Introduction
Sometimes We have to keep our database backup for longer retention for Security and DR Compliances in RDS. But as we know, if we have a longer backup period in RDS, it will also create more burden on the pocket, as RDS charges for storage in Normal S3 bucket format. So we can export our backup snapshots from RDS to an S3 bucket with Apache Parquet Format, which can save some charges, and we can use those snapshot data for future reports or compliance checks as well using Athena and Glue.
- We can export all types of backup from RDS to S3
- Steps to export to s3:
- Create an S3 bucket with Proper IAM Permission
- Create a KMS key for server-side encryption (SSE)
- We can use CLI or GUI to perform this action
- No Impact on Performance as export runs in the background
- Data will be exported into S3 in Apache Parquet format. It is 2x faster and stores 1/6 of the storage compared to the normal test format
- We can use that exported data to create reports using Athena and EMR
Architecture of Migration Process
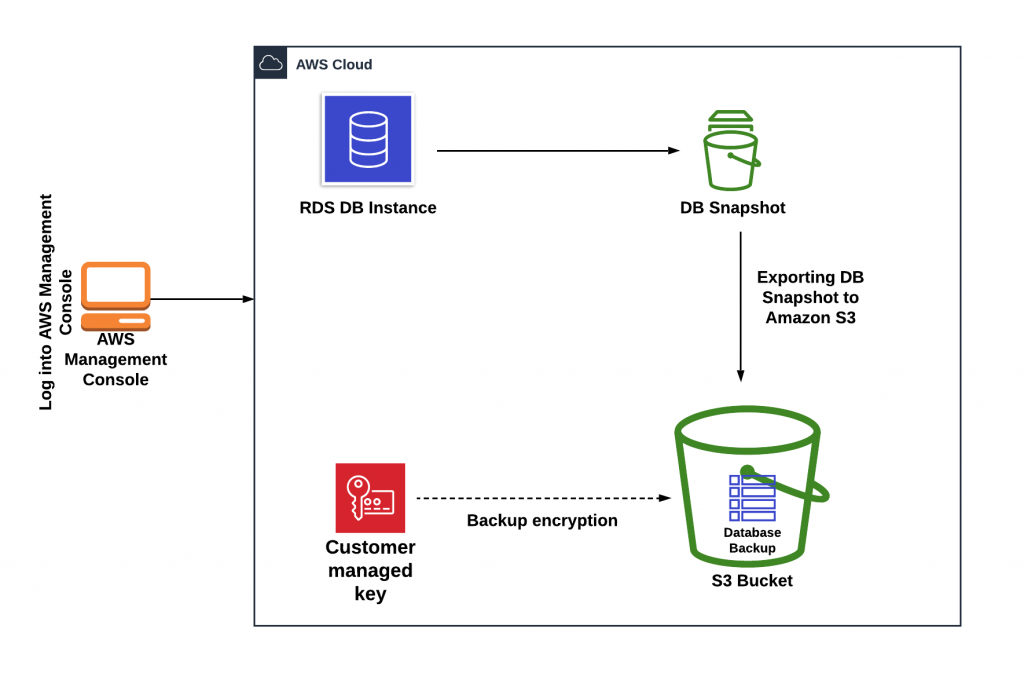
Used Tools and AWS Components –
- AWS RDS
- AWS S3
- AWS KMS
- AWS IAM
- AWS Glue
- AWS Crawler
- AWS Athena
Steps Performed for this Activity
- Create an S3 bucket in AWS
- Create a KMS Key or use the Existing Key for Encryption
- Take RDS Database Snapshot
- Export Snapshot to S3 Bucket with Parquet Format
- Validate the Snapshot Migration (Check Size and Cost)
- Create a Glue Crawler and Run it to fetch data
- Use Athena to Execute Query and generate Report – Data Will be stored in CSV format in the S3 bucket location
- You can also use those output files to import data into another database.
Execution Steps –
- This process has been performed on the Beta Database of PostgreSQL Snapshot.
