This is a blog series in continuation to a Use Case on How the team at TO THE NEW reduced monthly AWS spend from $100K to $40K in 90 days for a client. In this blog, I would explain how MongoDB consolidation and RDS optimizations have helped one of our clients to generate significant cost savings.
Earlier in our ecosystem, every application had its own 3 node replica set, and we were primarily using it for high availability. Our business requirement was to have strong consistency at the database layer, therefore we were using secondary node for replication and arbiter node for election. This type of setup helps in getting strong consistency, high availability and allows for maintenance activities without any downtime. In our case, we had more than 40+ services, resulting in 40+ MongoDB replica set and in total 120+ MongoDB servers to manage. In the initial days, DB team did some performance test on different instance types and recommended m4.xlarge instance type as a minimum required configuration (m4.xlarge instance type offer better CPU and network performance at a lower cost as compared to other generation instance types).
The challenges we had with databases and how we dealt with them:
- Increasing Cost: As discussed earlier, every service in our ecosystem had its own 3 node replica set and required 20-25+ new services to be added in our ecosystem. If we would have followed the same architecture i.e. 3 node replica set for every service we would have ended up adding 75+ instances that keep increasing as we add more services.
- Dilemma Downgrade Vs Consolidate: With the help of monitoring system, we were able to identify underutilized MongoDB EC2 instances and EBS volumes (i.e. instances with CPU utilization < 30% and memory utilization < 40% for last 30 days).
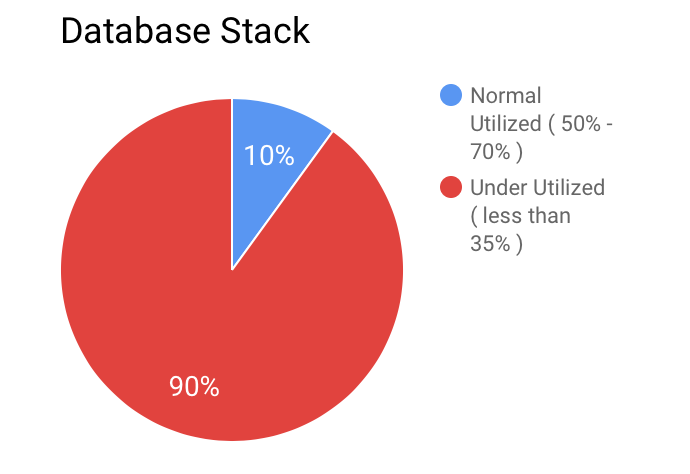 We were really surprised after seeing these astonishing stats, and we started working on cloud aggressive strategy that was to run resources at 75% utilization and add more resources on-demand. We had two options to choose from:
We were really surprised after seeing these astonishing stats, and we started working on cloud aggressive strategy that was to run resources at 75% utilization and add more resources on-demand. We had two options to choose from:
- Downgrade Under-Utilized Instances: This option seems to be the easiest, as it doesn’t involve any code level changes. We just need to stop an instance, change instance type, start the instance, and it’s done. By doing this we could reduce instance pricing but what about idle EBS volumes and bandwidth limitations that come with lower config instance types.
- Consolidate Databases: This option required good efforts, as we need to export 30+ databases, restore them on a different cluster, required downtime for data syncing. But this option will provide us significant cost savings, as we will not only reduce the number of MongoDB EC2 instances, but also EBS volumes and management overhead. After doing this activity, we were able to reduce the number of MongoDB instances from 120+ servers to 40+ servers. We categorized databases on the basis of criticality (highly critical and low critical systems) and throughput (high and low throughput systems). So we created four types of MongoDB cluster and they are:
- High Throughput Systems: We had few systems that were operating at more than 15k RPM, so we made sure no two high throughput databases reside on same MongoDB Replica Set. This cluster has 2-3 databases on three node replica set cluster.
