
Building a Medallion Architecture for ETL in Microsoft Fabric: Polishing Your Data into Pure Gold!
In today’s data-driven world, to manage the sheer volume and variety of information, organizations are constantly looking for smart, scalable ways to wrangle their data, and that’s where the Medallion Architecture really shines. Paired with the powerhouse that is Microsoft Fabric, offers an incredible pathway to build slick, high-performance ETL (Extract, Transform, Load) processes. In this blog, we’re going to have a look on the Medallion Architecture and then see through exactly how you can implement this robust framework inside Microsoft Fabric.
Medallion Architecture is like a journey your data takes, starting as rough ore and gradually being refined into something truly valuable. This “multi-hop” architecture sorts data into three distinct layers: Bronze, Silver, and Gold. Each layer plays a crucial role, progressively cleaning, enriching, and data optimisation.
Bronze, Silver, and Gold Layers Explained
Bronze Layer (The Raw Quarry): This is where it all begins. Imagine your data landing here, just as it arrives from its source – be it a database, an API, a streaming service, or a flat file. It’s raw, untouched, and unadulterated. What’s cool about the Bronze layer?
- Immutability is Key: We don’t mess with data here. It’s kept in its original state, providing a full, trustworthy historical record
- Schema-on-Read Flexibility: No rigid rules about data structure at this stage. We simply ingest it as-is, accommodating all sorts of diverse data types.
- Budget-Friendly Storage: Typically, we store this data in cost-effective, often compressed formats like JSON, CSV, Parquet, or Avro.
Silver Layer (Refining): Data from the Bronze layer makes its way here for some serious attention. This is where we start whipping that raw data into shape, focusing on quality and consistency. Here’s what happens:
- Data Quality: We tackle missing values, correct data types, get rid of duplicates, and apply foundational validation rules.
- Conformed Dimensions for Clarity: This is where we start stitching together data from different sources into a unified view. Think of standardizing customer IDs or product codes across your various systems.
- A Historical Lens: Often, we’ll even track changes to records here, giving you a historical perspective on how your data has evolved over time.
Gold Layer (The Polished Masterpiece): The Gold layer delivers highly curated, aggregated, and optimized data, perfectly primed for direct consumption. This is the stuff that fuels your business intelligence tools, analytical applications, and empowers your data scientists. What makes it so special?
- Business-First Views: Data here is meticulously modeled to directly support specific business needs. We’re talking about slick aggregate tables, data marts, and classic fact/dimension tables.
- Performance: We optimize data storage (think Delta Lake with Z-ordering and partitioning) to ensure queries fly, and reports pop up in a flash.
- Security: Fine-grained access control is usually in place here, ensuring that folks only see the data they’re truly authorized to view.
- Empowering Self-Service BI: This layer is designed to empower your business users to explore and analyze data independently, cutting down on bottlenecks and speeding up insights.
Visualizing the Data Journey: Medallion Architecture
Here’s a diagram to help you visualize how data flows through these layers within Fabric ecosystem:
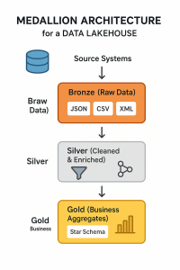
Implementing Medallion Architecture in Microsoft Fabric
Microsoft Fabric isn’t just another analytics platform; it’s a unified ecosystem that’s tailor-made for building a Medallion Architecture. Let’s see how it fits perfectly into each layer:
-
- Bronze Layer: Data’s Entrance
Purpose: Landing zone for raw, immutable data.
Lakehouse Tables: Fabric’s Lakehouse is super flexible, happily munching on Parquet, CSV, JSON, and even Delta Lake. For absolute raw immutability, just land the files as-is. If you need transactionality or schema evolution even at this stage, a quick conversion to Delta Lake within Bronze can be a smart move.
Data Pipelines: They pull data from all corners. Fabric’s Data Pipelines are good for:
Copy Data Activity: Effortlessly copy data from on-premises databases, cloud sources, APIs, or Blob Storage directly into your Lakehouse as those pristine raw files.
Dataflow Gen2: If you have some light initial transformations (like basic filtering or data type inference) that belong strictly to the raw ingestion phase, Dataflow Gen2 can handle it before the data settles in Bronze.
