Introduction
In the rapidly evolving world of data analytics and business intelligence, the accuracy and dependability of data transformations are critical. Data validation plays a key role in ensuring that the modifications you apply to your data are efficient and precise. To streamline this critical process, a new approach that leverages the power of DBT (Data Build Tool) to enhance data validation and testing. In this blog, we will dive into a new data validation method that harnesses the capabilities of DBT to test data transformations precisely. This method not only simplifies the validation process but also helps you to make a robust framework for validating and tracking on test outcomes. At its core, this approach revolves around the use of macros to define test cases, steering away from the conventional inbuilt tests of DBT.
About DBT
DBT (Data Build Tool) is a command-line tool and a development environment that streamlines and simplifies the process of transforming data in your data warehouse. It is commonly used in data engineering and analytics workflows. DBT allows you to transform data by defining SQL models that specify how data should be transformed. As DBT plays the role of ‘T’ in the ETL process, it is primarily used for data transformation and modelling. With DBT, you can extract data from various sources, transform it according to your business logic, and load it into your data warehouse for analysis and reporting.DBT helps you build a robust and maintainable data transformation pipeline, making it easier to leverage data for analytics and reporting.
For more detailed information about DBT and how it can enhance your data transformation workflows, visit [https://docs.getdbt.com/docs/introduction].
Defining Macros Structure in a DBT Project
Let’s start with naming and organizing the macros in such a way that it conveys their specific functions, ensuring clarity and ease of maintenance as the project evolves. These macros are then organized into distinct directories within the project structure:
Generic_tests: This directory is dedicated to macros defining generic test cases, offering adaptability across various tables and schemas according to the project.
Custom_tests: In contrast, custom_tests contains macros tailored to validate data transformation logic unique to specific requirements.
Test_suite: The test_suite directory houses a macro that serves as an orchestrator, coordinating the execution of generic and custom test cases. This simplifies the validation process for tables that require a combination of different tests.
Utils: The utils directory is a repository for utility macros, facilitating recurring tasks like data insertion and regression suite management.
In this organized framework, the careful naming of macros and their placement into purpose-driven directories enhances clarity, maintainability, and efficiency in data validation and transformation processes, making the DBT project a reliable and well-structured tool for these tasks.
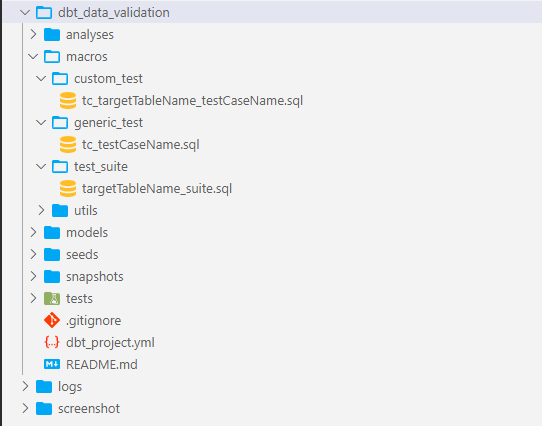
How do we define generic, custom test cases and test suites?
Generic Tests
Every macro that we define as a generic and custom test case should return ‘PASS’ and ‘FAIL’ as test case status. Inside the SQL statement block, we basically check the number of rows it returns after executing the query, and if that query returns zero failing rows, it passes and the test case has been validated.
Now, let’s see how we define our generic and custom test cases, taking the null value test case as an example of a generic test.

The macro begins with an {% if execute %} conditional statement. If execute is used so that if any jinja that relies on the result being returned from the database will not through error so wrap the code inside it (assumes that it has returned the result, when, during the parse phase, this query hasn’t been run. To work around this, wrap any problematic Jinja in an {% if execute %} statement).
1. Iteration Over target_column_dictionary :
Inside the conditional block, the first loop that iterates through the target_column_dictionary is for getting the name of the target table, which is stored as a key, and another loop is for getting the names of target columns stored as values. These are the column names associated with a specific target table that is to be tested.
2. Logging :
The code uses {{ log(column_name, info=true) }} to log the name of the column being processed. This logging helps debug and track the execution of the macro.
3. Query Building :
A SQL query is dynamically constructed and assigned to the query variable. As you have seen, there are two arguments, target_database, and target_schema, which are then templated with the query, and the target_table, which is also templated with the query which we are getting from target_column_dictionary to make our test cases “generic”: it can run across as many tables as you like.
4. Running the Query :
The {{ run_query(query) }} statement is used to execute the dynamically constructed SQL query. This will run the query against the specified table and column.
