As we know Python supports multiple approaches for concurrent programming with threads, sub-processes and some other ways which could help achieving solutions built on multiple CPUs or multi-core CPU.

I tried implementing something similar on my existing use case for AWS Security Re-Check where I was running a check on AWS for my responsibilities over security. Executing that along with other similar scripts for other categories consumed a lot of time since they were running as a single process and in a sequential fashion. Also since it was a single sequential process, it was able to make use of a single core at a time. So to counter this, I tried to bring parallelism in my script. Let me tell you the two ways I tried with:
Multiprocessing
It is the usage of more than one CPU within a single machine. In Python, for multiprocessing, there is a package named multiprocessing, By multiprocessing package, a user can fully leverage the multiple processors on a machine. Process are produced by creating objects of Process class of multiprocessing package. Each process has a separate memory space so it is difficult to share objects in multiprocessing.
In my script, I had multiple functions, and I divided each function into a process and started all the processes, by this I could now run many processes concurrently which earlier used to take place in series, hence reducing the execution time. By multiprocessing, all CPUs of my machine are parallelly processing different functions of my script, also, now the total time to run that script reduced by about ~50%.
These functions were being called serially initially, like:
[sourcecode language=”python”]
def ServerHosting():
def Security_group_opened_for_all():
def Cloudtrail_Status():
def MFA_enabled():
def Access_Permissions_on_S3():
def iam_key_rotate():
[/sourcecode]
But, after multiprocessing, these were called parallelly as independent processes.
It was achieved as follows:
[sourcecode language=”python”]
from multiprocessing import Process
def runInParallel(*fns):
proc=[]
for fn in fns:
process=Process(target=fn)
process.start()
proc.append(process)
for process in proc:
process.join()
runInParallel(ServerHosting,Security_group_opened_for_all,cloudtrail_Status,MFA_enabled,Access_permissions_on_s3,iam_key_rotate)
[/sourcecode]
By creating an object and calling function start() of Process class, the process is started. join() function indicates the program to wait for the process to complete before proceeding to the main process.
Hence, all functions that have to be executed as separate processes can be run by creating a function (here runInParallel), wherein function can run as an individual independent process.
Multithreading
In multithreading, multiple lightweight processes called threads are created which share the same memory pool so precautions have to be taken, or two threads will write the same memory at the same time. In Python, for multithreading, there is an inbuilt package ‘multithreading’. By creating objects of Thread class of multithreading package, threads can be easily created.
In my script, I divided each function into a thread and started them, so now several threads were running concurrently using the same memory pool. Multithreading also utilizes all CPUs of the machine. It also reduced the execution time of the script by more than 50%.
These functions were being called serially initially,
[sourcecode language=”python”]
def ServerHosting():
def Security_group_opened_for_all():
def Cloudtrail_Status():
def MFA_enabled():
def Access_Permissions_on_S3():
def iam_key_rotate():
[/sourcecode]
But, after multithreading, these are called parallelly as independent threads.
It was achieved as follows:
[sourcecode language=”python”]
from multithreading import Thread
def runInParallel(*fns):
proc=[]
for fn in fns:
p=Thread(target=fn)
p.start()
proc.append(p)
for p in proc:
p.join() runInParallel(ServerHosting,Security_group_opened_for_all,cloudtrail_Status,func_MFA_enabled,func_access_permissions_on_s3,iam_key_rotate)[/sourcecode]
By creating an object and calling function start() of Thread class, the thread is started. join() function indicates the program to wait for the process to complete before proceeding to the main thread.
I tested executing two scripts on three different machines, and the time they consumed in executing scripts has been displayed graphically below. Taking a look at these observations, you would understand how concurrency and parallelism in Python decreases the execution time hence improving the efficiency of the script.
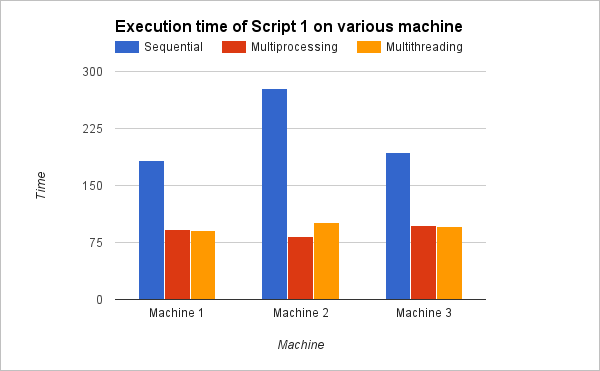
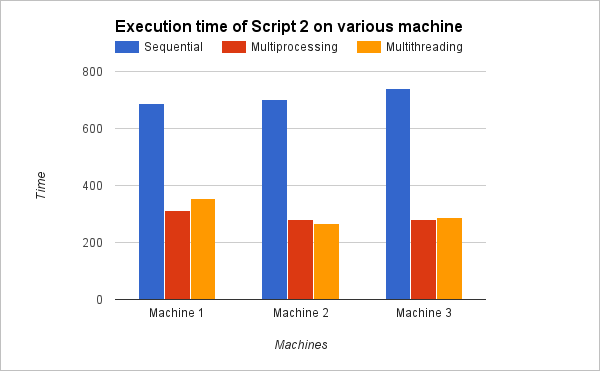
Thus, Parallelism and Concurrency not only increases the efficiency by utilizing all cores of a machine, but also by cutting off the execution time of the script.