
Testing machine learning models: A QA guide to responsible and reliable AI
Introduction:
AI and machine learning are becoming a part of our everyday lives, shaping everything from the way we get medical advice to how financial decisions are made. But unlike traditional software, these systems don’t just follow fixed rules, they learn, evolve, and change over time. And that makes testing them a whole new kind of challenge. How do we make sure these models stay fair, accurate, and trustworthy even as they grow and adapt?
QA in AI isn’t just about catching bugs, it’s about building trust throughout the entire lifecycle. In this blog, we’ll explore key strategies for testing AI models responsibly, from data preparation to post-deployment monitoring, helping you unlock AI’s true potential with confidence.
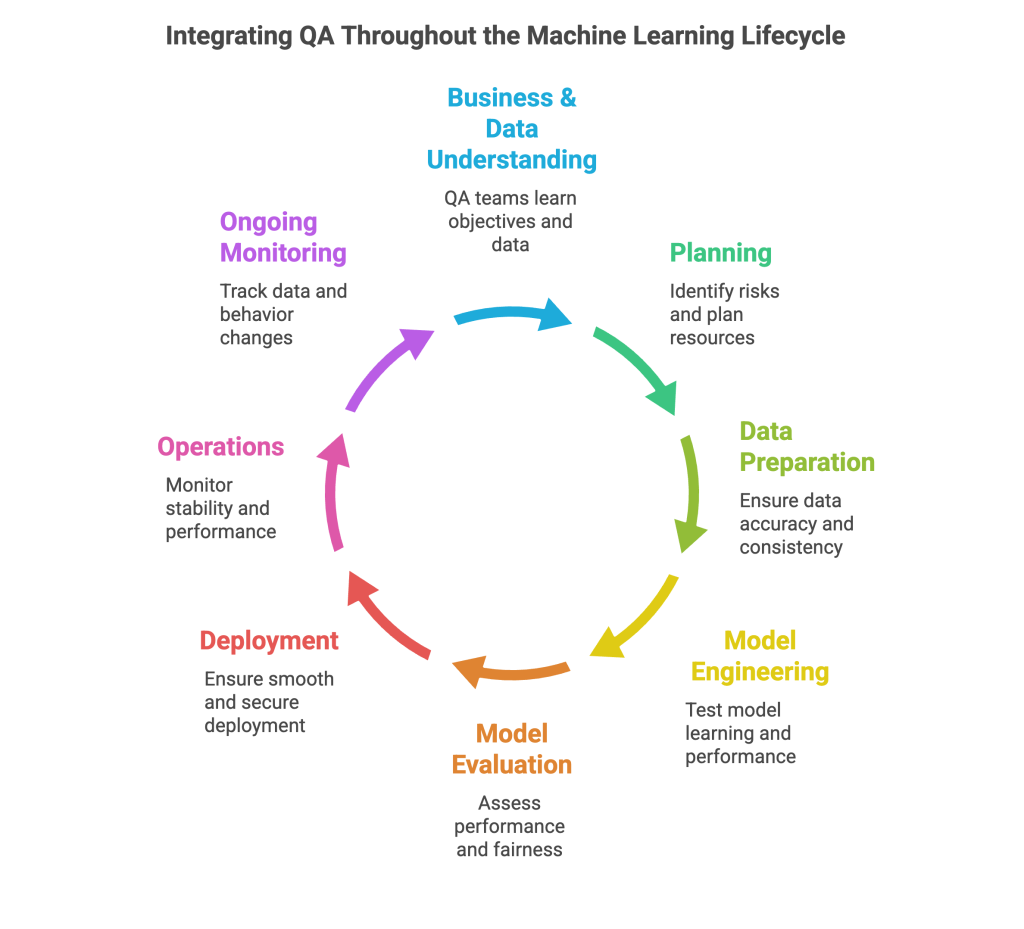
QA Across the Machine Learning Lifecycle
Machine learning isn’t something you just set up once and forget. It is a continuous process, and at each step quality and trust is achieved through testers involvement early and frequently, not only at the final stage.
- Business & Data Understanding: QA teams intervene at the initial stage to learn the business objectives as well as the data that drives the model. Clarity and shared understanding at this point can save much trouble later on.
- Planning: Testers can assist in discovering risks early; messy data, unclear requirements, complicated models etc, and collaborate with the team to plan testing and resources accordingly.
- Data Preparation: ML models are trained on data, so we dive into it, making sure it is accurate, complete, consistent, and unbiased. The idea is to ensure that the model has a good foundation.
- Model Engineering: QA pays close attention to how the model learns as it is being constructed. We test for overfitting, underfitting, and feed real-world, messy data to see how it deals with surprises.