Step 1: Export of RDS DB Snapshot to S3 Bucket
- Take a Snapshot of the Beta Database from RDS
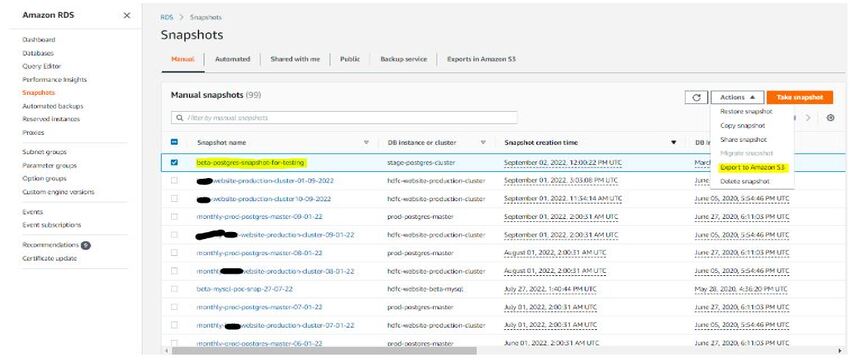
- Export Database Snapshot to S3 bucket from Snapshot Menu
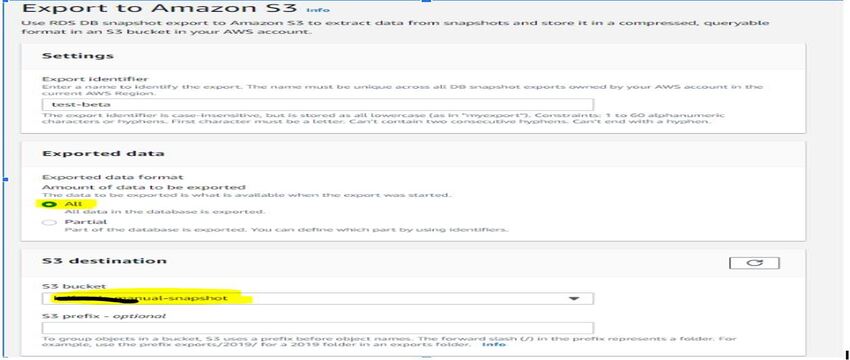
- Created KMS key as “glue-kms” in Key Management Service with default settings and copied the arn of the key created to export db snapshot configuration, and Crawler will use same to extract data by AWS Glue.
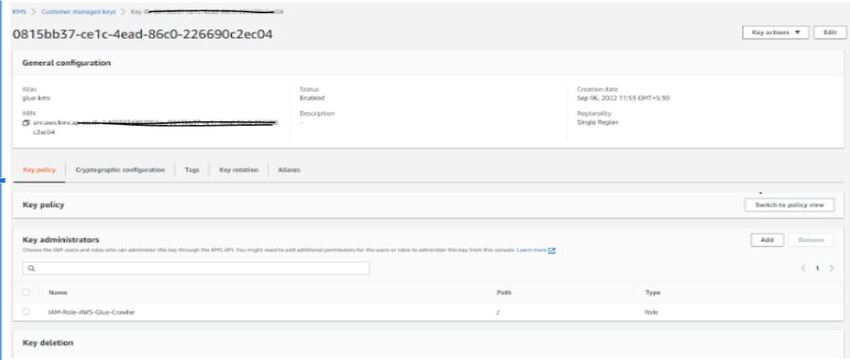
- Select S3 Bucket to upload and provide a proper IAM Role with a Newly created KMS Key to encrypt the database snapshot.
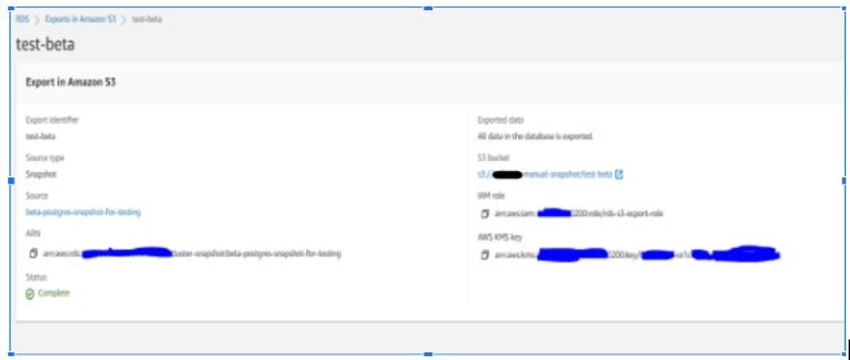
- Snapshot has been exported in the S3 bucket and checked directly from the S3 Console.