Real-time Data: For streaming data, you’ll want to tap into Event Streams or Azure Stream Analytics, which can then direct that live data into your Lakehouse or a KQL database within Fabric. - Silver Layer: The Data Transformation
Purpose: Convert raw Bronze data into clean, standardized, structured datasets. Putting it Into practice:
Data Cleansing & Standardization (Spark Notebooks): Spark’s distributed processing power is for:
Reading from Bronze: Simply point your Spark code to your Bronze Lakehouse tables (e.g., spark.read.format(“delta”).load(“abfss://<your_lakehouse>@onelake.dfs.fabric.microsoft.com/bronze/…”)).
> Banish duplicate records based on your unique business keys.
> Standardize formats for dates, strings, you name it.
Enforcing a Schema: Define and apply a strict, consistent schema when you write this cleaned data to your Silver layer. This brings order to the data chaos.
Tracking Changes (CDC): If you need to know when and how data changes, implement Change Data Capture (CDC) logic right in your notebooks, perhaps using MERGE statements with Delta Lake.
Data Storage (Writing to Silver): Store this beautifully cleaned and conformed data in Delta Lake format within its own dedicated spot in your Lakehouse.
Low-Code Transformations (Dataflows Gen2):
> For When Low-Code Calls: For simpler transformations, or if your team prefers a more visual, low-code/no-code approach, Dataflows Gen2 can certainly handle some Silver layer tasks, especially basic cleansing and merging. But for intricate logic or massive datasets, Spark Notebooks are optimum.
Orchestration (Data Pipelines): Use Fabric Data Pipelines to tie everything together. They’re perfect for orchestrating the execution of your Spark Notebooks or Dataflows, managing dependencies, and setting up schedules. - Gold Layer: Data, Ready!
Purpose: Deliver trusted, business-ready data for analytics, reporting, and self-service BI.
Aggregations & Data Marts (Spark Notebooks):
> Pull data from your Silver layer.
> Perform those crucial aggregations (like daily sales, monthly churn rates, etc.).
> Build out your perfect dimensional and fact tables for your data mart.
> Crucially, optimize how these tables are stored.
Data Warehouse (SQL Endpoint of Lakehouse): Here’s a neat trick: once your Gold layer Delta tables live in the Lakehouse, Fabric automatically exposes them via the Lakehouse’s SQL Endpoint. This means you can query them using good old T-SQL, making them instantly accessible to traditional BI tools and SQL gurus. For truly massive, complex enterprise data warehousing, a dedicated Fabric Data Warehouse offers specialized performance – you might even load your Gold data into it for that extra punch.
Power BI Semantic Models (Insights Layer): The Insight Engine: Connect Power BI directly to your Gold layer tables (either from the Lakehouse’s SQL Endpoint or a dedicated Fabric Data Warehouse). This is where you craft your powerful semantic models (datasets) that underpin all your self-service BI efforts, leading to insightful reports and stunning dashboards.
Data Sharing (OneLake Shortcuts): Leverage OneLake shortcuts to create virtual copies of your Gold tables in different workspaces. This is a way to share data across teams without actually duplicating it, simplifying data governance immensely.
- Bronze Layer: Data’s Entrance
Why This Medallion Magic Works So Well in Microsoft Fabric
Implementing the Medallion Architecture within Microsoft Fabric isn’t just about following a pattern; it’s about unlocking a cascade of benefits:
- Elevated Data Quality: The step-by-step refinement means your data gets cleaner and more reliable with each layer.
- Top-Tier Data Governance: Clear separation of concerns and traceability through the layers make understanding your data’s journey a breeze.
- Unleashed Agility: Each layer is somewhat independent, you can develop and evolve parts of your architecture without breaking everything else.
- Performance that Sings: Data is continuously optimized for consumption as it moves through the pipeline, meaning faster queries and happier users.
- Smart Cost Management: We use affordable storage for the raw stuff and only optimize for peak performance where it truly matters.
- The Single Source of Truth: Gold layer becomes the definitive, trusted source for all your crucial business data.
Wrapping Up: Your Data’s Golden Future
Embracing the Medallion Architecture within Microsoft Fabric offers a robust, scalable, and wonderfully efficient blueprint for managing your organization’s data assets. By strategically implementing those Bronze, Silver, and Gold layers with Fabric’s incredible suite of tools – from Lakehouses and Data Pipelines to the raw power of Spark Notebooks and the intuitive brilliance of Power BI.