- Model Evaluation: With the right metrics, we assess whether the model is performing as expected not only in terms of performance, but also in terms of fairness and reliability. When it is not ready, we flag it early.
- Model Deployment: QA is important in the smooth deployment process. Checking APIs, real-time behavior, and ensuring everything works securely and reliably in production.
- Operations: QA continuously monitor performance and behavior. Ensures the model remains stable and keeps on delivering, whether it is logs, system health, and resource usage.
- Ongoing Monitoring: QA continuously monitors the data or behavior change over time so when the model begins to drift we are aware when it is time to retrain or adjust.
Integrating QA Throughout the Machine Learning Lifecycle
Catching Problems Early: Underfitting and Overfitting
Two common issues can quietly throw your model off track: underfitting and overfitting.
- Underfitting: A model too simple to capture patterns. It performs poorly across training and test sets. In a customer churn prediction project, an under fitted model failed to identify even obvious churn indicators like frequent complaints.
- Overfitting: A model that memorises training data but fails on new input. For example, a job screening model might reject qualified candidates if they don’t match historical patterns. QA tests on diverse input and uses regularisation to prevent overfitting.
Spotting these issues early helps shape models that aren’t just accurate on paper, but reliable in the real world.
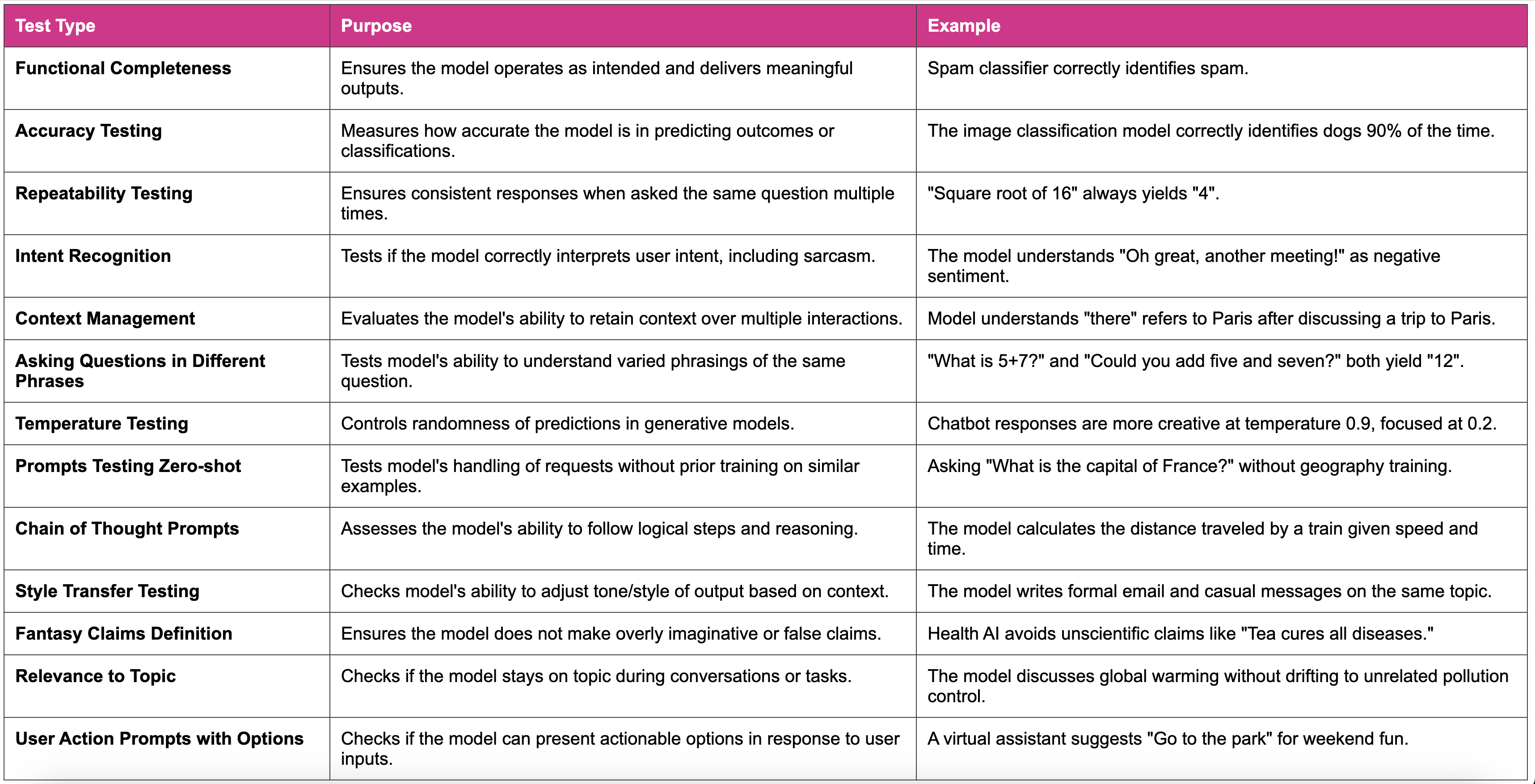
Functional Testing: Beyond Metrics
Functional testing in ML is all about ensuring the model behaves the way users expect across real scenarios, not just in theory. QA simulates real-world usage, validates edge cases, and ensures consistency in output formats and responses.
