In our current setup, we are using multiple technologies but the most used ones are AWS ECS and Elasticsearch Cluster. As discussed earlier we are using AWS ECS for powering our application layer in all the environments and Elasticsearch for centralized logging and as a database for our core application.
AWS ECS uses auto scaling groups for adding/removing capacity based on multiple factors i.e. CPU reservation, CPU utilization, Memory reservation and Memory utilization. Therefore we considered AWS ECS as the good starting point for playing with spot instances as it is stateless docker orchestration tool, to better understand this blog basic understanding of spot instances is required which can be found at – Spot Getting Started (In this blog post I wanted to understand how spot instances work and challenges involved in using them in any environment, a few months back AWS has already announced spot block and spot fleet and they take care of all heavy lifting).
Note: It is not recommended to use spot instances in production (spot instances can be terminated any time), only use spot instances for stateless workloads.
A few months back AWS announced a new feature wherein AWS provides a termination notice 2 minutes before your spot instance is terminated. So, using this feature you plan your spot instance termination i.e. backup files to s3, dump log files to s3, run any script etc. So we are using a script that polls EC2 metadata service and checks for termination notice, as soon as it sees the termination notice it increases the desired count in on-demand auto scaling group (i.e. adding more capacity before terminating) and sends a notification to our DevOps team. We use below mentioned script for handling termination notice:
[js]
#!/bin/bash
while true
do
if [ -z $(curl -Is | head -1 | grep 404 | cut -d \ -f 2) ]
then
echo "Spot Instance Termination Notice"
aws sns publish –message "Spot Instance Terminating: $INSTANCE_ID $PRIVATE_IP" –topic <topic-arn> –region ap-southeast-1
bash update_ondemand_asg.sh
break
else
echo "Instance up and running"
sleep 5
fi
done
[/js]
We run the above-mentioned script on the spot instances in a loop, so that it polls every 5 seconds to check for termination notice and as soon as it encounters one update_ondemand_asg.sh script is executed, which in turn increase capacity in the on demand auto scaling group. But after a couple of days, we saw suddenly some of the spot instances started terminated frequently i.e. due to spot instance price fluctuations, so we started thinking about how to monitor these price fluctuations and get notified on high and low spot prices. To begin with, we started playing with AWS CLI and after some searching found jq to parse the spot price and send data to cloud watch.
We can get spot price history either from AWS console or use AWS CLI, below is the command that returns pricing history for r3.large instance (Linux) and stores the JSON output in spot-price-history.json
[js]
aws ec2 describe-spot-price-history –instance-types r3.large –product-descriptions "Linux/UNIX" –max-items 300 –output json > spot-price-history.json
[/js]
Using the output we got from the above command we re-generated JSON in key value format and send that to cloud watch using put-metric-data API. Once we have data available on cloud watch, we can integrate it with SNS and Lambda function to perform any task.

After combing the two commands and cloud watch put-metric-data command, we wrote a script that runs every 5 minutes and sends data to cloud watch(find screenshot below). And once we have data in cloud watch we set up the low price and high price cloud watch alarms to get notified before we lose spot instances.