- Internal Services: We have a couple of internal systems and those are used by internal teams and our business team can afford 10-15 minutes downtime on these systems. This cluster has 7-8 database on one three node replica set cluster.
- Critical System: We have few systems that empower our entire microservices ecosystem, or you can say they are a single source of truth and many systems rely on them. This cluster has a single database on one three node replica set cluster.
- Leaf Level Services: These are the services that don’t have very high throughput, no dependencies and our business team can afford 5-10 minutes downtime on these systems. This cluster has 5 databases on one three node replica set cluster.
- Performance Optimizations: Before starting the consolidation activity, we went through MongoDB production checklist, it provides recommendations to help you avoid issues in your production deployments. Key points to watch out for:
- Filesystem: Don’t use NFS, prefer XFS or EXT4. If you are using wiredtiger storage engine, use XFS (recommended)
- Replication: Always use Replica Set in the production environment, to mitigate node failure.
- Storage Engine: Use RAID10 and SSD drive for optimal performance, ensure dbpath is mounted on PIOPS volume for optimal performance.
- Operating System: Use noatime for dbpath mount point, tweak ulimits, kernel parameters like file handles, kernel pid limit and maximum threads per process.
- Version Upgrade: If you are on a very old version of MongoDB, upgrading to latest version could result in significant performance improvements.
In the case of RDS, we were earlier using Provisioned IOPS storage with 6000 IOPS, but after looking at Cloudwatch monitoring metrics for disk performance, we were only utilizing 40% of our provisioned IOPS. We can get 3000 IOPS by provisioning 1TB general purpose SSD storage and changing the storage type again resulted in significant cost savings. Please find below cost comparison between our earlier and current EC2 and RDS instances count:
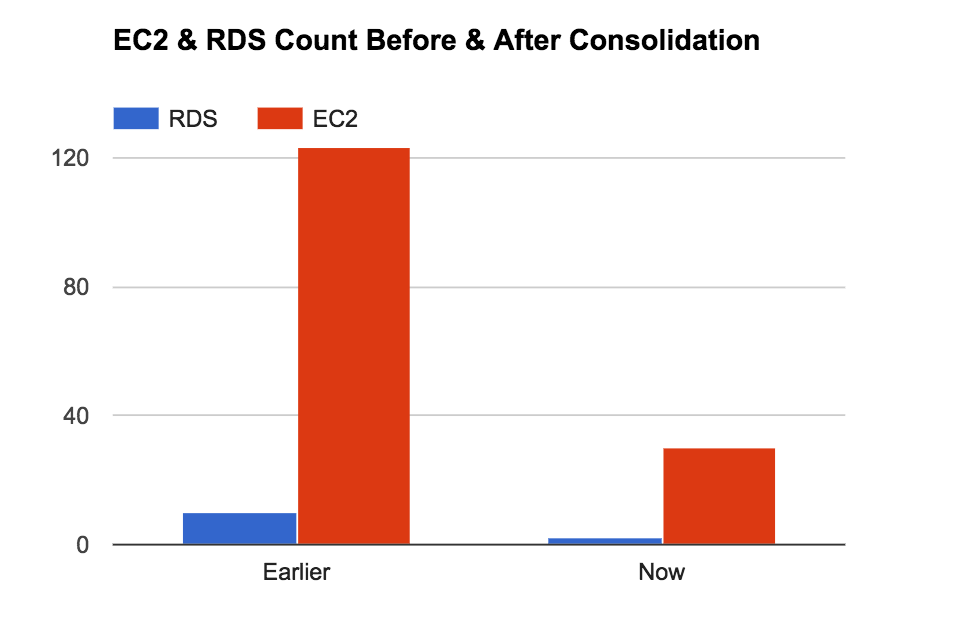
Cost Savings: At the end of this activity, we were able to save $22K per month by reducing the number of EC2 instances from 120+ to 30.
Read further our blog series on “AWS Cost Optimization Series | Blog 5 | Spot Instances for Non-Prod Environments“.