
Striving for Legacy Transformation: A Pragmatic Approach to Modernizing Monolithic Systems
Nowadays, every org wants to migrate to a microservices architecture; the idea sounds great on paper. But when you’re staring at an 8-year or decade-old monolith that processes millions of transactions and somehow never breaks, suggesting a complete rewrite feels… well, insane.
I’ve been down this road more times than I care to admit. Be it big old player or new entrants in the industry everybody wants innovation, to work with cool new tech meanwhile you’ve got this beast of an application that just keeps chugging along, making money and keeping customers happy. Trust me, the disconnect is real.
The Problem With “Just Modernize It”
We don’t want to put hurdles towards progress. But there’s this weird assumption that legacy equals bad. Your main platform might be old, sure. The codebase has some questionable decisions from 2007 or even older that we all just live with now. But you know what? It works. Really, really well. Say handling over 2 million transactions without a single major outage and surviving different compliance audits, major vendor changes, and that time when everyone decided they absolutely needed to integrate with some new payment processor that shall remain nameless.
The problem isn’t that your system is broken. The problem is that when Feature A gets slammed during a sale, we have to scale up Features B through Z even though they’re just sitting there doing nothing. It’s wasteful and expensive, but the alternative always seemed to be “rewrite everything” which… no. Just no.
What I Actually Recommend Instead for Scenarios like this.
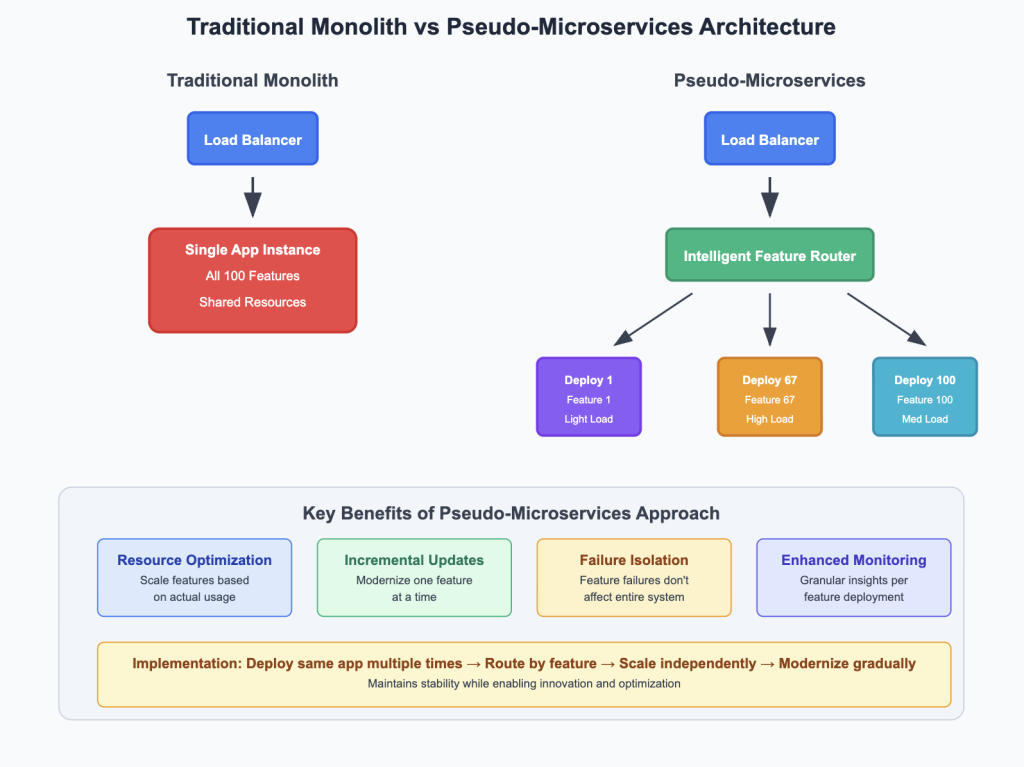
Okay, so here’s where it gets interesting. Instead of breaking apart your monolith, decide to deploy it differently. It sounds weird but actually works.
