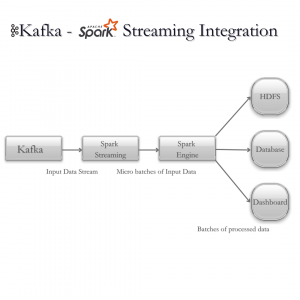
In today’s fast-paced digital landscape, businesses thrive or falter based on their ability to harness and make sense of data in real time. Apache Kafka, an open-source distributed event streaming platform, has emerged as a pivotal tool for organizations aiming to excel in the world of data-driven decision-making.In this blog post, we’ll be Implementing Apache Kafka with Spark Streaming as a powerful combination for real-time data processing and analysis. Spark Streaming enables you to process data from Kafka topics in real-time, allowing you to build complex data pipelines. Spark Streaming enables you to develop Kafka consumers capable of both real-time streaming and batch processing.
Prerequisite:
To embark on Kafka streaming with PySpark, several prerequisites must be in place. Firstly, you need to have Apache Kafka correctly installed and configured on your cluster or local environment. Apache Spark, coupled with PySpark, should also be set up and operational. It is crucial to create Kafka topics that align with your data ingestion and processing needs. Additionally, ensure that Apache ZooKeeper or the Kafka Raft protocol, depending on your Kafka version, is appropriately configured for cluster management and coordination. To complete the setup, set up a Kafka producer to publish data to the intended Kafka topics. Ensure that the necessary Kafka client libraries for PySpark are available. Configuration parameters, such as broker addresses, consumer group IDs, and topic names, should be defined in your PySpark Streaming application to connect to Kafka seamlessly. Adequate resource allocation, including CPU, memory, and cores, is essential to guarantee optimal performance. Last but not least, validate network connectivity between your PySpark Streaming application and the Kafka brokers, ensuring that firewalls and security settings permit uninterrupted communication. These prerequisites form the foundation for successfully implementing Kafka streaming with PySpark, enabling real-time data processing and analysis.
- Initialize a SparkSession:
Start by initializing a SparkSession, which serves as the entry point to Spark functionality in PySpark.

- Configure Kafka Parameters:
Define Kafka parameters such as Kafka broker addresses, consumer group ID, and the topic you want to consume from. Adjust these parameters to match your Kafka setup.

- Create a Kafka DataFrame:
In PySpark, you can create a DataFrame to represent the Kafka stream using the readStream method.

- Process the Kafka DataFrame:
You can now process the Kafka DataFrame using Spark transformations and actions. For example, to display the consumed messages:

- In this example, we cast the Kafka message value to a string and display it to the console. You can replace this with your custom processing logic based on the data you receive from Kafka.
Start the PySpark Streaming Query:
To begin streaming data from Kafka, start the PySpark Streaming query:

This starts the query, which continuously consumes data from Kafka.
Submit the PySpark Streaming Application:
Package your PySpark Streaming application, including all dependencies, and submit it to your Spark cluster or run it locally.
These steps outline the configuration process for Kafka streaming with PySpark. With this setup, your PySpark Streaming application will be capable of consuming and processing real-time data from Kafka topics using Python. Customize the processing logic in step 4 to match your specific use case and business requirements. Make sure to configure Kafka parameters to align with your Kafka cluster configuration.
Using Spark Streaming to process Batch input data:
With a slight adjustment to Spark Streaming configuration, it’s possible to utilize Spark Streaming for batch data processing as well. Some of the properties to consider include:
Trigger:
In Apache Spark Streaming, a “trigger” is a fundamental concept that defines how often a batch job should be executed. It controls when data is processed in micro-batches. Triggers are particularly relevant when working with structured streaming in Apache Spark.
Here are some key points related to triggers in Spark Streaming:
- Default Trigger: As the default behavior, Spark Streaming handles data with a “continuous” trigger, ensuring that it processes data immediately upon arrival. This configuration effectively establishes a near real-time streaming processing pipeline, making it particularly well-suited for scenarios where low latency is crucial.
- Micro-Batch Processing: Spark Streaming can alternatively be set up to process data at fixed time intervals, a method referred to as micro-batch processing. In this operational mode, data accumulates over a defined time window and is subsequently processed collectively as a batch. Regarding triggers, two distinct approaches are at your disposal: processing time and event time. Processing time triggers are contingent on the system’s internal clock, whereas event time triggers consider timestamps embedded within the data itself.
- Configuring Triggers: You can configure triggers in Spark Streaming by setting the trigger option in the query. For example, the trigger is set to process data every 10 seconds.

- Continuous Processing: For continuous processing, you can set the trigger to “continuous” or omit the trigger configuration altogether. In this mode, Spark Streaming processes data as soon as it arrives, ensuring low-latency processing.
- Micro-Batch Processing: For micro-batch processing, you can specify a fixed time interval as the trigger. Spark Streaming will collect data for that interval and then process it as a batch.
- Dynamic Triggers: Starting from Spark 3.0, you can use dynamic triggers, which allow you to dynamically adjust the processing rate based on system conditions or data characteristics. This can be useful for optimizing resource utilization and responsiveness.
- Watermarking: When dealing with event time triggers, you can also use watermarking to define the allowable lateness of events within a trigger window. This helps in handling out-of-order data.
Example for Kafka batch processing:

The choice of trigger depends on your specific use case and requirements. Continuous processing offers low latency but may result in high resource utilization, while micro-batch processing provides more control over resource allocation and processing intervals but introduces some latency. Choose the trigger that best aligns with your application’s needs.
Benefits of using Spark Streaming over Spark Batch processing
The benefits of using Spark Streaming over Spark Batch processing for Kafka Batch Input data processing are significant. Spark Streaming is designed to handle both streaming and batch data, making it a versatile choice. Its real-time capabilities allow for lower latency data processing, which is essential for scenarios requiring near real-time insights. With Spark Streaming, you can maintain a unified codebase for streaming and batch processing, simplifying development and maintenance.
Additionally, it offers dynamic adjustments for processing rates, fault tolerance mechanisms, windowing, and stateful processing capabilities, providing greater flexibility and robustness. Furthermore, Spark Streaming integrates seamlessly with various streaming sources beyond Kafka, enhancing its versatility. Overall, Spark Streaming is a powerful choice for Kafka Batch Input data processing, offering a holistic solution that combines real-time capabilities with batch processing efficiency.
Conclusion
It’s important to note that the choice between Spark Streaming and Spark batch processing depends on your specific use case and requirements. If your primary use case involves batch processing with Kafka data and you don’t need real-time capabilities, use spark. Read for batch processing might be more straightforward. Evaluate your project’s needs and constraints to determine which approach best suits your objectives.