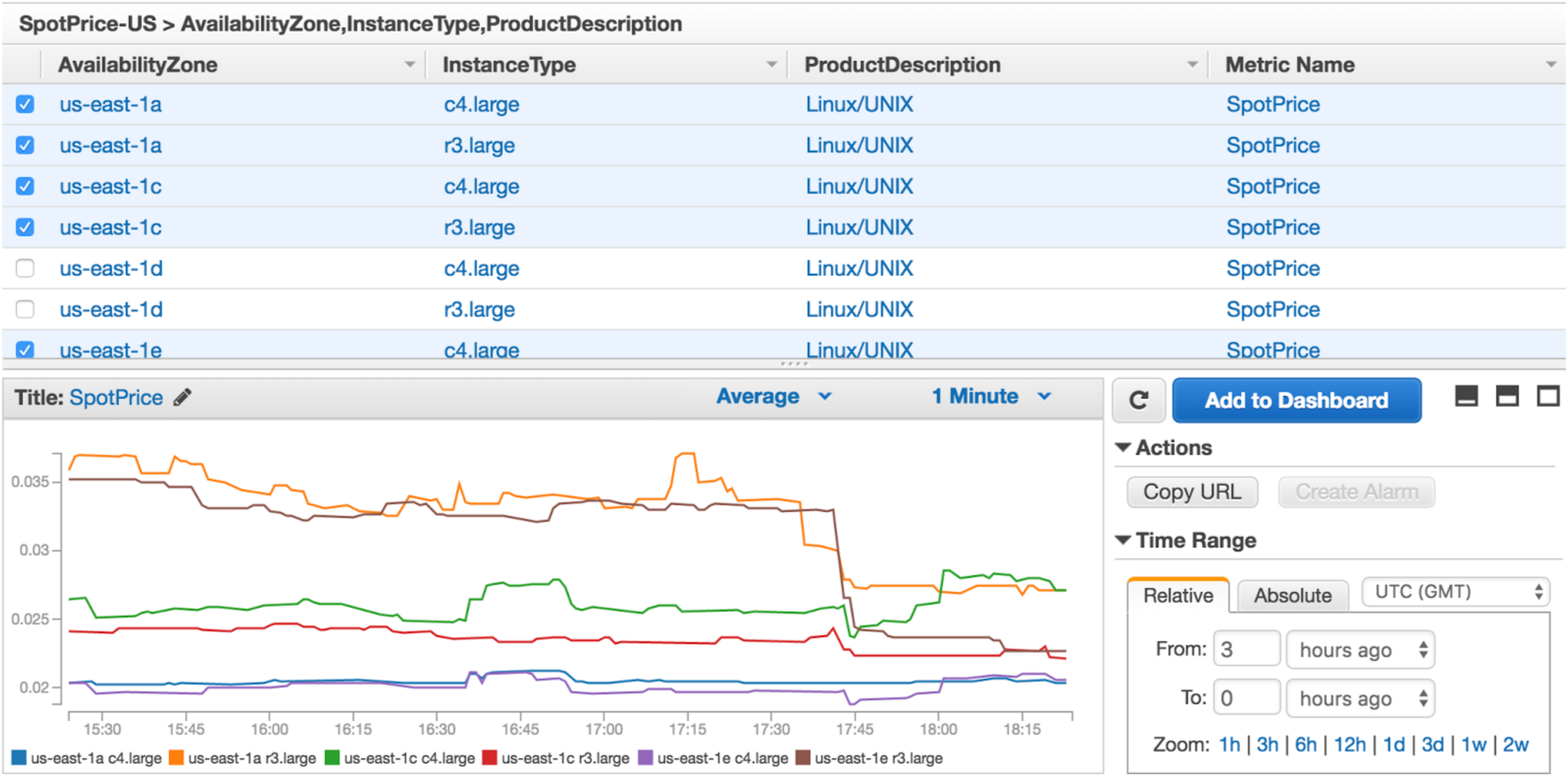
So after playing with Spot instances for few days, we started using them in QA, Staging, and Production. We are leveraging Spot instances to power our entire ECS clusters in QA and Staging environments, Elasticsearch Cluster in QA, Staging, and Production. If you want to go into detail of how to setup Highly Scalable Elasticsearch Cluster with Spot instances read this blog “Elasticsearch Cluster with Spot Instances”
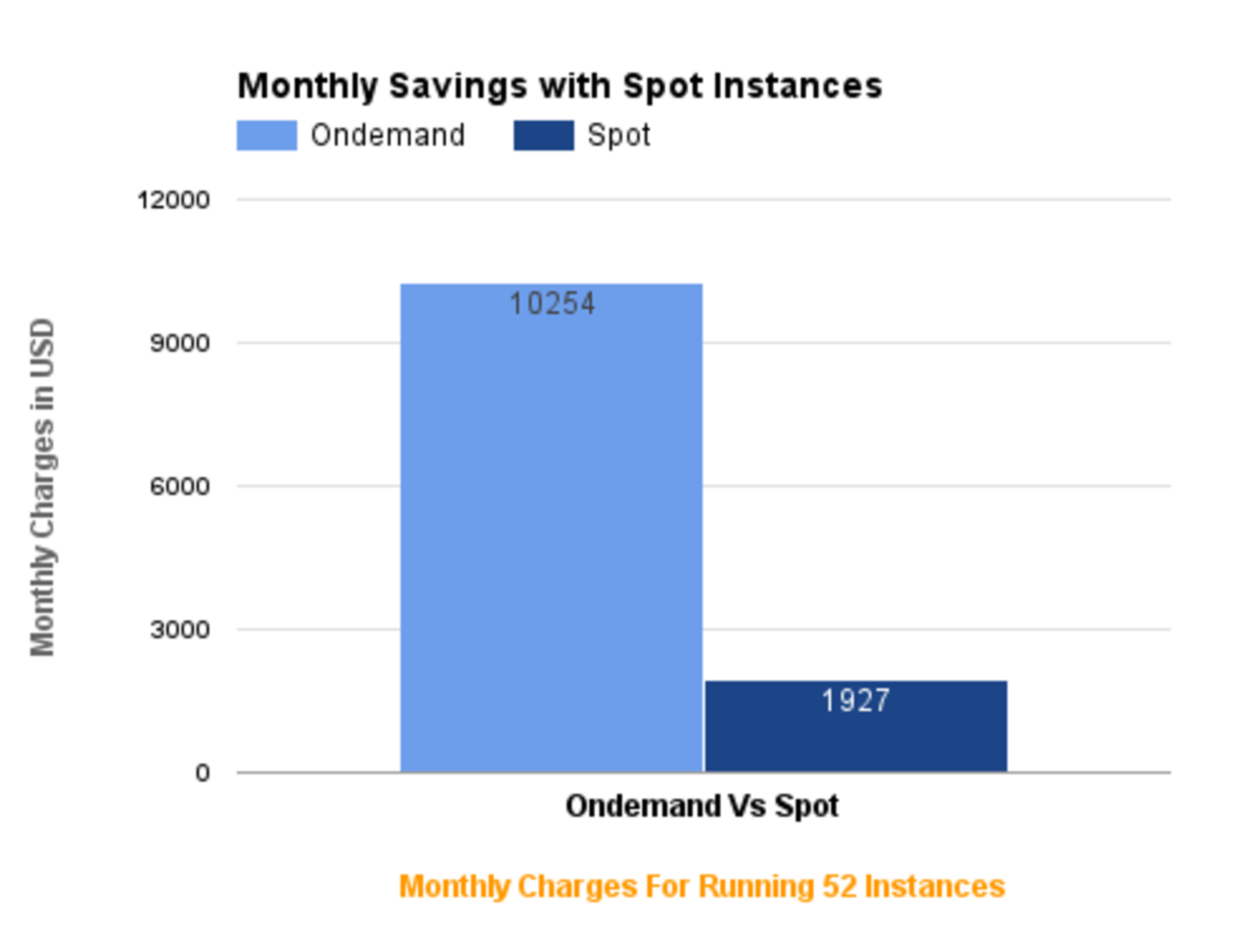
By the use of Spot Instances, we are savings roughly $15K per month and we are always exploring new workloads where we can leverage spot instances.
I hope you enjoyed this detailed blog series on this interesting case study. Below are the links to all blogs of this series.
AWS Cost Optimization Series | Blog 1 | $100K to $40K in 90 Days
AWS Cost Optimization Series | Blog 2 | Infrastructure Monitoring
AWS Cost Optimization Series | Blog 3 | Leveraging EC2 Container Service (ECS)
AWS Cost Optimization Series | Blog 4 | Databases Consolidation and Optimization