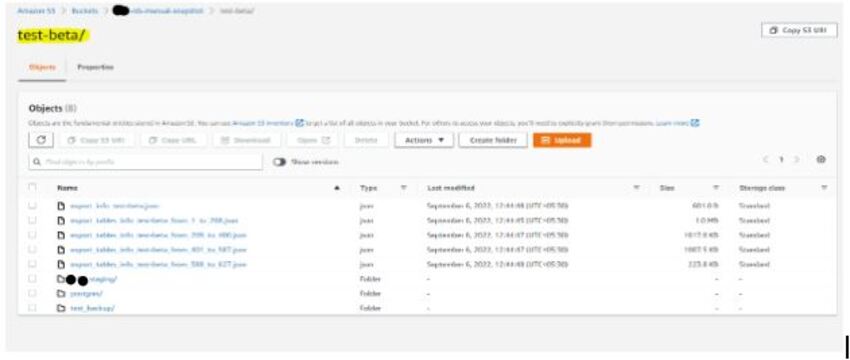
- After completion of the export task to the S3 bucket, I am able to see the databases and tables in the bucket named test-beta.
Step 2: Create and Run Crawler in AWS Glue to export S3 data in Glue Data Catalog
- In AWS Glue Console, Go to the crawler option and click on the add crawler button. Then, give the crawler name as beta-demo and click next
- Click on Next and select a data source
- Select the S3 folder and provide the path that you want to extract and get data from a particular table or full database.
- Here, we have selected a specific table customer_master to check.
- Select the IAM role which AWS Glue and Crawler will use to access Snapshot from S3 Bucket
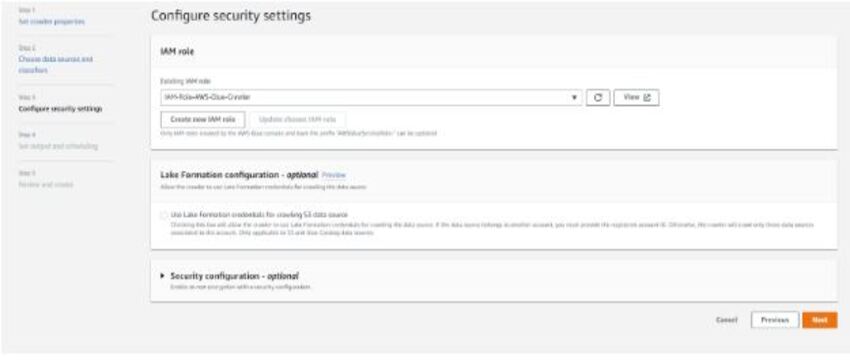
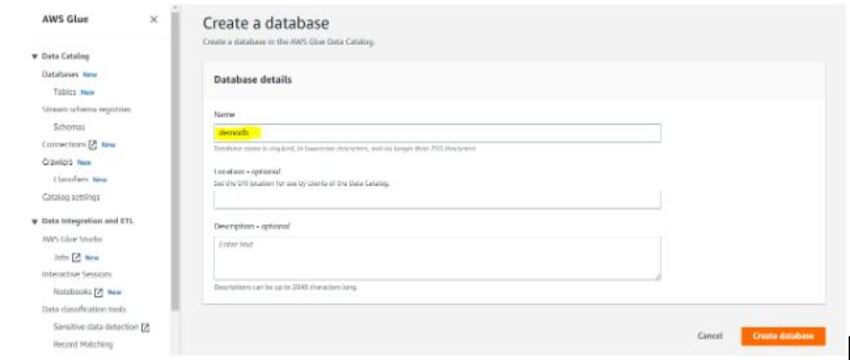
Create Database
1. Review the Created Crawler
