
Kafka: The Distributed Messaging System: That’s Revolutionizing Real-Time Applications
Imagine you’re managing a busy e-commerce website. Every time a customer places an order, it triggers several events: an email confirmation, a shipping update, a payment confirmation, and much more.
From updating the inventory to sending a confirmation email and processing the payment, everything needs to happen instantly and in sync. But how do you make sure all these processes talk to each other, handle high traffic, and never fail even under pressure?
How do these different services share data, and more importantly, how do they do it in a reliable way?
Direct communication, like API calls or database queries, works in some cases, but it quickly becomes a nightmare when:
-
-
-
- Your services are distributed across different servers or regions.
- Your data is growing fast, and you need to keep things scalable.
- You want to decouple different parts of the system so that one service’s failure doesn’t bring the whole system down.
-
-
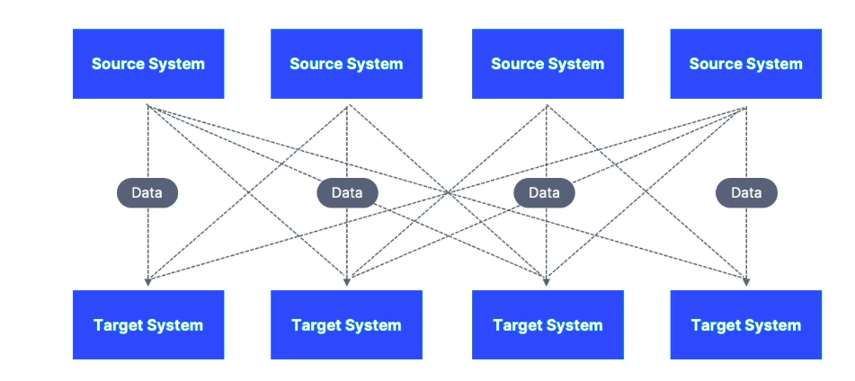
Why Messaging Systems Matter ?
In any system, especially large-scale ones, the ability to decouple different services and allow them to communicate without direct dependencies is crucial. Traditional methods like direct API calls or database queries often create bottlenecks and make scaling difficult. A messaging system, on the other hand, acts as a buffer that allows different parts of the application to talk to each other asynchronously.
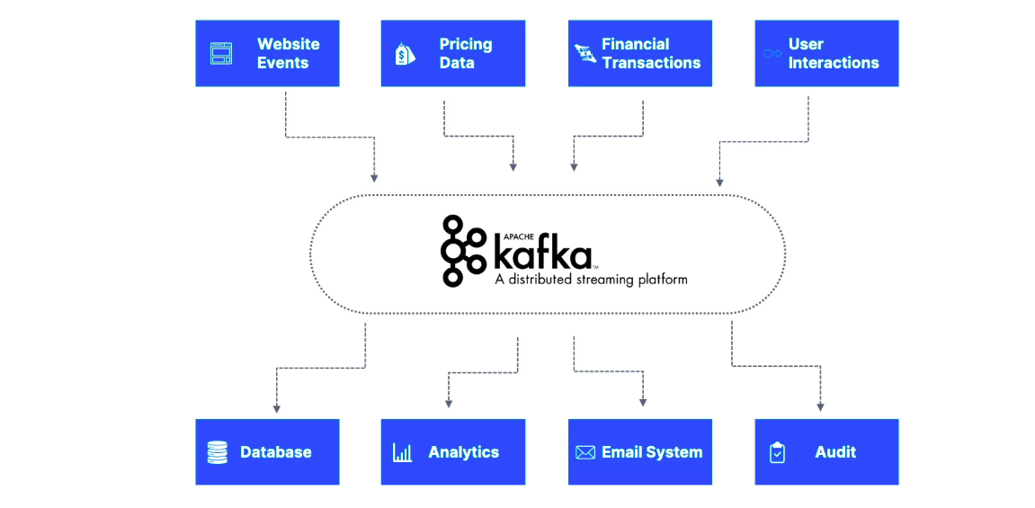
-
-
- Producer services send messages about events (like an order placed, or a payment processed).
- Consumer services pick up and react to these messages in their own time, whether it’s sending an email confirmation or updating inventory.
- This ensures that the services don’t have to wait for each other to finish tasks and can work in parallel, improving the overall performance and reliability of the system.
-
Kafka: The Distributed Messaging System That’s Revolutionizing Real-Time Applications
Okay, so we know why messaging systems are important. But what makes Kafka so special? Kafka is a distributed event streaming platform. It’s designed to handle huge volumes of real-time data. Unlike traditional messaging systems, Kafka is built to scale and is fault-tolerant, which makes it perfect for today’s big data-driven applications.
