For one of our Global Advertising Management Platform clients, we did one migration project with zero downtime for components like Platform DB, Ceph, Aerospike, Kafka (Zookeeper +data nodes), MapR (hive, oozie, hue), Druid (Zookeeper +data nodes), Flink (Zookeeper +data nodes), Monitoring (Icinga,collectd, cloudwatch), Logging (logstash & Opensearch) & Other Components ( Nexus, SFTP, Jenkins ).
To start off this migration blog, kafka components and its migration using Mirror maker are explained below in detail.
MirrorMaker is a process in Apache Kafka to replicate or mirror data between Kafka Clusters. Don’t confuse it with the replication of data among Kafka nodes of the same cluster. One use case is to provide a replica of a complete Kafka cluster in another data center to cater to different use cases without impacting the original cluster.
In MirrorMaker, there is a consumer connector and a producer connector. The consumer will read data from topics in the source Kafka cluster, and the producer connector will write those events or data to the target Kafka Cluster. The source cluster and target cluster are independent of each other.
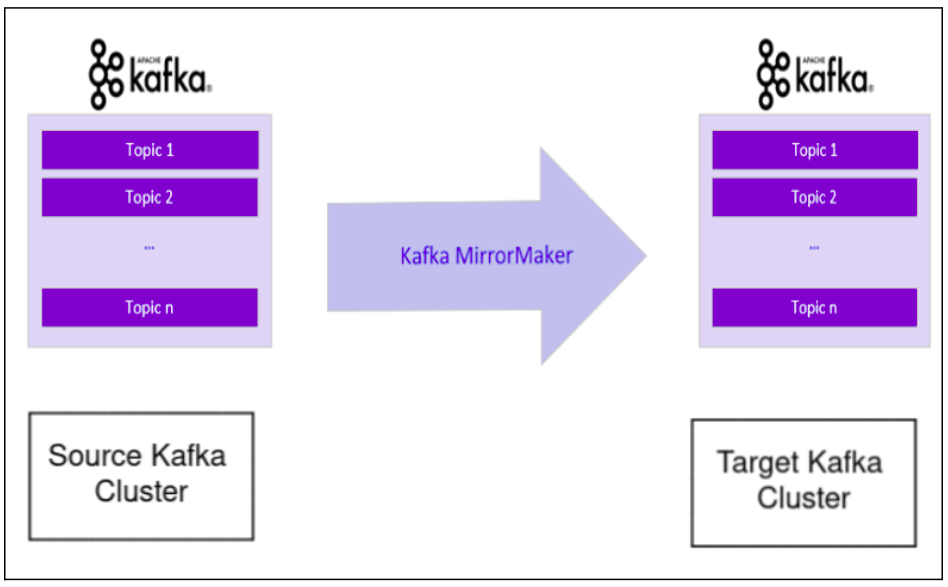
Kafka’s mirroring feature makes it possible to maintain a replica of an existing Kafka cluster. The following diagram shows how to use the MirrorMaker tool to mirror a source Kafka cluster into a target (mirror) Kafka cluster. The tool uses a Kafka consumer to consume messages from the source cluster and re-publishes those messages to the local (target) cluster using an embedded Kafka producer.
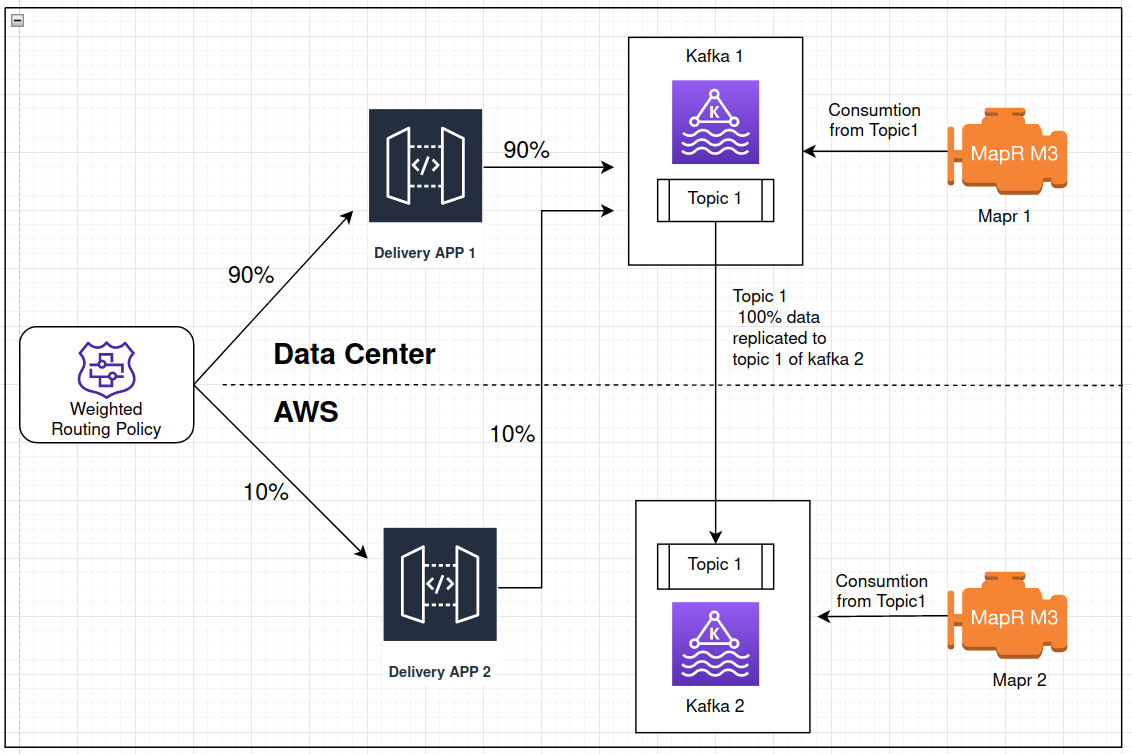
For one of our customers, while migrating their entire system from an on-premises environment to the cloud (AWS), we used mirror maker as they needed migration with zero downtime to their existing pipeline. As shown in the diagram below, we created a separate AWS pipeline similar to Datacenter one and used a mirror maker to copy data from DC kafka to AWS kafka.
Steps for setting up a mirror between source and target kafka clusters :
- Create a list of topics present in the source cluster that needs to be copied to the target cluster