2. Select Data Source for Crawler
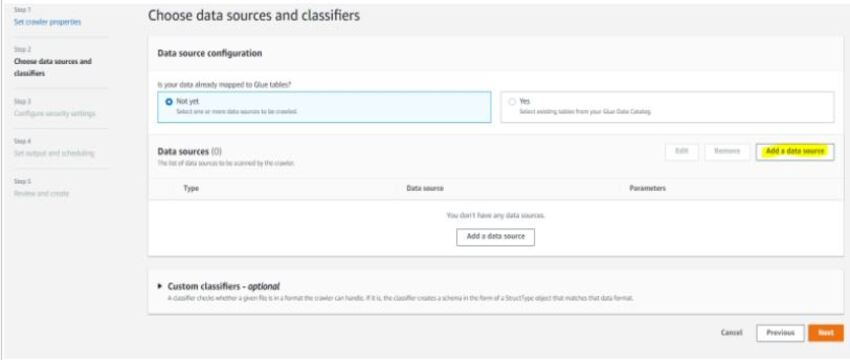
3. Create a schedule for Crawler
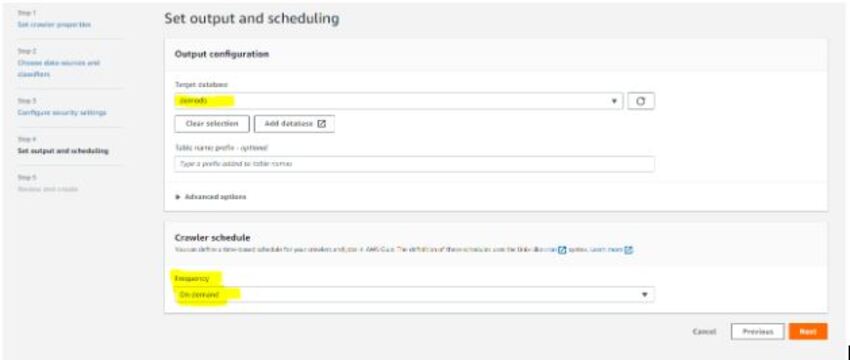
4. Run The Crawler and see the process
5. Check the Database in AWS Glue, and you will find the table that the crawler extracted from the S3 Bucket
Step 3: In Athena, run of queries and store of queries output in S3 bucket
1. Check Query Editor
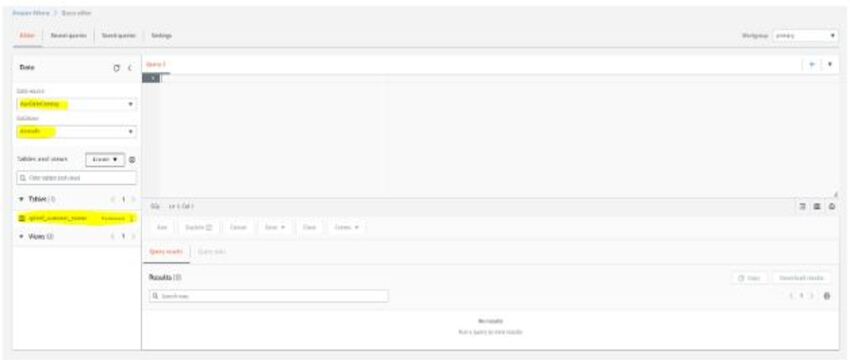
2. In Query Editor, You will find the Data Source as AWS Data Catalog, and demodb will be there as a database because it is the only database available right now.
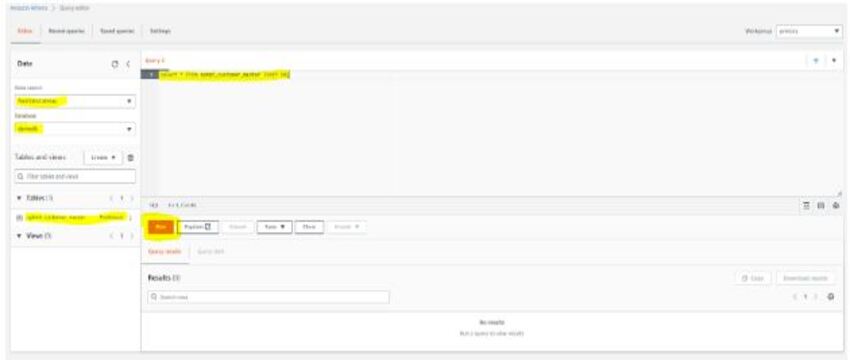
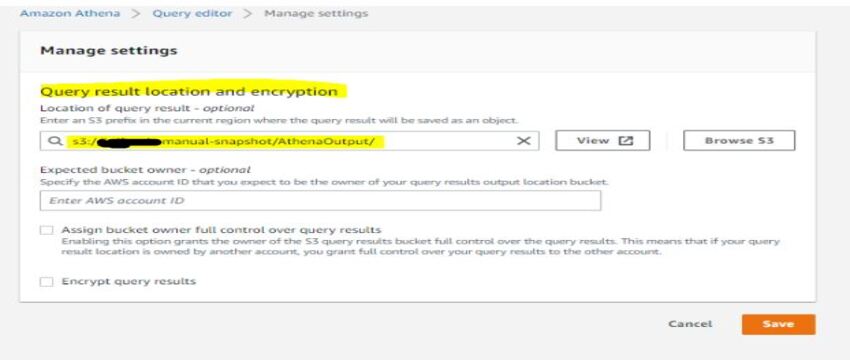
3. Go to Settings and specify the location to store output, which you will get after the execution of queries in Athena , we have provided the Same S3 bucket with a New Folder in it.
