
What is Amazon Redshift and why you should definitely use it?
So you have spent some odd years of your software development career and now you know many of those RDBMS implementations in and out. In fact, you also already know that RDBMS is not the only enterprise storage and due to frequent scalability issues you encountered, someday you found about Big Data tools.
Chances are you were flabbergasted with the new No-SQL ideologies and quickly adopted MongoDB, Cassandra, Hadoop etc. to sort all your scalability requirements. But deep down you do miss those good old days when data was relational and life was transactional. You might be even silently praying for someone to give you the best of both worlds. The scalability of No-SQL with performance of SQL. Guess what your dreams just came true.
Gone are the days where database developers and database administrators were separate entities. Forget about hiring a database specialist team everytime you wanted to scale up your servers. Amazon Redshift is here. In Amazon’s words:
An Amazon Redshift data warehouse is an enterprise-class relational database query and management system.
And that sums it up! Yes, it’s that simple and real.
Do have a look at below diagram for a look at Redshift’s architecture:
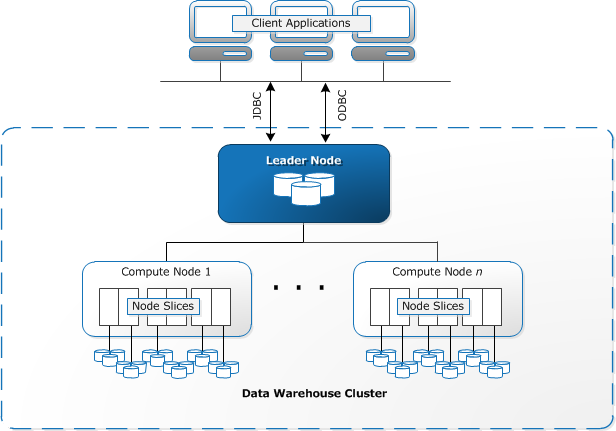
AWS Redshift Data Warehouse architecture
Some important observations from above diagram:
- Client applications employ either JDBC or ODBC to connect to Redshift Data Warehouse. Amazon Redshift is based on PostgreSQL, so most existing SQL client applications will work with only minimal changes.
- An Amazon Data Warehouse is structured as a cluster. A cluster is one or more compute nodes. A cluster having more than one compute nodes, appoints one node as leader node. This leader node is responsible for communication with client applications and to distribute compiled code to other compute nodes for parallel processing. Once compute nodes return fildered records, leader node combines result to form final aggregated result.
- Node Slices is partitions within compute nodes to provide parallelism.
Some features that Amazon Redshift employs for performance are as follows:
- Massively parallel processing: Redshift is optimized to consume the processor capabilities of your server.
- Columnar data storage: A database server’s performance depends on the read/write speed from the disk. Traditionally, data is stored on disk blocks in a row-wise fashion. This storage is suitable where frequent data-access fashion is to fetch all attributes of a record, but since in the context of Big-Data, we generally fetch only a sub-set of attributes for our entities for a huge number of records. Storing one attribute for many records in one memory block is thus suitable for Big Data context.
- Data compression: Since compressed data requires less memory, it takes lesser read operations to copy data from disk to memory. Once the required data is copied to memory it is then extracted to evaluate queries.
- Query optimization: Redshift query optimizer is programmed to compile sql in a fashion that supports parallel processing and data compression. In other words, it is MPP-aware and thus transforms queries to a better form which is optimized to exploit other performance features.
- Compiled code: Redshift employs compilation as opposed to interpretation. Thus providing cached queries for better performance.
So, data warehousing is no more a No-SQL only thing. In fact you can migrate your existing data warehouses with little to no change to Amazon Redshift and achieve more with less.



Its amazing! I found so many interesting things about Redshift from this blog. Redshift provides the best security to your database by destroying the insider threats and attackers which always harm your whole database.
Have you used Redshift in any client implementation? What was the use case like?
Yes Aakash, I worked on one of our clients’ prototype where he wanted to compare the feasibility of a cloud warehouse.