- Create those topics on the target cluster with the same replication, partitions, and other configs

- Create a Mirror maker cluster depending on data load via topics
- Use proper instance type for mirror maker cluster depending on topics (This plays a vital role in reducing the lag between source and target kafka data)
- In our case, we used multiple clusters configuring different topics as the data load in each topic was varying. We used a c5.18x instance-type cluster of 15 nodes for topics with a heavy data load. Whereas for topics with less data load, we used c5.18x instance types cluster of 2 nodes.
- Setting up a mirror is easy – simply start the mirror-maker processes after bringing up the target cluster. At a minimum, the mirror maker takes one or more consumer configurations, a producer configuration, and either a whitelist or a blacklist. You need to point the consumer to the source cluster’s ZooKeeper, and the producer to the mirror cluster’s ZooKeeper (or use the broker.list parameter)

- Playing around with different config parameters to optimize the mirroring process.
1. consumer.properties
fetch.message.max.bytes=40240000
client.id=prod-mirrormaker-group-300322_001
group.id=prod-mirrormaker-group-310322_01
exclude.internal.topics=true
num.consumer.fetchers=300
fetch.max.wait.ms=500
fetch.min.bytes=186384
2. producer.properties
producer.type=async
queue.buffering.max.messages=2000
queue.buffering.max.ms=500
batch.num.messages=3000
send.buffer.bytes=1000000
client.id=prod-mirrormaker-group-240322_001
compression.codec= gzip
request.required.acks=1
batch.size = 1000
buffer.memory = 2000000000
How to check whether a mirror is keeping up :
The consumer offset checker tool is useful to gauge how well your mirror is keeping up with the source cluster. Note that the –zkconnect argument should point to the source cluster’s ZooKeeper (DC in this scenario). Also, if the topic is not specified, the tool prints information for all topics under the given consumer group. For example:
![]()
| Group Topic Pid Offset logSize Lag Owner
KafkaMirror test-topic 0 5 5 0 none KafkaMirror test-topic 1 3 4 1 none KafkaMirror test-topic 2 6 9 3 none |