5. Query Result Extraction:
The result of the query execution is stored in the result variable. The status of the query execution (either ‘PASS’ or ‘FAIL’) is extracted from the query result and stored in the query_status variable.
6. Logging Query Status and Query ID:
The macro logs both the query_status and a unique query identifier (query_id) for each iteration. This information can be helpful for tracking and reporting.
7. Inserting Test Report :
At last, we call another macro named insert_macro to insert the test results into a test report. It passes various parameters, including query_id, suite_id, and the test result (query_status), among others. This macro is designed to automate the testing of null values in specific columns of tables within a given database and schema.
Custom Tests
Custom test cases share similarities with generic test cases in terms of following defined steps and principles for data validation. However, a key distinction lies in the specificity of custom test cases. Unlike generic test cases that typically operate on multiple tables with generalized query logic, custom test cases are tailored to a single table, rendering them table-specific in nature.
The fundamental difference arises from the fact that custom test cases often incorporate hardcoded values and transformation logic uniquely designed for a particular table’s characteristics and requirements. This level of specificity ensures that the validation process remains highly tuned to the nuances of that specific dataset, effectively pinpointing any issues or anomalies that are table-specific.
In essence, while generic and custom test cases serve the overarching goal of data validation, custom test cases excel in precision and relevancy by focusing exclusively on the intricacies of individual tables. This tailored approach ensures that the validation process remains tightly aligned with the unique attributes and transformation needs of each dataset, ultimately enhancing the accuracy and dependability of the data validation process.

Test suites
A test suite is a meticulously crafted framework designed to facilitate the validation of table transformations, encompassing a combination of both generic and custom test cases. The primary purpose of a test suite is to orchestrate the execution of multiple test cases that collectively evaluate the integrity of data transformations applied to tables.
When invoking a test case within this suite, a series of crucial arguments are passed. These arguments include ‘target_column_dictionary’, ‘target_database’, and ‘target_schema’. These arguments are utilized to guide the test cases in their examination of the data transformations. However, it’s important to note that these arguments are exclusively applicable when the test case in question is of a generic nature.
In cases where the test case is custom-made, an expanded set of arguments must be supplied. This includes ‘source_database’ , ‘source_schema’ , and potentially additional parameters that tailor the test case to its unique requirements.
The foundation of this suite is built upon a ‘target_column_dictionary’. This dictionary serves as a key-value pairing mechanism, residing within the ‘dbt_project.yml’ file. In this dictionary, the keys represent the target tables that undergo validation, while the corresponding values denote the specific target columns within these tables that require scrutiny. This configuration ensures that the suite knows precisely what data elements to evaluate.
To illustrate this dictionary further, consider an example :
vars: target_column_dictionary: {'sales_data': ['order_date', 'product_id', 'revenue']}
In this instance, the suite has been instructed to focus its testing efforts on the table named ‘sales_data,’ specifically examining ‘order_date’ ,’product_id’ and ‘revenue’ for the presence of any anomalies or issues.
In summary, a test suite is a comprehensive framework that streamlines the validation process of table transformations, leveraging a combination of generic and custom test cases. It relies on a meticulously defined ‘target_column_dictionary’ to pinpoint the exact tables and columns requiring validation, ensuring the accuracy and reliability of data transformations.

Execution Flow for DBT Data validation testing.
The execution process for validating table transformations in a DBT (Data Build Tool) project involves the creation of test cases, the organization of test suites, and the execution of these suites. To provide a clearer picture, let’s break down the execution flow, and then we’ll delve into the concept of a “regression suite” using the previously explained test suite :
1. Creation of Test Cases:
Begin by creating a set of test cases, which can be categorized as either generic or custom. These test cases are designed to validate the data transformations applied to specific tables.
2. Definition of Test Suites:
Next, define test suites that encompass all the tables you want to validate. These test suites serve as collections of test cases, both generic and custom, relevant to a particular table or set of tables.
3. Writing Test Cases within Test Suites:
Within each test suite, write the individual test cases. These test cases can include both generic and custom tests, depending on the validation requirements for each table.
4. Execution of Test Suites:
To test a specific table, execute the associated test suite using the following command:
dbt run-operation {macro} –args ‘{args}’
– In the command above:
– {macro} refers to the macro that initiates the execution of the test suite.
– –args allows you to pass arguments to the macro.
– ‘{args}’ represents the arguments you pass to the macro, which could include variables and their values. For example, if you need to specify the target table, you might pass ‘{table_name: my_table}’.
