the script at predefined intervals. Link To Jenkinsfile. We created a Cloudwatch dashboard with consumer lag for all topics.
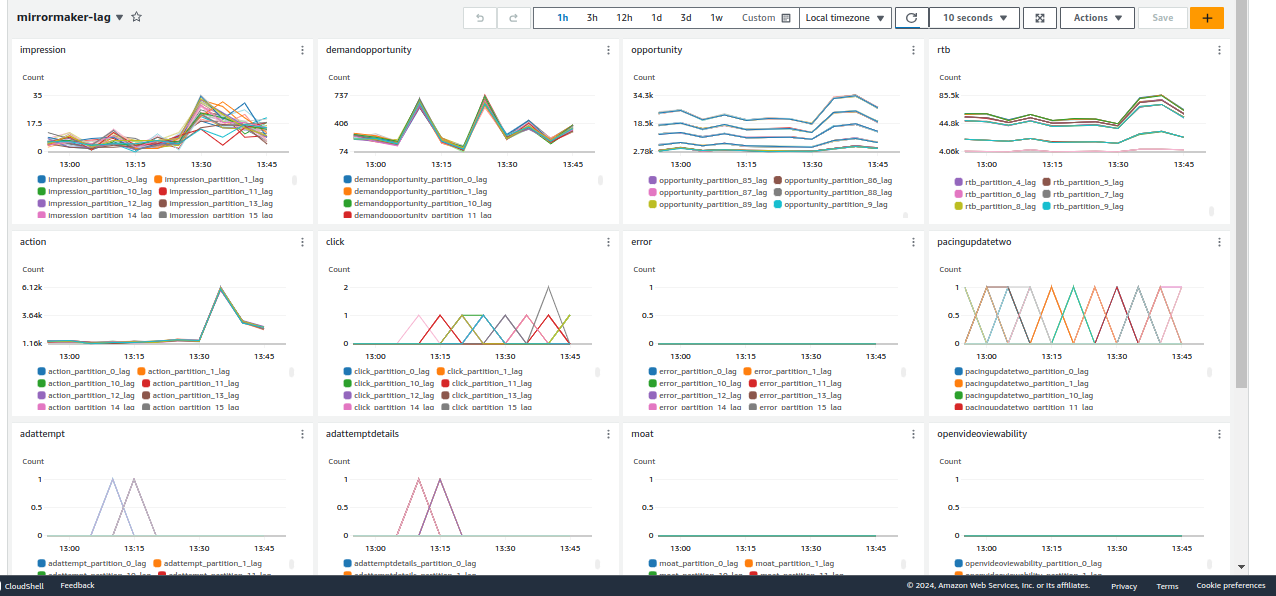
Cloudwatch dashboard-1
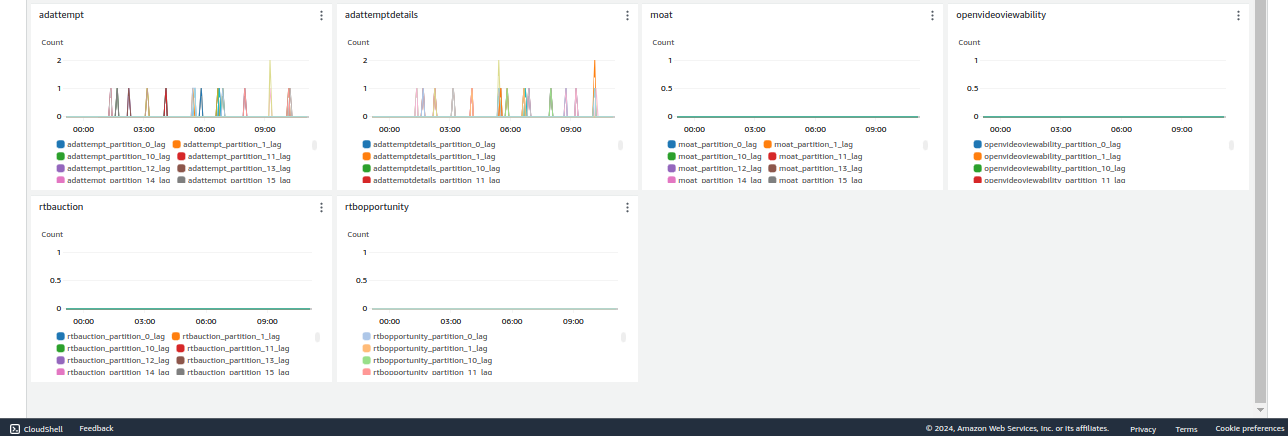
Cloudwatch dashboard- 2
After conducting data verification between the production and integration environments across various timeframes, it became evident that the applications were successfully able to both produce and consume data. With confirmation of data integrity and functionality, we proceeded with the cutover process in the production environment.
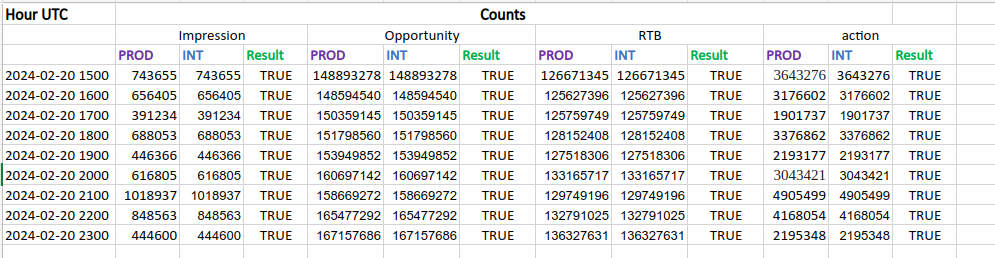
functional testing
Post-Migration & Cleanup
After completing the migration, there are several post-migration tasks to ensure a smooth transition and clean up any residual resources:
- Update application configurations and remove references to the old Kafka cluster.
- Validate data integrity and consistency across applications.
- Decommission old Kafka clusters and associated resources.
- Monitor MSK cluster performance in production and make any necessary adjustments.
Conclusion
By following a structured migration plan and addressing key considerations, organizations can seamlessly transition their Kafka workloads to AWS MSK and unlock the full potential of real-time data streaming on the cloud. Partnering with a managed cloud services provider who can help you choose the right migration path is one way to overcome these kinds of migration challenges.