Machine Learning Functional Testing
In addition to standard validations, QA also performs scenario-based testing to simulate user journeys, and regression testing after retraining or data changes to ensure stability across iterations.
Responsible AI Testing: Building Ethical and Trustworthy Systems
Now that we’ve prepared our data and trained the model, let’s see how we ensure it performs responsibly in the real world.
Key Areas of Responsible AI Testing:
- Fairness Testing:
We must ensure that our models are fair to people- irrespective of gender, race, age, or other protected characteristics. It implies that the outputs of models should be tested on different demographic groups to detect and resolve disparities at an early stage of development.
- Bias Detection & Mitigation:
Bias often hides in our data and can sneak into the model even when it isn’t obvious. We use diagnostic tools and fairness metrics to uncover these blind spots, then apply mitigation techniques like reweighting, resampling, or model adjustments to reduce unfair outcomes.
- Transparency:
AI does not need to be a black box. We focus on explainability to ensure that users, regulators, and stakeholders know the reason behind a decision. Tools such as SHAP or LIME allow us to bring out the most important factors in predictions, which is crucial to debugging as well as trust-building. - Ethical Testing:
Some models make decisions that can seriously impact people’s lives. We assess not only what the model predicts, but how it behaves in morally sensitive scenarios. That includes reviewing edge cases, unintended use, and compliance with ethical standards relevant to the domain.
- Data Privacy & Security:
We ensure that training and inference respect user privacy and meet data protection laws. This includes testing for data leakage, anonymization failures, and vulnerabilities that could expose sensitive information.
- Model Generalisation:
A model that works great in the lab might fail in production. We test how well our models generalize to new environments, unseen data distributions, and real-world usage making sure they don’t just memorize the training data but actually learn to adapt.
- Societal Impact Testing:
We step back and look at the bigger picture: How does this system affect the communities it serves? Are there downstream harms we didn’t anticipate? Responsible testing means accounting for long-term, systemic impacts not just short-term metrics.
At its core, responsible AI testing is about making technology work for people fairly, transparently, and with human values in mind.
API Testing for Machine Learning Models: The Inference Gateway
When machine learning models are deployed as APIs, thorough API testing is essential. It allows us to interact directly with the inference endpoint, verifying that the model works reliably and securely regardless of the user interface.
Key Focus Areas in API Testing:
- Endpoint Validation: Ensure the inference endpoint is accessible.
- Request/Response Validation: Check input/output formats.
- Data Type & Edge Case Testing: Submit varied and extreme inputs.
- Payload Size Testing: Confirm system handles different request sizes.
- Error Handling: Validate proper HTTP responses and error messages.
- Authentication & Authorization: Secure API access.
- Rate Limiting: Stress test to handle traffic spikes.
- Performance Metrics: Measure latency and throughput.

Sample API Response Example
Example: ChatGPT-Text Generation API:
Text generation API:
Endpoint: https://api.example.com/chat/v1/generate_text
API Testing Scenarios for this model:
- Functional Testing: Submit prompts, validate coherence, test multilingual input.
- Negative Testing: Send malformed prompts, wrong API keys and observe error handling.
- Performance Testing: Simulate concurrent requests and measure response time.
API testing helps ensure ML services deliver high-quality results in the real world.