Here’s why Kafka is a game-changer:
Scalability: Kafka is designed to handle millions (yes, millions!) of events per second. So if your application needs to scale, Kafka can easily handle it.
Fault Tolerance: Kafka replicates your data across multiple servers, so even if one server goes down, your data is still safe.
Real-Time Data Processing: Kafka lets you process data as it’s generated, so applications can react immediately to events, whether that’s sending an alert or triggering another action.
Let’s Break Down the Basic Kafka Terms
Now that we know what Kafka is and why it’s useful, let’s get into some of the basic terms. I’ll keep it simple!
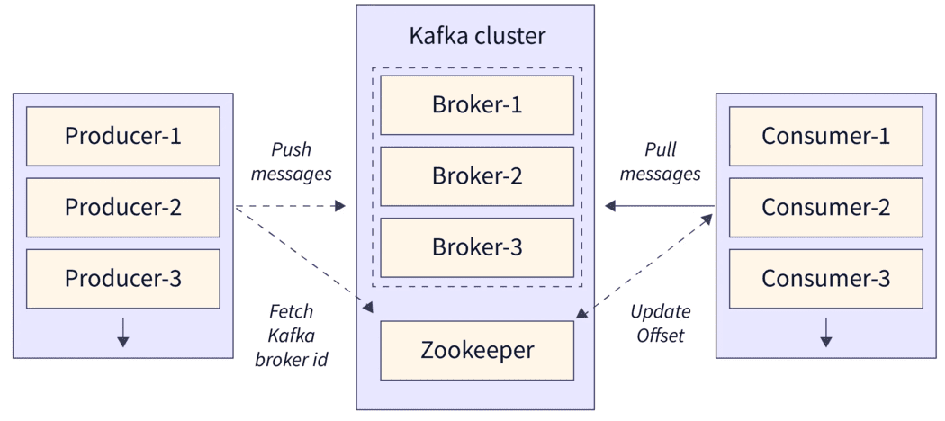
Zookeeper
-
-
- Role: Zookeeper is a distributed coordination service. It’s used to maintain and coordinate the state of a system across multiple nodes.
Functionality: In systems like Kafka, Zookeeper helps with tasks like managing metadata, handling leader election, keeping track of which broker is responsible for a partition, and more. - Cluster Management: Zookeeper ensures that all the nodes (brokers) in the cluster are aware of each other and synchronized.
- Fault Tolerance: If a node (broker) goes down, Zookeeper helps manage failover, ensuring another broker takes over the responsibilities, and the system stays consistent.
- Persistent Data Storage: Zookeeper stores small amounts of critical configuration data or metadata. It is not intended for storing large amounts of data, like messages or logs.
- Role: Zookeeper is a distributed coordination service. It’s used to maintain and coordinate the state of a system across multiple nodes.
-
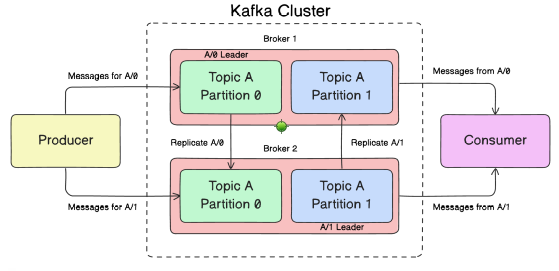
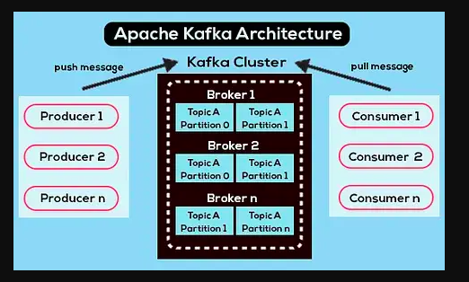
1. Brokers
In Kafka, brokers are the servers that manage and store the messages. When a producer (we’ll get to that next) sends a message, it gets stored in a broker. Kafka is usually set up with multiple brokers to ensure that if one fails, others can pick up the slack.
Think of brokers like the workers at a post office — they take the messages, store them, and make sure they’re delivered to the right place
Multiple brokers in a Kafka cluster.
Broker Leader (in Kafka)
-
-
- Role: A broker leader in Kafka refers to the single broker that is responsible for managing all read and write requests for a particular partition of a topic. Each partition has one leader broker, and other brokers replicate the data as followers.
