
In the past decade, we have seen industries evolve their businesses by migrating their applications from monolithic to microservices using various container orchestrations such as K8s, ECS, Docker etc. In this process, a lot of effort has been put into designing architecture that should be scalable, robust, reliable, and so on. As application and business start evolving, we must transit our focus to optimize resources and limit allocations so that applications will not be under or over-utilized the resources. Hence reducing the cost with the right-size workloads.
Before directly hopping into concepts, I would like to tell the intent of this blog via a problem statement.
Problem Statement
Python Based RestFul API running as POD in K8s Cluster with the below:
- No AutoScaler(HPA or VPA)
- No Correct QoS (Quality of Service)
- No Observibilty Dashboard
- No Application Workload Trends
- Stress/Load Testing can’t benchmark resource limits and requests as traffic is majorly dependent on real data based on customer profile.
In case of high traffic or heavy load, API gets crashed. So, in order to make it available, we need to scale out the pod; therefore, it requires HPA to be in place. Since we have no QoS or history of application that could help us benchmark our HPA thresholds. This is where GOLDILOCKS comes into existence.
In this article, we will share guidance and the journey of implementing Goldilocks, which helped us in optimize resource allocation and right-size application via QoS recommendations.
Ramification of Resources Right-Sizing in K8s Application
Right-sizing of resource allocation in K8s can be done by embedding resource specification block in application deployment manifests, and it will ramify application in the below ways.
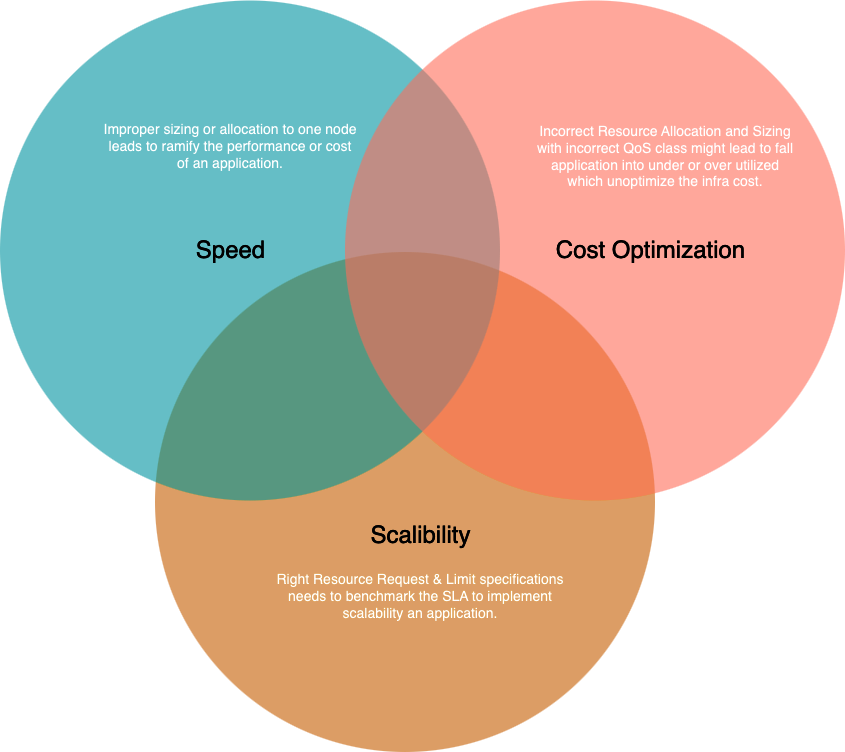
Pillars of Application
Introduction to Goldilocks
Goldilocks is a Fairwinds open-source project which helps organisation by accelerating the correct or right size of resource requirement to their K8s Application. It is composed of K8s VPA(Vertical Pod Autoscaler) which inturn provides a controller which is responsible to create VPA Objects for workloads in your cluster. Along with this, a dashboard which visualize resource recommendations for the all enabled/monitored workloads.
Solution Overview: This will contain a solution overview as a whole, starting from its architecture, installations, deployment of the application, and checking resource recommendations on the dashboard.