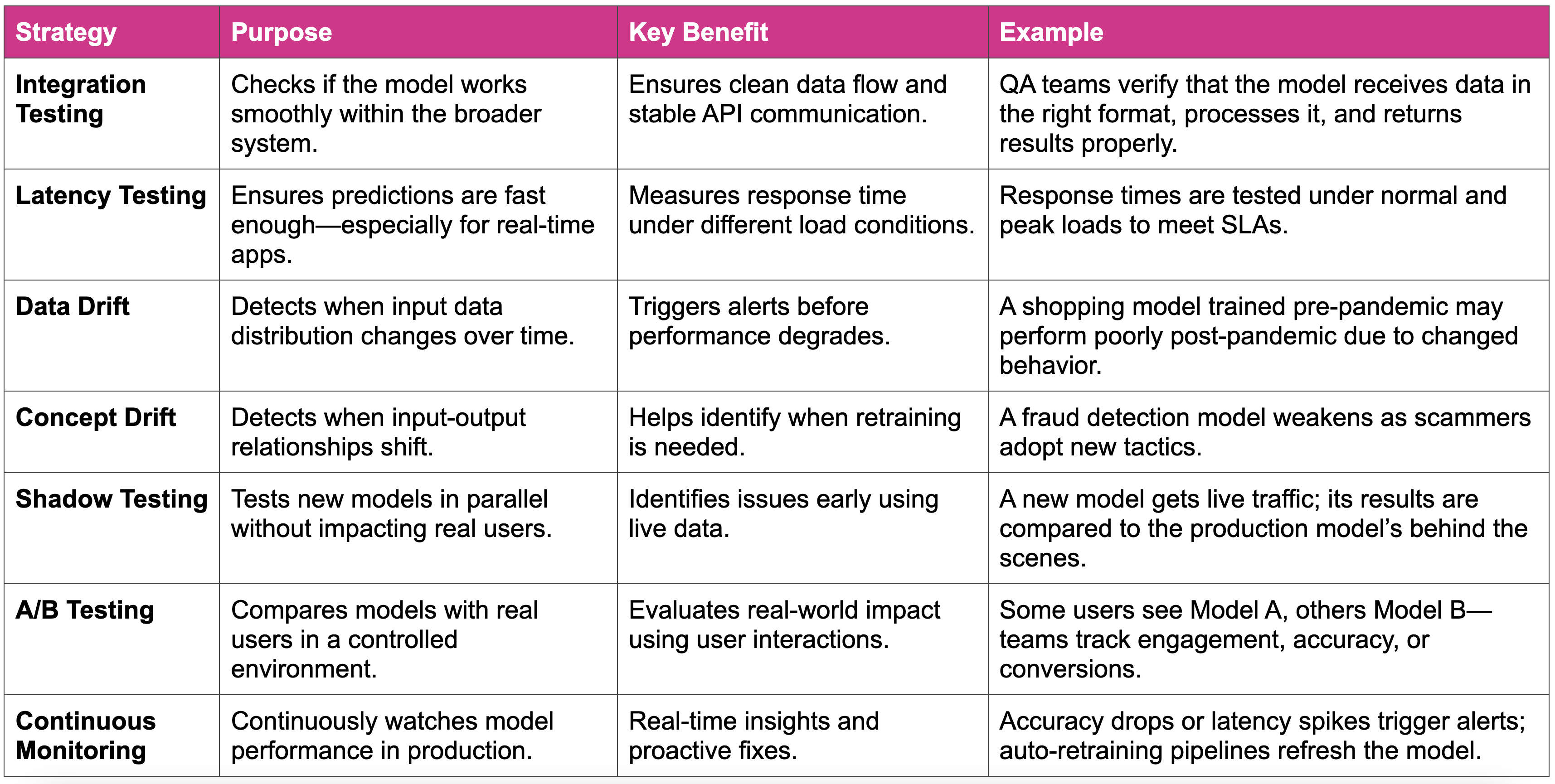
The Evolving Model: Post-Deployment Testing Strategies
QA’s role doesn’t end after deployment. In fact, this is when real-world testing begins.
- Model Drift Detection: QA tracks incoming data distributions. If a retail model starts underpredicting due to sudden market changes, we raise flags and initiate retraining.
- Performance Degradation Tracking: Over time, user behavior or data inputs evolve. QA benchmarks model accuracy periodically to detect drops in precision, recall, or latency.
- Alerting and Retraining Triggers: Automated alerts inform teams when model KPIs cross thresholds. Combined with monitoring tools, this ensures proactive responses.
- Shadow Testing: QA runs updated versions in parallel with live models to compare outcomes before official rollout, reducing risk.
- Dashboards & Automation: QA also uses dashboards and automated pipelines to visualize model health over time, enabling timely interventions without manual deep dives.
Testing Strategies After Deployment
Continuous evaluation ensures that ML models stay robust, reliable, and relevant.
Conclusion:
AI and machine learning are changing the way we think about testing. It’s about making sure systems are fair, transparent, and responsible.
QA plays a critical role in this shift. By getting involved early, testing with ethics in mind, and keeping a close eye on models after they go live, we help ensure AI systems stay reliable and do what they’re meant to do safely.
- Start early. Don’t wait until production to think about quality.
- Test with purpose. Fairness, bias, and transparency matter just as much as accuracy.
- Build trust. Because in the world of AI, trust is the new standard for quality.
Let’s shape the future of AI together.