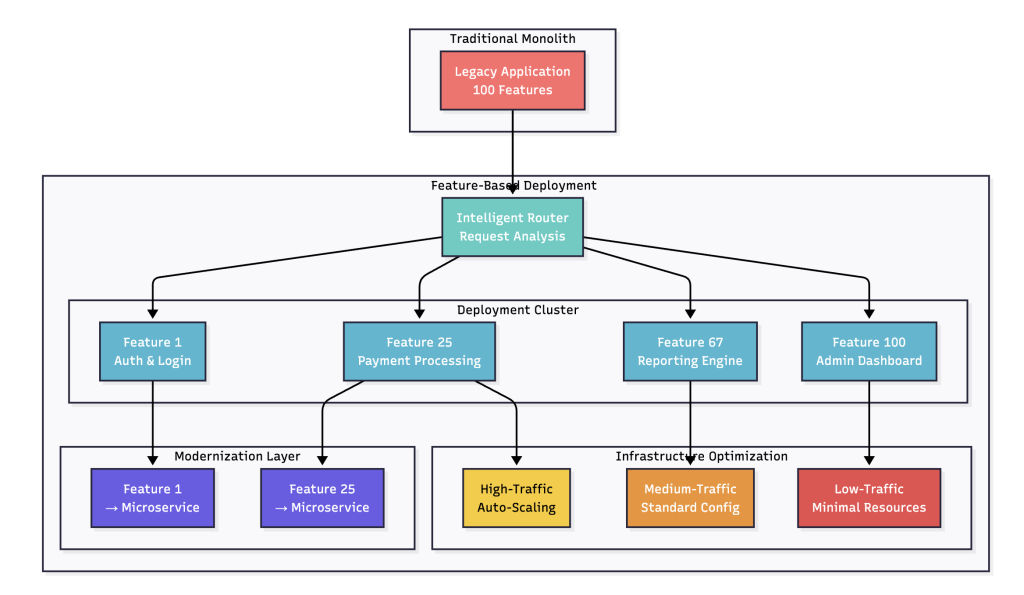
Take your application – all 100+ features of it—and start deploying it multiple times. Then set up routing so specific features always hit specific deployments. So when someone uses the checkout feature, they get routed to the “checkout deployment.” When they browse products, they hit the “catalog deployment.”
I know, I know. It sounds like overkill. But think about it – suddenly we could scale just the parts that needed scaling. No more throwing hardware at the entire application just because one feature was getting hammered & this will work like a charm.
Pragmatic Approach to Modernizing Monolithic Systems
Laying Down the Groundwork to Make This Work
Implementing feature-based deployments will be a pain initially. The routing logic alone might take forever for you to get right or even selecting the right tools for it. Your application might not be designed with clear feature boundaries, so you might need to map out which URLs correspond to which features. Some API calls touch multiple features, which mean to make some judgment calls.
Then there’s the database situation. Most of features might share the same database, which means you can’t just scale deployments without thinking about connection limits. You might end up implementing per-deployment connection pooling, but that will take trial and error to tune properly.
And suddenly, you will go from watching one application to watching 50+ deployments. existing dashboards might became useless overnight & you will have to rebuild the entire observability strategy around this new model.
But here’s the thing – it will be worth it. The next major event say a Black Friday, instead of scaling your entire infrastructure by 10x, you can just scale three feature deployments and leave everything else alone. It will save you thousands of dollars in cloud costs in just that weekend.
What This Actually Looks Like Day-to-Day
Lets say feature F1 runs once per day and uses maybe 2% CPU most of the time. Before, it got the same resources as the other feature F2 that itself is humnogus hardware resource-hungry feature. Now? Feature F1 runs on a tiny instance that would cost almost nothing.
Meanwhile, feature F3 maybe gets hit constantly and needs way more juice. Instead of the feature F3 traffic impacting everything else, it has its own dedicated resources. When feature F3 goes down, the rest of the platform keeps humming along.
Legacy to Gradual Modernization
Traditional Monolith & Feature-Based Deployment Strategy
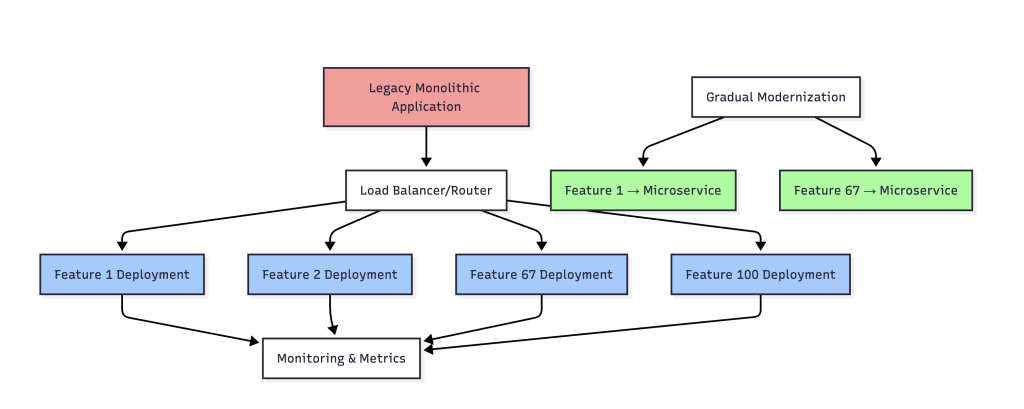
The coolest part though? You can experiment now. Team can rewrite feature F4 in Go while everything else stays in PHP. If it works out, great. If not, we just route traffic back to the original deployment. No big deal.