- Functionality: The leader broker handles all reads and writes to a partition. When producers or consumers interact with Kafka, they communicate with the leader of the partition they are interested in.
- Cluster Management: The broker leader’s role is critical for data consistency. If the leader fails, a new leader is elected, usually by Zookeeper in the case of Kafka, ensuring the system remains available.
- Failover: If a leader broker goes down, Zookeeper is responsible for electing a new leader from the available followers.
-
Key Differences:
-
-
- Purpose: Zookeeper is a coordination service, while the broker leader is a component of Kafka that handles data for a specific partition.
- Scope: Zookeeper manages the overall coordination of the Kafka cluster, including leader election, while a broker leader manages the operations of a partition (writes/reads).
- Failure Recovery: Zookeeper helps in detecting failure and leader election, whereas the broker leader is a dynamic role that may change when failures occur.
In Kafka, Zookeeper manages and coordinates tasks like leader election for brokers, while a broker leader is the actual node that performs the work of handling requests for a partition.
-
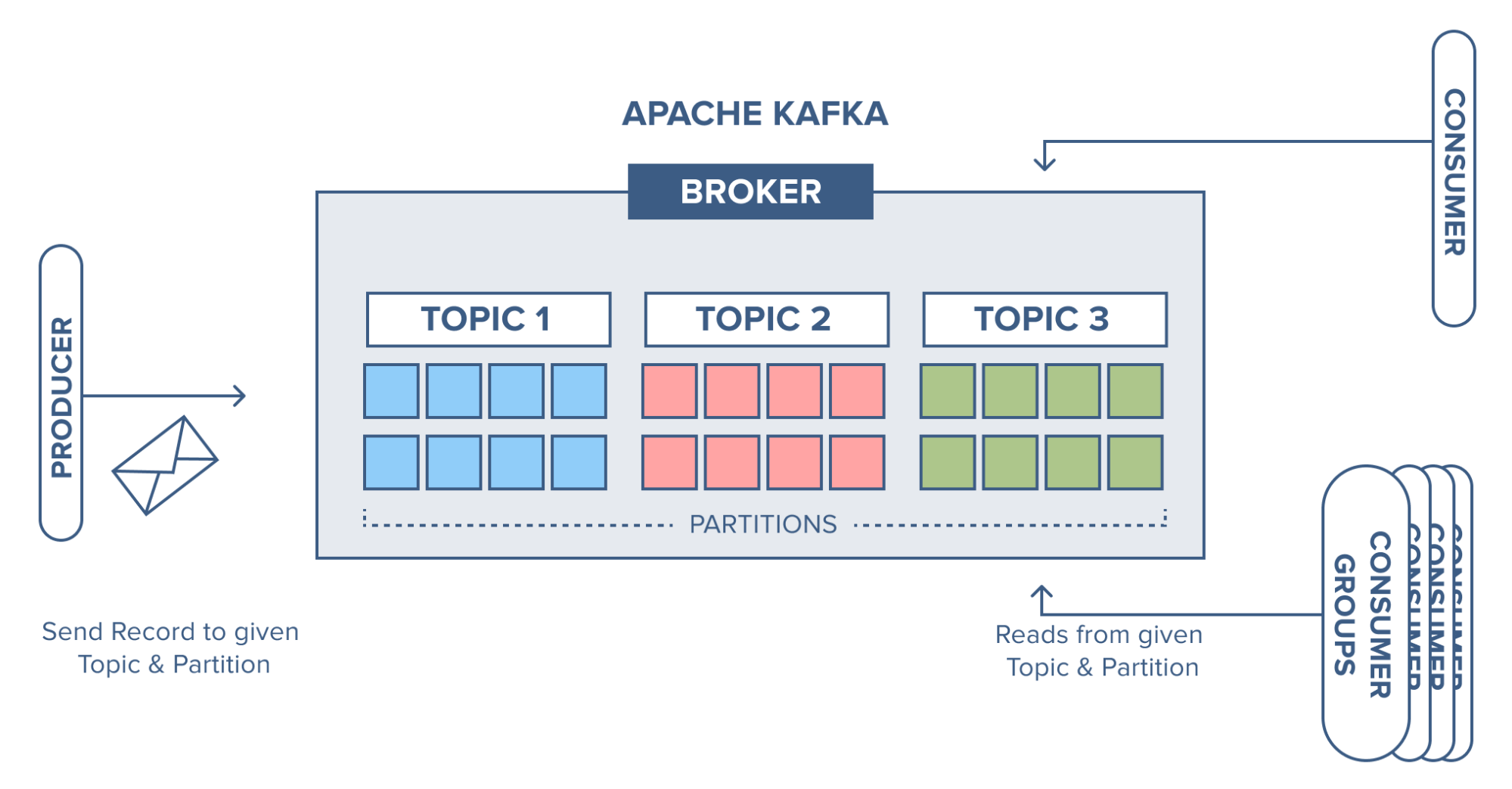
2. Topics
A topic in Kafka is like a channel or a category. Producers send messages to specific topics, and consumers (the services reading the data) subscribe to those topics. You can think of topics as the “folders” where messages get organized.