4. Execute the query and see the result.
5. Check the Output in the Query editor and the S3 bucket, where it will be saved in CSV format.
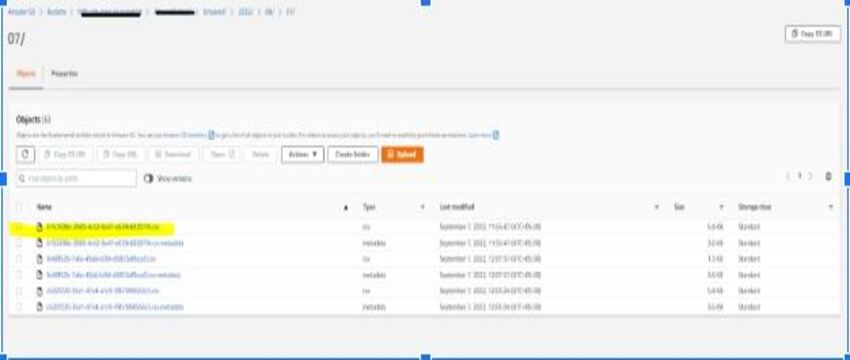
You can now download the CSV file open it, and check the result to verify.
Notes:-
- A crawler will be used if the requirement comes to get a report or data from any historical snapshot
- Costing of the crawler will be based on the minutes of usage
- Costing of Athena will be based on the data explored from snapshot
Costing Summary
Cost Estimation for the Complete Operation
| Total Size of Snapshots (TB) | 65 | ||||||
| Activity | Quantity | Rate (per quantity’s dimension) | Cost | Frequency | Trial Performed on a snapshot | ||
| KMS Key | 1 | $1.00 | $1.00 | Monthly | Size of Snapshot (TB) | 2.5 | |
| S3 Storage (GB) | 6,500 | $0.025 | $162.50 | Monthly | Size after Compression (TB) | 0.239 | |
| S3 API (number of PUT objects) | 3209205 | $0.0000153 | $48.95 | One-time | Objects created from snapshot migration | 118000 | |
| KMS Encrypt | 3209205 | $0.000003 | $9.63 | One-time | S3 API Cost | 1.8 | |
| RDS Export (per GB) | 65000 | $0.01 | $650.00 | One-time | |||
| Crawler Running Minutes | 240 | $0.0073 | $1.76 | Monthly | Assumptions Derived | ||
| Athena Data Scanned (TB) | 3 | $5.00 | $15.00 | Monthly | Compression Ratio | 10:1 | |
| Total | $888.84 | Number of Objects per GB after Compression | 494 | ||||
| API Cost per GB after compression | $0.0075 | ||||||
| API Cost per object | $0.000015 | ||||||
| NOTE: Additional KMS API charges will be applicable when Crawler and Athena will decrypt the objects | |||||||
| Additional Assumptions | |||||||
| Crawler running hours per month | 4 | ||||||
| Data Scanned by Athena per month (TB) | 3 | ||||||
| Number of KMS Keys | 1 | ||||||
Comparison Of Costing
| Operation | Old Costing | Changes | New Estimated Cost |
| Storage | 1500 USD per Month | Snapshot migrated to S3 and size will be reduced up to 8 times | 190 USD per Month |