This is the second blog of the Spark series. This blog post include setup of Spark environment followed by a small word count program. The idea behind the blog is to get hands on in Spark setup and running simple program on Spark. If you want to know more about Spark history and it’s comparison with Hadoop, please refer Spark 1o1.
Please note – This is a single node, local setup. I will cover Spark cluster setup on EC2 box in upcoming blogs.
Setup – Before starting Spark setup make sure Scala 2.1 or higher version and Java 1.7 or higher version must be installed on you system. For This blog, I have used Java 8.
Steps –
- Spark supports loading data from HDFS. So, we need to install hadoop before installing Spark. Download and untar Hadoop distribution using terminal.
- $ wget 2.5.0.tar.gz
- $ tar -xvf hadoop- 2.5.0.tar.gz
- Downloads and untar Spark pre build distribution or you can download source and build using sbt tool.
- $ wget http://d3kbcqa49mib13.cloudfront.net/spark-1.0.2-bin-hadoop2.tgz
- $ tar -xvf spark-1.0.2-bin-hadoop2.tgz
- $ mv spark-1.0.2-bin-hadoop2 spark-1.0.2
- Open .bashrc file and add environment variable for Hadoop and Spark.
- export HADOOP_HOME=/home/ec2-user/hadoop-2.5.0
export SPARK_HOME=/home/ec2-user/spark-1.0.2
export PATH=$PATH:$HADOOP_HOME/bin:$SPARK_HOME/bin
- export HADOOP_HOME=/home/ec2-user/hadoop-2.5.0
- To validate the set up load .bashrc file and echo PATH.
- $ source ~/.bashrc
- $ echo $PATH
Spark shell – We are ready to run Spark shell, which is a command line interpreter for Spark. We can execute arbitrary Spark syntax and interactively mine the data.
- $ cd spark-1.0.2
- $ bin/spark-shell
Program – In order to keep sprite of Hello World alive, I have changed the word count program to Hello World. In short the program will count number of words in a a text file.
[java]
package com.intelligrape.spark;
import java.util.Arrays;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
/**
* @author surendra.singh
**/
public class WordCount {
public static void main(String[] args) {
//Create Java Spark context object by passing SparkConfig Object
JavaSparkContext sc = new JavaSparkContext(new SparkConf());
//load sample data file containing the words using Spark context object.
//Spark will read file line by line and convert it in a RDD of Sting.
//each object in RDD represent a single line in data file.
JavaRDD<String> lines = sc.textFile("/home/test-data/Hello World.txt");
//convert RDD of string to RDD of words by spliting line with space.
JavaRDD<String> words = lines.flatMap(l -> Arrays.asList(l.split(" ")));
//Create tuple of each word having count ‘1’. Spark create tuple using Tuple2 class
JavaPairRDD<String,Integer> tuple = words.mapToPair(w->new Tuple2<>(w, 1));
//reduce all keys by adding their individual count
JavaPairRDD<String, Integer> count = tuple.reduceByKey((a, b) -> a + b).sortByKey();
//Print the result
for (Tuple2<String, Integer> tuple2 : tuple.toArray()) {
System.out.println(tuple2._1() + " – " + tuple2._2());
}
}
}
[/java]
Submitting Job in Spark – Create jar file for your project and execute below command from Spark root folder. For single node Job submission, master node will be always ‘local’.
- $ bin/spark-submit –class com.intelligrape.spark.WordCount –master local HelloWorld.jar
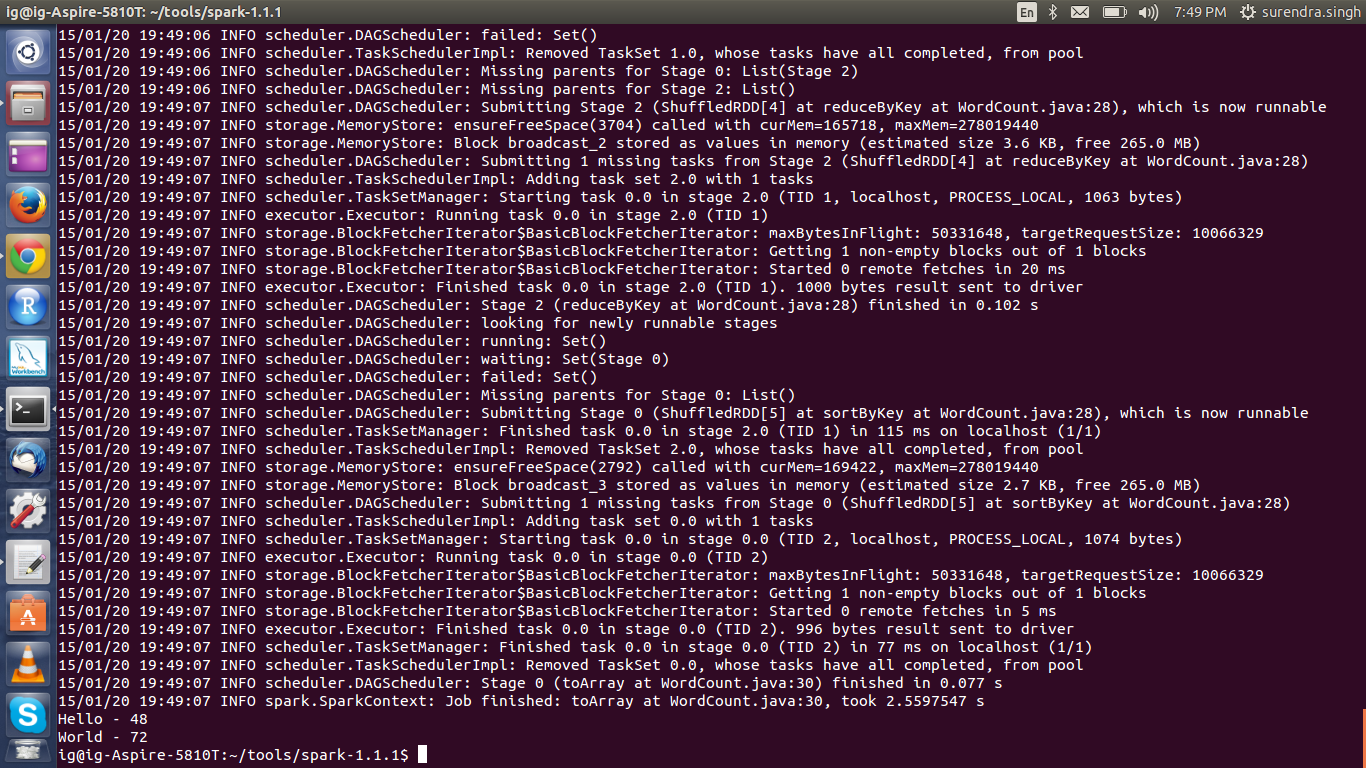
This concludes the Hello World count program using Spark. In next post we will go ahead with a detailed architectural flow of how Spark makes use of RDD and DAG.
I like the valuable information you supply in your articles. I will bookmark your weblog and test once more right here frequently. I am fairly sure I will learn a lot of new stuff proper right here! Best of luck for the next!