Last week, I got into a situation where I had to scale the application to store unpredictable user sessions in Memcached. The vertical scaling could be extended up to a limit but to meet the application requirements, I had to go with horizontal scaling.

AWS does not provide any service to autoscale Memcached nodes according to the traffic trends. So, I had to create my own auto-scaling script based upon Memcached metrics. Today, we are going to learn, how to autoscale a Memcached cluster with respect to the eviction metric. Here are some prerequisites which I assume you have already setup:
- Memcached cluster running with at least one node
- AWS CLI tool installed on EC2 instance with access to following resources:
a. Full privileges on the elasticache
b. “Get” privileges on cloudwatch
c. “Publish” privileges on SNS - SNS topic to send scaling alerts
What Is Memcached Cluster?
The cache cluster is a combination for multiple nodes running in sync to provide a memory caching distributed system. When we launch a Memcached cluster, we receive a cluster endpoint and nodes created in the cluster also come up with their own endpoints. We have to configure cluster endpoint in our application and a node’s endpoint is used to debug any specific cache node issue. I have written a bash script to autoscale cache cluster. You can run this script without any modification. All the required parameters are defined as variables, so you have to pass these variables at the time of execution.
[js]bash memcache_autoscling.sh <region> <cluster_name> <eviction_count> <min_node> <max_node> <cool_down> <topic_arn>[/js]
Note:- Replace each variable listed in <> with real value.
Command Explanation:
- region: The region name in which your Memcached is provisioned. eg: us-east-1
- cluster_name: The name of your Memcached cluster. eg: test
- eviction_count: The eviction value of cluster. Please choose this value very wisely, the scaling action depends upon eviction count. The lower value may cause you to scale up and down multiple nodes in a short period of time. The tuned value depends upon your application size and workload but for small applications with light workloads I would recommend setting this to 100. eg: 100
- min_node:- The minimum number of nodes, which are required to serve normal hour traffic. eg: 1
- max_node: – Please don’t choose this value to a very high number unless you are really in demand and select this value depending upon your peak hour workloads. eg: 2
- cool_down: – In the case of scale up action, the new node will take some time to launch and get in sync with the cluster. The time, taken by the node to be in the active mode defined here as cooldown time. Its value depends upon your cluster storage and instance size. The recommended value is 300 seconds eg: 300
- topic_arn: The SNS topic is required to receive notification of each action performed at the time of scale-up or scale-down. eg: arn:aws:sns:us-east-1:1111111111:xxxxxxxxxx
The final command would look like this:
[js] bash memcache_script_new "us-east-1" "test" "100" "1" "2" "300" "arn:aws:sns:us-east-1:1111111111:xxxxxxxxxx" [/js]
Auto-scaling Steps:
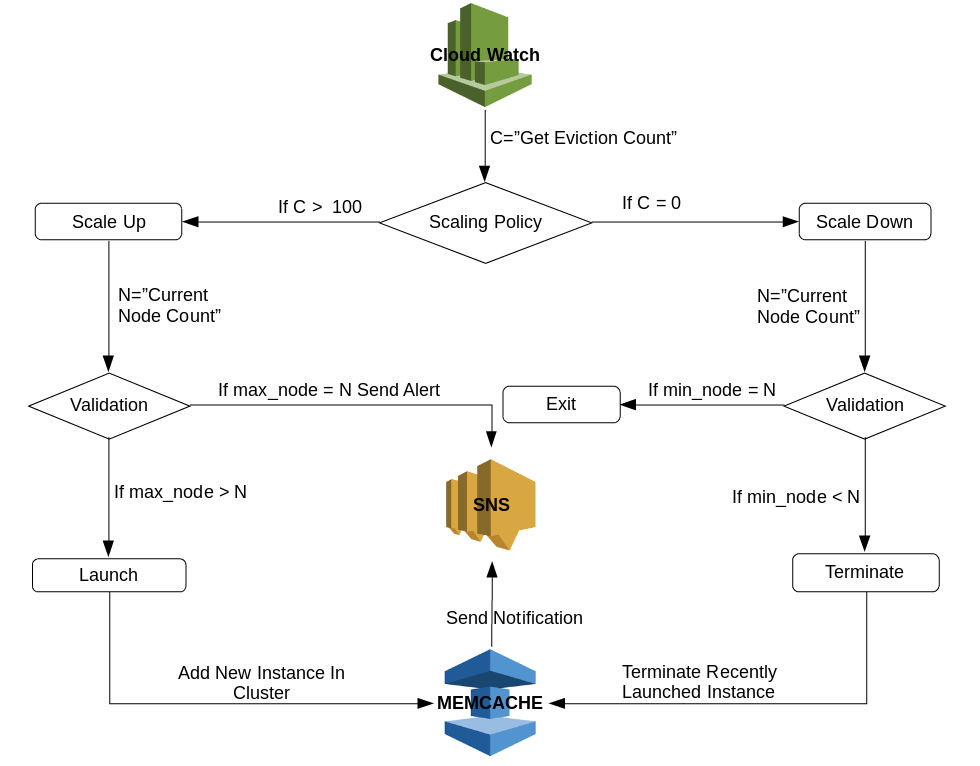
I consider that the existing Memcached cluster is running with one node and we want to perform a scale-up action when the reported value of eviction count is greater than 100. The max node value is 2, which we have decided based upon historical traffic trend and running instance capability.
1. It will get eviction count from CloudWatch metric and performed the action only if the last consecutive five values are either greater than 100 or equal to 0, no action will be performed for any value between 0 to 100.
2. In case, when eviction count is equal to zero then scale-down policy pass this value to a simple validator. The validator cross-checks existing node value and minimum node value, the scale-down action is performed only if current node value is greater than minimum node value. It will call termination operation on the recently launched node.
3. In case, when eviction count is greater than 100, the scale-up policy passes this value to a simple validator. If the validator finds current node count equal to max node count, the failed event will be triggered via SNS topic otherwise, it will launch a new node in the cluster.
4. Either it is the case of scale-up or scale-down, the action result will be pushed to SNS.
You can download this script from here and then run in Cron. Please make sure that the cooldown time is not higher than Cron’s scheduled interval. I would recommend to run this script in Cron with flock and you can check execution error logs in /tmp/scaling_log file. In case, if SNS is reporting an error: “scale-up/scale-down failed” then I would suggest you to increase your cooldown time value.
I hope this script will help you to resolve session persistence issue during peak workloads. In my next blog, we will perform some load tests on the cluster and see how the incoming traffic gets distributed among all the nodes in a single cluster.
Here are some more use-cases on AWS AutoScaling –
Pingback: This Week in AWS, October 24, 2015 – This Week In AWS | Amazon Web Services