For example, if you have an e-commerce platform, you might have a topic called orders where all new orders are sent. Another topic could be payments for tracking payments.
Topic
3. Partitions
Kafka helps you scale by breaking topics into smaller partitions. Each partition is like a mini topic within the larger topic, and it can be stored on a different broker. This allows Kafka to handle tons of messages at once.
Imagine you’re running a huge social media platform. You could have millions of users posting photos or comments every second. Kafka makes sure these messages are spread across multiple partitions, so no single broker gets overwhelmed.
Partition
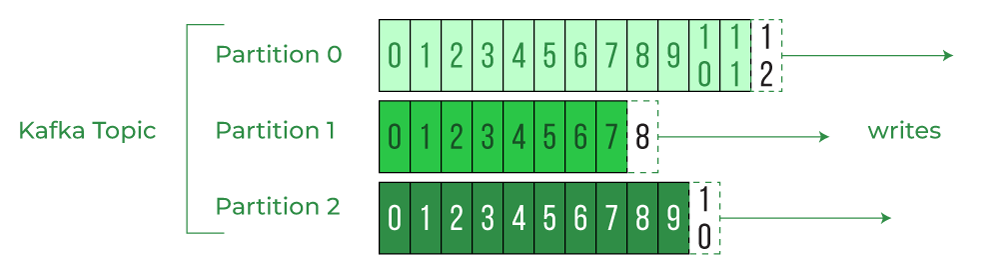
4. Offsets
Here’s where it gets interesting. Kafka keeps track of which messages consumers have already read using offsets. An offset is simply a number that represents a position in the topic’s partition.
Let’s say your consumer has read 100 messages from a partition. Kafka will remember that and assign an offset to that consumer. If the consumer crashes or stops for any reason, it can resume reading from that exact point using the offset.
offsets
5. Producers
Producers are the services or applications that send messages to Kafka. A producer might be an order service in an e-commerce platform that sends order data to the orders topic. They “produce” data that needs to be consumed by other services.
6. Consumers
Consumers are the ones that read messages from Kafka topics. In a microservices architecture, a consumer could be a service that listens for new orders in the orders topic and processes them. Kafka allows consumers to read messages in parallel, which makes it super fast and efficient.
Consumer
7. Consumer Groups
If you have multiple consumers reading from the same topic, they can join a consumer group. Each consumer in the group will get a portion of the messages, which helps balance the load and ensures that messages aren’t read multiple times. So, if you have a team of services processing orders, each service might pick up a different order message without stepping on each other’s toes.
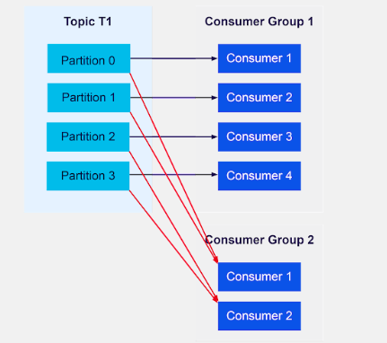
Consumer Group
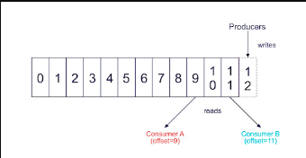
Consumer Group Offset
Kafka in Real-Life Applications
Now that we know the basics, let’s talk about why Kafka is such a big deal in the real world. Many large companies use Kafka because it allows them to process huge amounts of real-time data quickly and reliably.
For example:
-
-
- Netflix uses Kafka to process user activity and deliver personalized recommendations in real time.
- Uber uses Kafka to track trips, handle payments, and update drivers’ statuses as they move around the city.
- LinkedIn uses Kafka for logging, metrics, and even to power their real-time recommendation engine.
-
Kafka allows these systems to scale easily while keeping things running smoothly without any bottlenecks.
FINAL THOUGHTS
Kafka is a powerful tool that helps applications handle massive streams of data in real-time.
Kafka is more than just a messaging system, it’s a distributed, fault-tolerant platform that keeps your data flowing smoothly, no matter how big or complex your application gets, if you’re building scalable, data-driven apps.


