With the mammoth rise in vast amounts of data across the globe, it has been a necessity for the companies to ensure that they derive insights from the data being gathered. While traditional statistical tools have always been a prior step in evaluating the data, the application of analytics and machine learning has become increasingly important to get predictions. Though the data is available in large chunks, the presence of plethora unwelcome data can create havoc in analysis. Since the analysis these days are real-time, the actions must be taken on the data to check the anomalies which can skew the results. If these anomalies or outliers do exits, there must be mechanisms to detect and mitigate their influence.
Anomaly detection is not a new concept or technique, it has been around for a number of years and is a common application of Machine Learning. The real world examples of its use cases include (but not limited to) detecting fraud transactions, fraudulent insurance claims, cyber-attacks to detecting abnormal equipment behaviors.
What is Anomaly Detection?
Anomaly detection or outlier analysis is a step in data mining that identifies data points, events, and/or observations that deviate from a dataset’s normal behavior. Anomalous data can indicate server failure due to high memory utilization, exceeding usage limits, technical glitches etc. Designing of modern machine learning algorithms is ask for today’s era to automate the detection and prediction of anomalies.
What is Time Series Anomaly Detection?
The foremost requirement for any anomaly detection lies on its capability to analyze the time series data in real-time. If various features are available then the anomaly detection could be carried out using multivariate regression techniques, however, the time series based analysis is the most reliable one. Talking about time series, is composed of a sequence of values over intervals of time. It comprises of two variables majorly- a time stamp of metric measurement and metric value at that particular time stamp. It could be analyzed over week, month, year, seconds and minutes.
Time series data gives an intuition what the historical trend look likes and what could be future values. Anomaly detection relies on series of data science algorithms that can unveil the outliers in the key KPI metrics and can alert the concerned teams to take necessary actions.
Why Anomaly Detection on Server Metrics?
With the advent of IT industries across the globe and rise in data, the requirements for servers on the premises or on cloud has increased tremendously. These servers have associated metrics with them such as CPU, memory, disk etc.
IT industry is considered a global industry in which they tend to utilize various types of servers and their metrics such CPU, memory etc. These are often considered as the most critical assets for the operations. Therefore, the integrity and reliability of these equipment is often the core focus of their Asset Management programs.
The foremost issue lies in the reliability of these assets as these are production based servers and their failure can lead to loss of tremendous amount of money and low brand values.
Therefore there must be a robust system for anomaly detection which can detect anomalies on real-time basis and predict them for future so that corrective actions are taken at right time and alerts are generated to the appropriate teams to take necessary actions.
Project Scope
The Scope of the project is to gather the data from different HAWK servers and detect the outliers/anomalies present in the data for some particular metric based on selecting the desired lower bounds and the upper bounds. Any data point that is below the lower bound and above the upper bound is considered to be an anomaly or an anomalous data point. Also, we need to predict the future upper and lower bounds and predict the possible future anomalies for the next 24 hours or so.
Approaches tested for Time Series Anomaly Detection
For anomaly detection of the time series data extracted from HAWK servers, we tried different techniques and methods for anomaly detection and prediction. The methods used are as follows:
- Interquartile Range (IQR)
- Detection and Forecasting using Fbprophet
- Anomaly Detection using Autoencoders
- Isolation Forests
The approach that was used to move ahead with the project was the FbProphet toolkit as this algorithm nicely handles different seasonality parameters like monthly or yearly, and it has native support for all-time series metrics. Moreover, this algorithm can handle edge cases well as compared to the Isolation Forest algorithm. Also, Prophet is the newest technique for anomaly detection and prediction and is less susceptible to errors.
What’s Different?
- One of the main task/aim of the project is to predict the future bounds for the next 24 hours. The Prophet library turned out to be better in predicting the future boundaries which means that any value or data point coming out of these specified range will result to be an anomaly. Also, whenever any new data point will be out of the bounds the model will trigger an alert and immediately generate an email to the team so that the anomaly can be taken care of. The best feature lies in that it gives us a flexibility to define customized intervals and make predictions and boundaries for future time frames that can be validated against the real-time data to generate alerts as per our needs.
- The model is built in a way that it is completely customizable. The model gets trained based on various parameters which it takes as input from user as below: –
- Resource ID or the Dataset IP:
The user can choose the server IP (Resource ID) for which the user needs to see the anomaly graphs. - Project ID/Project Name:
Each server is associated with a unique project ID and project name - Duration :
The user can choose the desired duration/granularity whether he wants the model to be trained after what time intervals. The duration value can be anything like 15sec, 30sec, 45 sec, 1 min, 5min or 15min etc. based on the requirement. Choosing high granularity would cost the computation and could increase the execution time. - Metric :
Metric gives the user an option to select among the various metrics that are available for which the user desires to see the detected anomalies or the future prediction bounds. A metric could be anything like cpu_utilization, memory_utilization, disk_space, etc. - Incremental Factor :
If the user is interested in seeing extreme data points, the beta factor gives user the flexibility to extend the lower and the upper bounds. The incremental factor will get multiplied with the current boundary values so that these bounds can be extended. This will help not to detect those values as anomalies which are outside but just near the bounds.
