
Load Blancing of Amazon RDS Read Replica
AWS provide some intensive services and these are easily manageable and as being admin there is less overhead to scale up your application infrastructure. In automated deployments if we are planing to horizontally scale your database, with help of a single click we can populate read replica of our running database.
But to handle large volume of traffic we have to scale database with two or more read instance. To trading off availability and consistency it’s necessary to put all read instance under single load balancer. So, the traffic would be equally distributed and manageable. We will configure haproxy as load balancer on Ec2 instance to serve read requests.
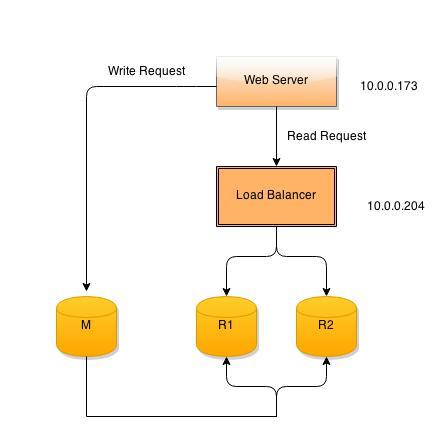
Here is common architecture which we are using:-
1. Web application:- Deployed on Web Server.
2. Load balancer:- Ec2 instance with ubuntu 14.
3. RDS:- Two Read Replica of master RDS.
Configuration Steps:-
1. RDS Configuration.
2. HA PROXY Configuration.
3. Load Balance testing.
1. RDS Configuration.
We need two users on database, the first user (ha_check) for haproxy active check and second user (ha_read) for integration within application. We will create these users on master database as changes will replicate to slave servers by itself. First off all create “ha_check” user which will be accessible from load balancer (10.0.0.204)
[js]mysql -uroot -pPASSWORD -hmaster.xxxxxxx.ap-southeast-1.rds.amazonaws.com
> create user ‘ha_check’@’10.0.0.204’;
> flush privileges;[/js]
Now create second user with read only privileges.
[js]
>grant select, show view on test.* to ‘ha_read’@’10.0.0.204’ identified by ‘password’;
> flush privileges;
[/js]
2. HA PROXY Configuration.:-
Install haproxy package using apt-get.
[js]
apt-get install haproxy
[/js]
By Default the proxy mode is disabled and to enable it change /etc/default/haproxy file.
[js]
ENABLED=1
[/js]
The main config file is /etc/haproxy/haproxy.cfg and after editing the final file looks like:-
[js]
global
log 127.0.0.1 local0 notice
user haproxy
group haproxy
daemon #Makes the process fork into background.
defaults
log global
retries 2
timeout connect 3000
timeout server 5000
timeout client 5000
# Both salve server defined under this section
#listen <ANY NAME>
# bind <Load balancer Ip Address>:3306
# mode tcp
# option mysql-check user <haproxy check user name> # ha proxiy active check user
# balance <load distribution algoritham>
# server <any_name> <Read replica end point>:3306 check weight <no of request to be sent> fall <connect retry to declare dead> fastinter <interval between checks in ms>
listen rds-cluster
bind 10.0.0.204:3306
mode tcp
option mysql-check user ha_check
balance roundrobin
server mysql-1 ha1.xxxxxxx.ap-southeast-1.rds.amazonaws.com:3306 check weight 1 fall 2 fastinter 1000
server mysql-2 ha2.xxxxxxx.ap-southeast-1.rds.amazonaws.com:3306 check weight 1 fall 2 fastinter 1000
# To chck load balancer status
#listen <ANY NAME>
# bind <Server IP>:8080
# mode http
# stats enable
# stats uri /
# stats realm Strictly\ Private
# stats <USERNAME>:<PASSWORD>
listen cluster-check
bind 10.0.0.204:8080
mode http
stats enable
stats uri /
stats realm Strictly\ Private
stats auth admin:password
[/js]
Restart haproxy service to apply changes.
[js]
service haproxy restart
[/js]
3. Load balance testing:-
To check haproxy setup, login into your web server and run this command.