5. Regression Suite Macro :
To execute all the defined test suites in a single execution, create a macro called “regression_suite” or a similar name.
– Inside this macro, list and call all the individual test suites you’ve created.
6. Execution of Regression Suite :
When you want to run all the tests for your data transformations in one go, execute the regression suite macro using the same ‘dbt run-operation’ command:
dbt run-operation regression_suite
– This command will trigger the execution of all the test suites, ensuring comprehensive validation for all target tables.
By following this execution flow, you can effectively manage and execute your data validation tests for various tables, whether they require generic or custom test cases, and streamline the process by running all suites at once through the regression suite macro.
Advantages of Using Macros for Data Validation Over DBT Inbuilt Tests:
1. Customization and Flexibility:
Using macros for data validation provides a high degree of customization and flexibility. While DBT’s inbuilt tests are limited to predefined validations, macros allow you to create tests tailored to your specific business logic and data transformation requirements. This flexibility is particularly valuable for complex data validation scenarios.
2. Reusable Test Logic:
Macros enable you to define and reuse test logic across multiple tables and schemas. By templating queries and parameters, you can create generic test cases that work across various data sources and structures. This reusability reduces redundancy in your testing code.
3. Simplified Test Suite Management:
Macros make it easier to manage test suites. You can organize your test cases into purpose-driven directories, such as generic tests and custom tests, streamlining the organization of your validation logic. This structured approach enhances clarity and maintenance as your project evolves.
4. Precision in Custom Testing:
Custom test cases, powered by macros excel in precision. They allow you to design tests specifically tailored to the unique characteristics and requirements of individual tables. This precision ensures that the validation process remains tightly aligned with the nuances of each dataset, enhancing the accuracy and dependability of the data validation process.
5. Enhanced Logging and Reporting:
Macros offer advanced logging capabilities, allowing you to track the execution of individual test cases and capture important information. This detailed logging aids in debugging and reporting, making it easier to identify and address issues during data validation.
6. Scalability and Maintainability:
The use of macros provides scalability and maintainability benefits. As your data warehouse and transformation pipelines grow, you can easily add new test cases and suites without creating code sprawl. Macros promote a structured and organized approach to managing an increasing number of validation scenarios.
7. Streamlined Regression Testing:
The concept of a regression suite, which calls all the individual test suites, streamlines the execution of comprehensive validation tests across your entire project. This approach simplifies the process of running extensive tests, ensuring that data transformations remain accurate as your project evolves.
8. Improved Collaboration:
Macros enhance collaboration among team members. With clear and organized test logic, team members can easily understand and contribute to the validation process. This transparency fosters collaboration and ensures that data validation remains a collective effort.
9. Adaptability to Evolving Data Needs:
Data needs can change frequently so, Macros allow you to adapt your validation logic quickly to accommodate new data sources, transformations, or business requirements. This adaptability ensures that your data validation process remains relevant over time.
It leverages macros for data validation in DBT and offers numerous advantages over relying solely on DBT’s inbuilt tests. It empowers data engineers and analysts to create highly customized, precise, and maintainable validation processes that align with the specific needs of their data transformations, ultimately contributing to the accuracy and dependability of data in the context of data analytics and business intelligence.
Conclusion:
In this blog, we have explored a new approach that harnesses the power of DBT (Data Build Tool) to elevate the art of data validation and testing.
By delivering this new method, we have uncovered a process that not only simplifies data validation but also empowers you to construct a robust framework for validating and reporting of tests. At its core, this approach relies on the versatile use of macros to define test cases, marking a departure from the conventional inbuilt tests offered by DBT.
Through the journey of understanding DBT, structuring macros, and defining generic and custom test cases, we have seen how this method adapts to complex data validation requirements. Customization, precision, scalability, and enhanced collaboration emerge as key benefits, allowing you to tailor your validation process to the unique needs of your data transformations.
The concept of test suites, orchestrating the execution of various test cases, further streamlines the validation process. It brings together the power of macros, generic tests, and custom tests to ensure the integrity of data transformations across tables and schemas. Moreover, the execution flow we’ve outlined simplifies the management of your data validation tests. With the ability to execute all defined test suites through a regression suite macro, you can comprehensively validate your data transformations in a single, efficient operation.
In the fast-paced world of data analytics, where data needs evolve continually, macros offer adaptability to changing requirements. This method ensures that your data validation process remains relevant and dependable over time. In summary, harnessing macros for data validation in DBT offers a powerful and flexible approach that empowers data professionals to ensure the accuracy and dependability of data transformations.