
Security and Bias Issues When Testing with LLMs
Introduction:
As software development teams start exploring Generative AI and Large Language Models (LLMs) for test and development work, resulting productivity boosts have generated quite a bit of excitement. From authoring unit tests to code diff summarization and supporting exploratory test work, LLMs are becoming useful assets for the QA toolbox.
This new technology comes with serious implications associated—particularly with bias, security, explainability, and reliability. In this article, we explore the practical danger and ethical issues QA and DevOps teams encounter when adopting LLMs as part of their processes.
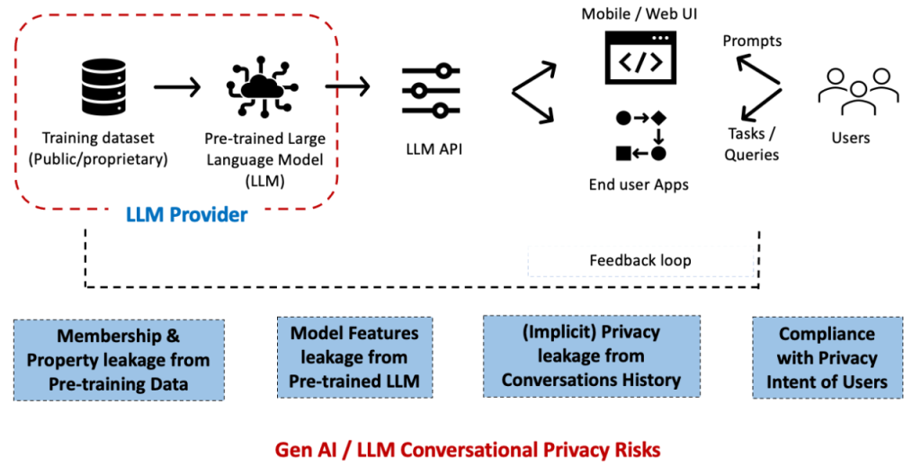
LLM conversational Privacy Risk
1. Data Leakage Risk
LLMs, especially those accessed via third-party APIs (e.g., OpenAI, Anthropic), also carry with them the risk of accidental data exposure. Submitting test scripts, logs, or application code for third-party LMs can compromise:
Confidential user information
Secrets or API keys
Internal business logic
Even de-identified data has the potential for re-identification with enough context.
Best Practices:
- Use on-premise or self-hosted LLMs for sensitive data.
- Sanitize or mask all inputs before feeding them to models.
- Review and make yourself aware of your AI supplier’s terms of data retention and use.
2. Biased Test Recommendations
Big public data from the web on which LLMs are trained will often have ingrained biases—of gender, race, geography, age, and the like. As such, AI tests may:Reflect stereotypes or ignore edge cases
Underrepresent minority user scenarios
Forget localizability and accessibility
Best Practices:
- Vary QA teams to review AI-authored test cases.
- Apply LLMs to support, not substitute for, inclusive test planning.
- Make bias testing part of your overall QA plan.
3. Modeling Hallucinations and Test Reliability
It has been observed that LLMs will “hallucinate”—generate responses that are plausible-sounding yet incorrect. In QA, this can cause:
- Tests that pass without verifying any working functionality
- False negative or positive test results
- Spending time debugging poorly written or irrelevant tests
Best Practices:
- Keep humans in the test material review cycle for AI-prepared tests.
- Integrate static analysis software for discovering logical and syntactic mistakes.
- Treat LLMs as support aides, not final deciders.
4. Lack of Explainability
LLMs are essentially black-box models—they nearly never explain why a given input or assumption was chosen. This creates challenges for:
- Highly regulated fields like healthcare and finance, which require audit trails
- Recognizing test failure or model behavior
- Building trust for automation pipelines
Best Practices:
- Add manual annotations or context with AI-authored tests.
- Use instruments or models that have logs or traceability.
- Don’t depend solely on LLMs for compliance-critical workflows.
5. Supply Chain Security :
Most QA tools powered by GenAI are third-party model- and library-dependent, which introduces supply chain risks, including:
- Insecure dependencies or outdated packages
- Malicious model weights or plugins
- Poorly integrated CI/CD configurations
Best Practices:
- Treat AI toolchains as key dependencies—regularly audit them.
- Keep models and libraries up to date using trusted sources.
- Implement DevSecOps practices across all AI components.
Conclusion
LLMs are evolving at an unprecedented pace, and ensuring their trustworthiness requires more than just technological innovation — it demands a strong data governance framework. Such a framework must enforce ethical data management, safeguard privacy, mitigate bias, comply with regulations, and prevent risks like security breaches and model hallucinations. In this article, we highlighted the critical role of governance in LLM adoption, the regulatory landscape, and the challenges in achieving robust oversight.
As AI adoption expands across sectors like healthcare, finance, pharmaceuticals, supply chain, and cybersecurity, governance models must be both adaptable and scalable. Future-ready frameworks should integrate human-in-the-loop processes to blend AI’s analytical power with human judgment, reducing the risk of misinformation and ethical pitfalls. Ultimately, the success of LLM-driven systems will depend on continuous refinement of governance strategies to align innovation with responsibility and trust.