[js]
mysql -h10.0.0.204 -uha_read -ppassword -e "show variables like ‘server_id’"
‘
[/js]
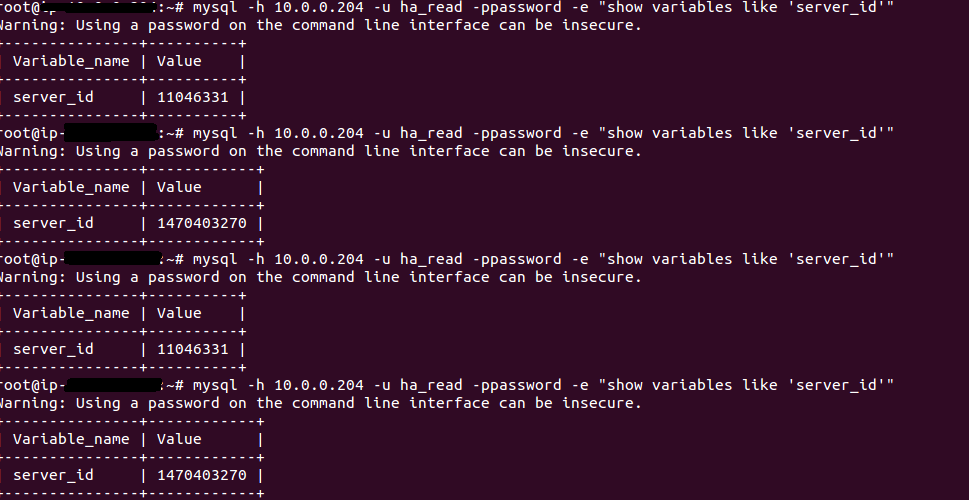
Each time we are requesting server_id the response value is different. It stats haproxy equally distributing traffic between two nodes. You can test the results while changing weight parameter in /etc/haproxy/haproxy.cfg.
It is also important to keep your eyes on load balancer health. Login into your browser to see real time load balancer status.
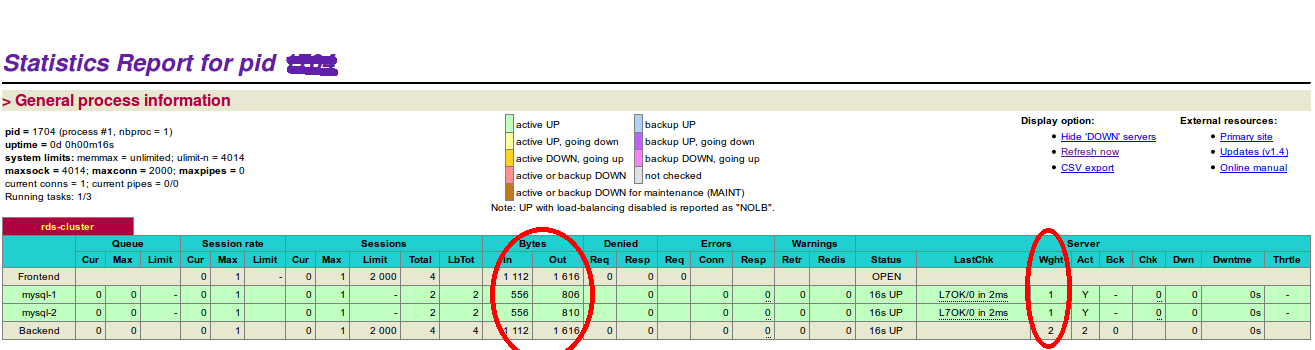
Here we tested the scenario with two slave servers. You can add as much server as you want, but creating more read replica bring more work head on master server.



Isnt haproxy a single ponit of failure now. How do you plan to mitigate risks of haproxy or ec2 instance running haproxy going down.
Hi,
I have doubt, In AWS site, they told we need to route the database call to read replica using our application? Without a change in our application AWS, RDS will automatically redirect the call to read replica ??
AWS RDS will automatically redirect the database call to read replica without application side code change?
Thank you very much ! You have cleared out the difference between them.
Is there a way of possible routing of read/write queries via outside application so that existing application can be moved to read only replicas without any change ?
Why HAProxy and not ELB?
You can not point a ELB at RDS instances. Only at actual EC2 instances
Have you deployed this setup in production environment ? If yes how was the performance and is there anything else to note ?
Hi Rahul,
We have implemented the same solution to achieve scalable architecture for read traffic. No doubts there is significant increase in app performance. It is not a self-healing service, so you just need to take care of the replication lag and the required number of read nodes behind the proxy.