Automating PDF Filing with AI and NLP
In the ever-evolving world of data science and automation, innovative solutions have continually emerged, simplifying intricate tasks and enhancing efficiency across various industries. One such transformative application is the automation of PDF document filing, a process that has witnessed significant enhancements due to advances in artificial intelligence (AI) and natural language processing (NLP). This blog explores automated PDF filing, delving into the challenges, technologies, and strategies involved in this pioneering field.
Overview of the Problem Statement
Picture the need to automate the process of filling out insurance application forms from multiple carriers using client data stored in a database. This task entails classifying forms, extracting pertinent information, predicting the correct labels, sections, and context, and mapping them to the correct fields on the forms. This intricate and data-intensive operation demands a high degree of accuracy and efficiency. To meet this demand, integrating AI and machine learning (ML) models with a well-conceived business approach becomes imperative.
AI/ML Solution Architecture/>
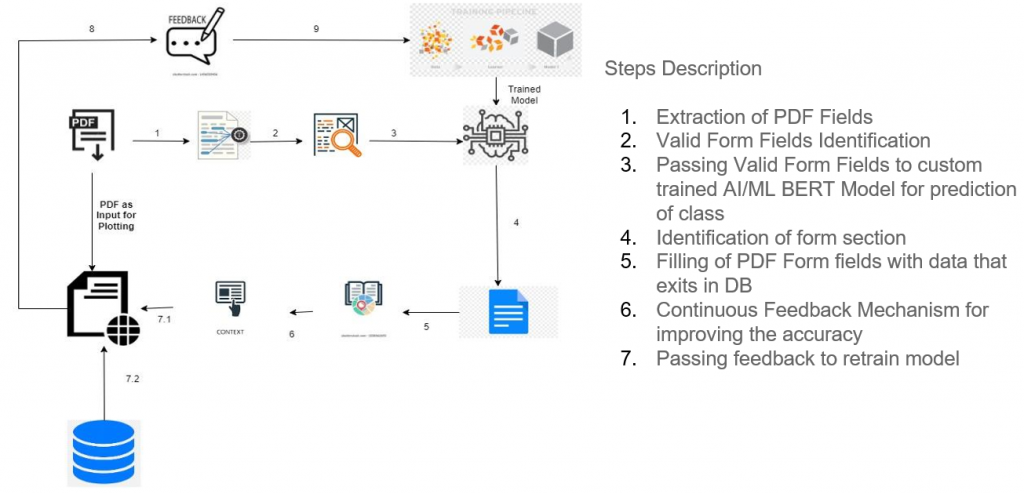
• Extraction of PDF Fields: Initially a manual process, the first step now involves extracting relevant fields from fillable PDFs. This process utilizes various Python libraries like Textract, PyMuPDF, Fitz, PDF Plumber, and pyPDF2 to create a generic, reusable solution. Further exploration aims to automate this process using Amazon Textract and Generative AI models.
• Valid form field Identification: To ensure extraction accuracy, a manual step was introduced wherein we identify relevant fields from all the fields identified, reducing the likelihood of errors.
• Integration of AI/ML Models: Relevant fields are then passed to a custom-trained AI/ML DistilBERT model to predict the correct class. For instance, a form field like the name is assigned a class First Name, Middle Name, Last Name to help Python scripts identify that in this particular form field, we need to fill in the name from the Database. BERT, or Bidirectional Encoder Representations from Transformers, is a powerful model capable of comprehending contextual relationships between words in the text.
• Identification of Form Section: Predicting the form field class alone is insufficient for populating the backend data. For example, a class like “FirstName” can belong to multiple form sections like “owner section” or “Nominee section.” This step involves mapping form fields to appropriate sections in the forms, a task with unique challenges due to identical classes in multiple form sections.
• Feedback Mechanism: Continuous improvement is paramount. The feedback mechanism allows for model refinement and retraining, ensuring adaptation to new challenges and datasets.
The Necessity of Field Extraction Automation
Although the manual approach to field extraction was accurate, it proved time-consuming and non-scalable in the long run. Automation was introduced to strike a balance between accuracy and efficiency. The automated framework, developed in Python, offers several advantages, including time efficiency, metadata extraction, and reduced manual errors. Nevertheless, challenges persist, such as noise in auto-extracted fields and occasional distortions due to text spacing in PDFs.