This will also help starting modernizing features one at a time. The user authentication flow can now get a complete overhaul – new framework, better security. Since it’s isolated in its own deployment, you can take your time and test thoroughly without worrying about breaking anything else.
The Stuff Nobody Tells You
First off, the team needs to understand the application way better than they probably do right now. You think you know the codebase, but mapping features to deployments will reveal all sorts of hidden dependencies and weird edge cases.
Second, deployment orchestration becomes critical. You can’t manually manage 50+ deployments. You can use AWS ECS, Kubernetes with Helm charts, but honestly, any decent container orchestration platform would work. The key is automation – spinning up a new feature deployment should be a one-command operation.
Third, observability is make-or-break. With traditional monitoring, you’re watching one big thing. Now you’re watching dozens of smaller things, and you need to understand how they interact. Please do implement distributed tracing, which may seem like more work than expected but absolutely necessary.
Why This Makes Business Sense
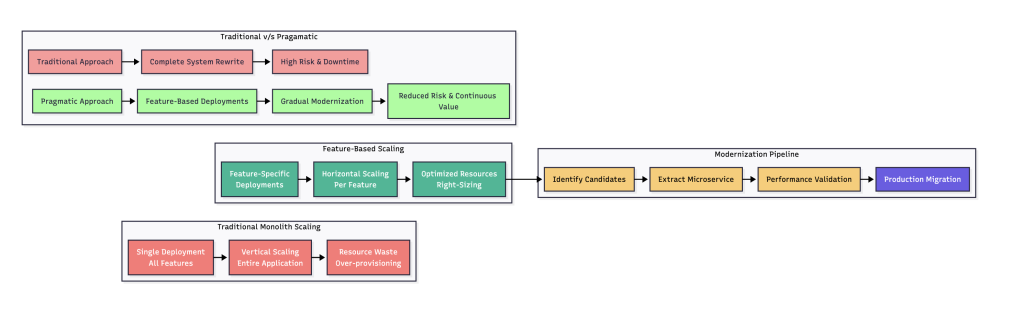
Here’s how you sell it to your leadership team: Don’t ask for 18 months and a massive budget to rewrite everything. Showcase the plan for incremental improvements that start paying off immediately.
Traditional v/s Pragmatic Approach
The first feature deployment you move will reduce infrastructure costs during peak times. Everything after that will be pure savings.
Plus, you’re not disrupting SLAs or customer experience. The platform will look and work exactly the same from the outside. No one has to learn new workflows or deal with bugs from a massive rewrite.
And honestly? It will give the team a way to gradually adopt new technologies without betting the farm. Some features will probably become proper microservices eventually. Others might get modernized in place. A few might stay exactly as they are. That’s fine – you have options now.
The Real Talk
Is this approach perfect? Nope. It’s definitely more complex than running one big application. Your operations team might need to level up their skills. Your monitoring gets more complicated & you will need better automations.
But you know what’s really complex? Explaining to your CTO why the platform was down for six hours because you were in the middle of a massive microservices migration. Or telling your team they can’t work on new features for the next year because everything has to be rewritten first.
This approach lets you have your cake and eat it too. You get the benefits of microservices architecture – independent scaling, failure isolation, and technology flexibility – without the risks of a big bang rewrite.
Two years down this journey, some deployments might still be running the original code, some have been completely modernised, and a few are somewhere in between. But the platform will be more resilient, cost less to run, and give you way more flexibility for future changes.
Most importantly, you would never have to tell your customers “sorry, the platform will be unstable for the next 18 months while we modernize.” You just keep improving things behind the scenes.
That’s the kind of transformation that actually works in the real world – gradual, practical, and focused on business outcomes rather than technology trends. Sometimes the best innovation is just doing the boring stuff really well.