Architecture of Solution
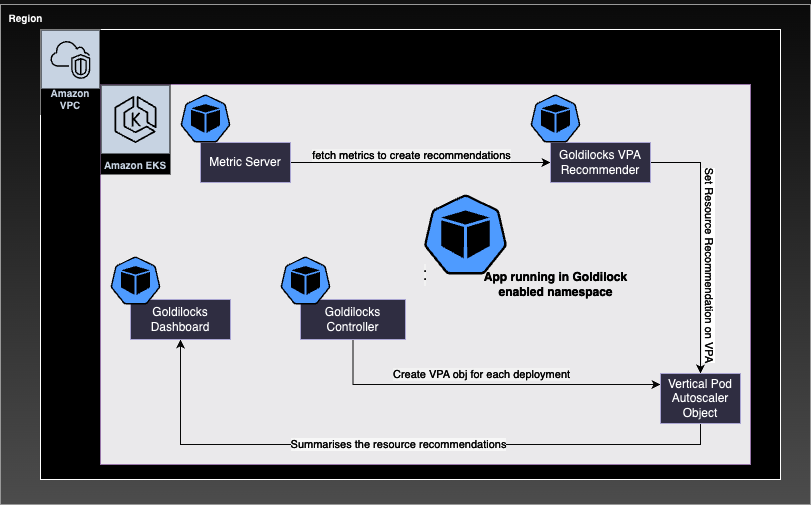
(a) Installation of Goldilocks Pre-requisites and Dependencies: There are few prerequisites and dependencies that are required to be in place before goldilocks installation.
Below are the prerequisites:
Check if the Metric Server is deployed or not?
In this step, we are going to check if the metric server is installed on an existing cluster or not, if not then run the below commands:
helm repo add metrics-server https://kubernetes-sigs.github.io/metrics-server
helm upgrade --install metrics-server metrics-server/metrics-server
# Verify metric server installation
kubectl top pods -n kube-system
Labelling and Enabling Target Namespace
How can we enable the target namespace for resource recommendation?
Target Namespaces: Those namespaces for which we want resource recommendations can be enabled by simply adding the below label to it. goldilocks.fairwinds.com/enabled: true Label to a namespace.
kubectl create ns mvc
kubectl label ns mvc goldilocks.fairwinds.com/enabled=true
Deploying Goldilocks in Cluster
Goldilocks Deployment deploys three K8s objects (Controller, VPA Recommender, Dashboard)
- Controller responsible for creating the VPA objects for the workloads for target namespace whose is enabled for a Goldilocks recommendation.
- VPA Recommender is responsible for providing the resource recommendations for the workloads
- Dashboard will visualize the summary of resource recommendations made up by the VPA recommender.
helm repo add fairwinds-stable https://charts.fairwinds.com/stable
helm upgrade --install goldilocks fairwinds-stable/goldilocks --namespace goldilocks --create-namespace --set vpa.enabled=true
cloudmonk@Garvits-MacBook-Air ~ % kubectl get po -n goldilocks
NAME READY STATUS RESTARTS AGE
goldilocks-controller-b764bbb9-r9sxt 1/1 Running 2 (6d2h ago) 16d
goldilocks-dashboard-85c954ff99-bbmdt 1/1 Running 2 (6d2h ago) 16d
goldilocks-dashboard-85c954ff99-vqstm 1/1 Running 2 (6d2h ago) 16d
goldilocks-vpa-admission-controller-bbb69d975-952d6 1/1 Running 2 (6d2h ago) 16d
goldilocks-vpa-recommender-68d77754b4-ms7vv 1/1 Running 2 (6d2h ago) 16
Application Integration to Goldilocks
In this step, we integrate our existing application in the cluster for which we want to generate some resource recommendations; the Moment you set the label in the above steps. Goldilocks VPA Recommender Object gets created for each application deployment.
loudmonk@Garvits-MacBook-Air Desktop % kubectl get vpa -n mvc
NAME MODE CPU MEM PROVIDED AGE
goldilocks-mvc-app Off 15m 104857600 True 23s
Check Goldilocks Recommendation Dashboard
Goldilocks Dashboard can be accessed at port 8080; use the below command to access and check the resource recommendations here.