- Resource ID or the Dataset IP:
Architecture
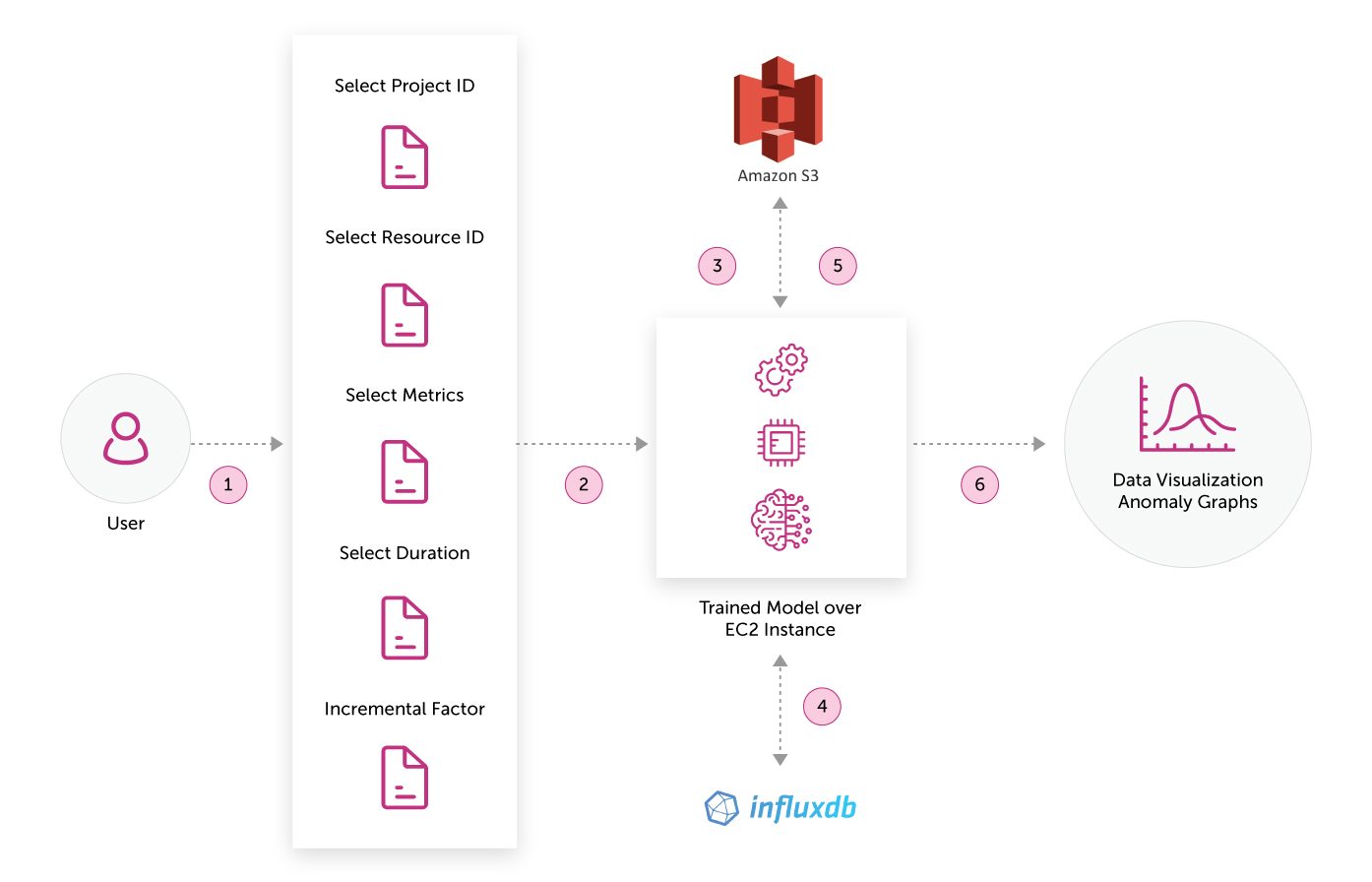
The architecture overview of the diagram can be explained as below:-
- The user can create the anomaly alarms based on its own customization. It primarily selects the project id, resource id, metric, duration and incremental factor for creation of alarm.
- Once this anomaly alarm is triggered, it creates a user defined model.
- The model gets trained and gets uploaded in the S3 bucket.
- Simultaneously, the values of bounds get stored in InfluxDB which is a time series database.
- These predicted bounds and the model can be used to trigger an alert when an anomaly is encountered in real-time.
- In case the user wishes to view the trend, historical data and future predictions, he can utilize the models to create visualizations.
Future Use Case
The solution has been designed in such a way that it can be integrated with any server and any defined metrics. Different components have been kept separate while defining the architecture of the overall solution. Hence, in future if any client wants to utilize this framework for anomaly detection and prediction, data science components can be reused, integrated and deployed on the premises of the client. Moreover, the solutions offer different models to be built and stored on S3 which allows to keep track of each model with each metric. Furthermore, this solution can also be used for clients where time series analysis is used for forecasting. The current framework can be utilized to identify the outliers or the anomalies and treat them effectively.