Challenges in CPW Label Prediction
Label prediction is a pivotal step in automated PDF filing, accompanied by challenges, including:
• Limited Training Data: Some labels have minimal training examples, posing challenges for effective model generalization.
• Similar Classes: Similar fields may bear distinct labels, confusing NLP models reliant on context.
• Imbalanced Classes: Label distribution may be uneven, impacting the model’s ability to handle various classes.
• New Classes: When encountering new carriers or forms, the model may need to predict labels for which it lacks training data.
Form Section Mapping
A refined form section approach was developed, incorporating multiple mapping rounds and prioritizing specific sections. This approach aligns with intelligent mapping strategies encompassing business scenarios. This approach relies on predicting the most possible form section from all sections’ list of available sections.
Performance of the System
Performance in the automated PDF filing system varies across carriers. Accuracy levels in class prediction and form section mapping hinge on PDF uniqueness and the quality of training data.
Future Plans
The development of the automated PDF filing system remains an ongoing process. Key activities include:
• Implementation of a feedback mechanism for model refinement.
• Continuous enhancement of context mapping.
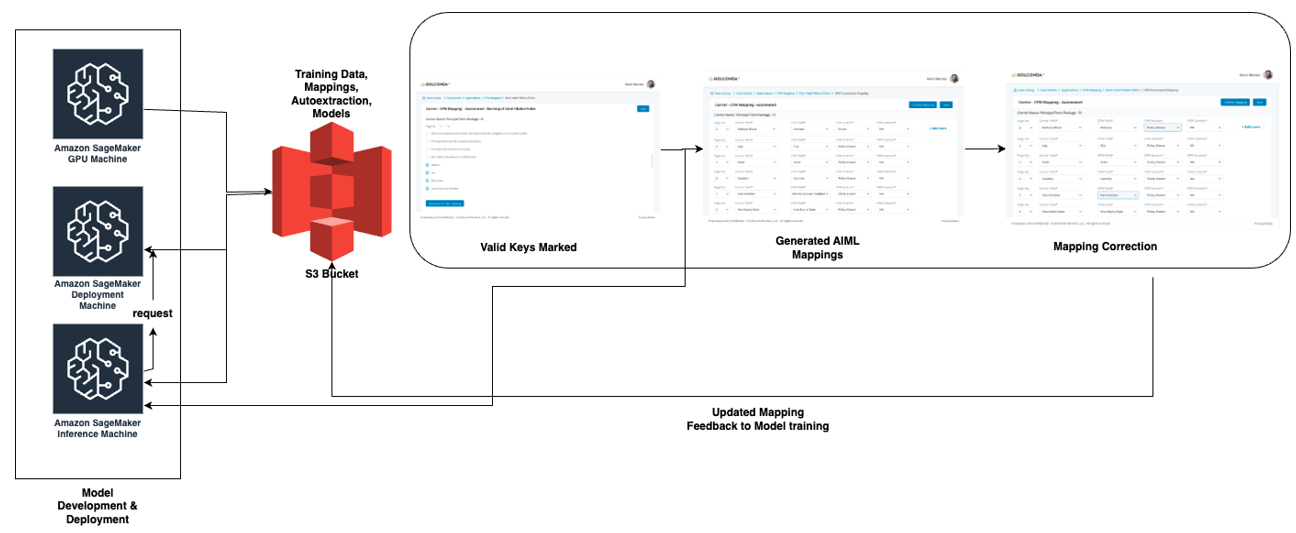
Architecture and Infrastructure
The architecture relies on AWS services, including S3 buckets for data storage, GPU training machines for model training, inference machines for predictions, and deployment machines for exposing model endpoints. The workflow encompasses data preparation, model training, deployment, and feedback loops for continuous improvement.
Conclusion
Automating PDF filing is a remarkable application of AI and NLP in streamlining complex business processes. The journey from manual field extraction and form filling to a sophisticated AI-driven system underscores technology’s power in addressing real-world challenges. As the system evolves and adapts, it promises heightened accuracy, efficiency, and scalability, benefiting organizations across industries.
Automated PDF filing represents just one facet of how AI and NLP are reshaping the future of data science. With ongoing development and innovation, the potential applications of these technologies are boundless, offering transformative solutions for businesses worldwide.
The project was initiated with an accuracy of 20%, which has significantly improved to 70-75%.