kubectl -n goldilocks port-forward svc/goldilocks-dashboard 8080:80
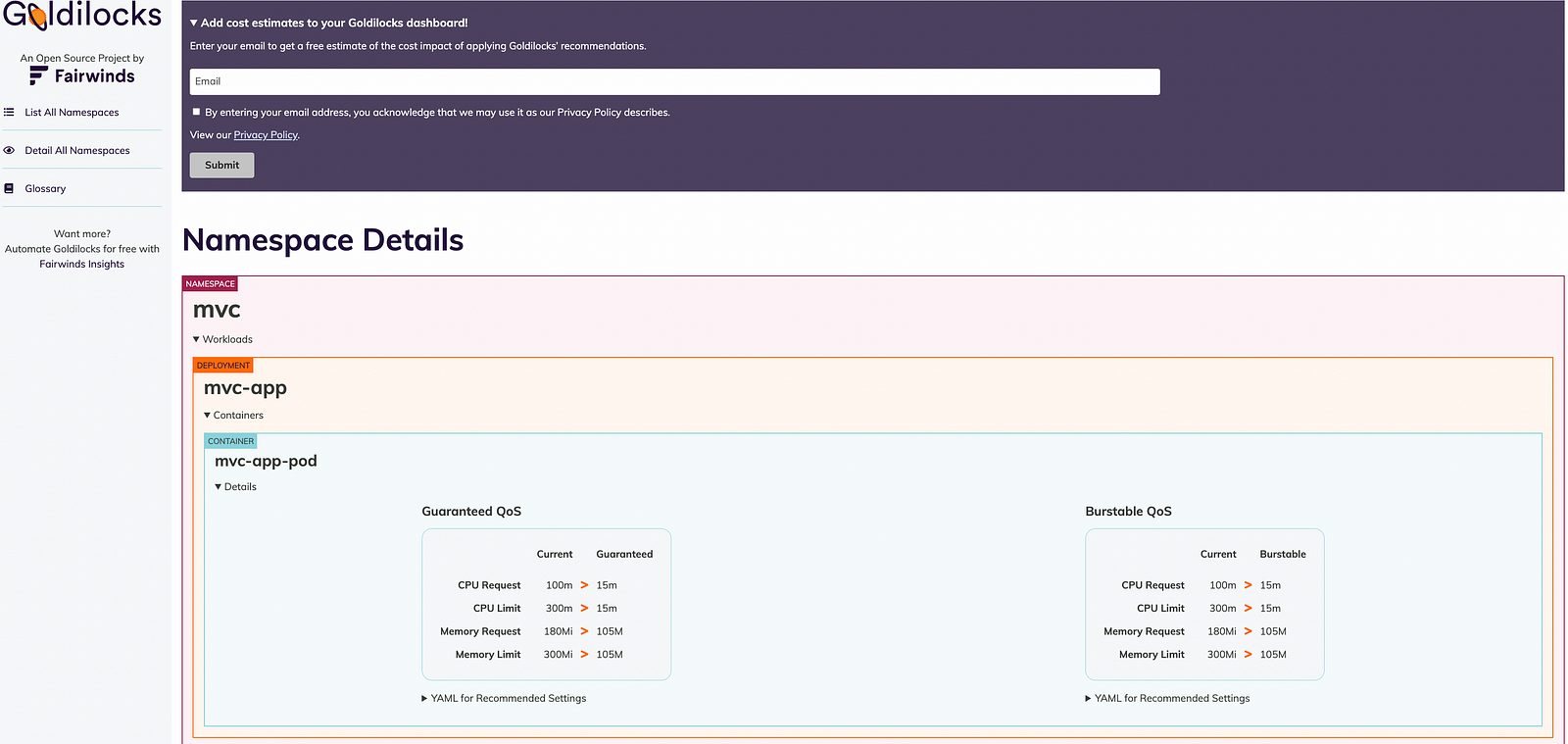
Before start checking recommendations, let’s understand What is QoS?
“It stands as Quality of Service (QoS) class. Kubernetes assigns each Pod a QoS class based on the resource requests and limits of its component Containers. QoS classes have been used by Kubernetes to decide which Pods to evict from a Node experiencing Node Pressure. In here, we have observed that the recommendations are available for two distinct (QoS) types: Guaranteed and Burstable. For more details, please refer link” Let’s analyze our targeted namespace (mvc) where our application is deployed as mvc-app.
In the above screenshot, we can clearly see that there are two QoS that recommend the memory and CPU limit for our application.
It is clearly observed that we have given high compute resources to our application which get over-provisioned, and based on Goldilocks recommendations, it can be optimized. The Burstable QoS recommendation for CPU request and CPU limit is 15m and 15m compared to the current setting of 100m and 300m for Guaranteed QoS. Memory requests and limits are recommended to be 105M and 105M, compared to the current setting of 180Mi and 300 Mi.
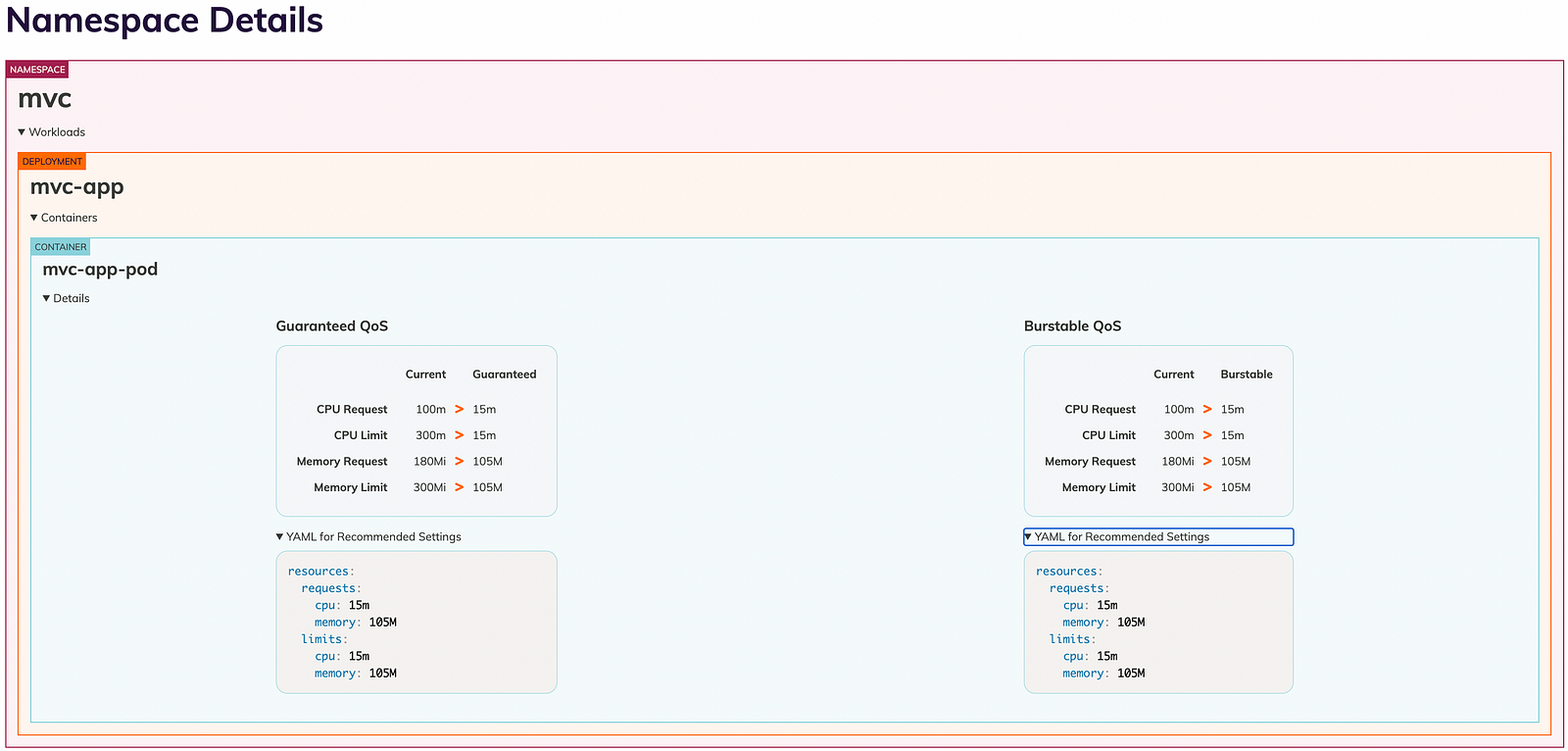
In order to follow and embed the recommended resource specs, we can just copy the respective manifest file for the desired QoS class & deploy the workloads by just editing the deployment or updating its helm chart or standalone manifest, which will then be right-sized and optimized.
For instance, if we want to apply QoS recommendation to our application. We can do it by editing the deployment.
kubectl edit deployment mvc-app -n mvc
Let’s run the kubectl edit command to the deployment to apply the recommendations:
Apply the recommended YAML in the resource block of the deployment manifest. Once it gets applied, we can see pods get restarted and come back with updated config.
kubectl describe deployment mvc-app -n mvc
kubectl describe deployment mvc-app -n mvc
Name: mvc-app
Namespace: mvc
CreationTimestamp: Fri, 15 Sep 2023 03:18:28 +0530
Labels: <none>
Annotations: deployment.kubernetes.io/revision: 2
Selector: app=mvc-app-pods
Replicas: 1 desired | 1 updated | 1 total | 1 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=mvc-app-pods
Containers:
mvc-app-pod:
Image: public.ecr.aws/mvc-uat/mvc-app:latest
Ports: 8080/TCP, 9404/TCP
Host Ports: 0/TCP, 0/TCP
Limits:
cpu: 15m
memory: 105Mi
Requests:
cpu: 15m
memory: 105Mi
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: mvc-app-67cdc49555 (1/1 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 57m deployment-controller Scaled up replica set mvc-app-6cbbcf458d to 1
Normal ScalingReplicaSet 41s deployment-controller Scaled up replica set mvc-app-67cdc49555 to 1
Normal ScalingReplicaSet 24s deployment-controller Scaled down replica set mvc-app-6cbbcf458d to 0
Conclusion
Through this article, we observed how Goldilocks identified the right size for resource requests and limits, which further helped us to benchmark HPA. It helped in making fast decisions to set the correct QoS for our application with minimal effort, which usually takes a lot of effort by looking at observability trends. It also makes our client happy as it has made a significant impact on cost in the first place.