Hashing is one of the main concepts that we are introduced to as we start off as a basic programmer. Be it ‘data structures’ or simple ‘object’ notion – hashing has a role to play everywhere.
But when it comes to Big Data – like every thing else, the hashing mechanism is also exposed to some challenges which we generally don’t think about. Though, it sounds like a trivial thing to be talked about but in reality every core idea around distributed application including partitioning, sharding etc are generally dependent upon a sophisticated hashing mechanism which is referred to as continuous hashing . Top vendors in Big Data space like Cassandra, Couchbase and many many others leverage this hashing mechanism, under the hood – to enable their products scalability and performance. Lets take a closer look to the problem and see what continuous hashing is all about.
In a distributed database running over cluster of n machines, a common way of evenly distribute data across all the node is – hash the object or key to an integer and do a modulo based on the size of the server set. For a given key, this should return the same, random server from the set every time.
[java]
server id = hash(key) % server.size
[/java]
This works great – if the server set never changes.
Where It All Goes Wrong – Now our database is doing great and getting millions of record per day so we find ourselves needing to add a new database server in order to store all the data. We added new database server, start it and soon our database returning null for most of the previous save keys. What happened? When you change the server set, the modulo value for most of the key has changed. This means that client goes to the “wrong” server for data look up. Re-distribution of large amount of data is now required to fix it. This is the case of one node addition, think when addition and removal of nodes are very frequent, system will be busy most of the time in re-distribution and hash calculation.
It would be nice if, whenever a node will be added, it took its fair share of objects from all the other nodes. Equally, when a node was removed, it would be nice if its objects were shared between the remaining nodes. This is exactly what consistent hashing does – consistently maps objects to the same cache machine, as far as is possible, at least.
Consistent Hashing – In below picture of the circle with a number of objects (1, 2, 3, 4, 5) and node (A, B) marked at the points that they hash to. To find which node an object goes in, we move clockwise round the circle until we find a node point. So in the diagram (i), we see object 4 and 5 belong in node A, object 1, 2 and 3 belongs to node B.
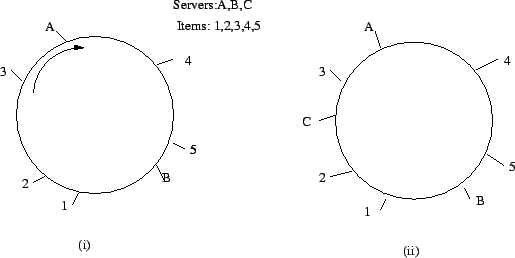
Consider what happens if node C is added in diagram (ii): object 3 now belongs in node C, and all the other object mappings are unchanged.
This works well, except the size of the intervals assigned to each node is pretty hit and miss. Since it is essentially random it is possible to have a very non-uniform distribution of objects between nodes. The solution to this problem is to introduce the idea of “virtual nodes”.
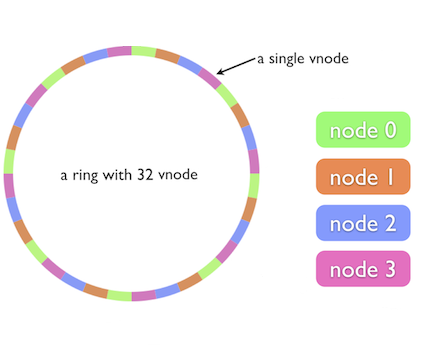
The better algorithm, uses a predefined continuum of values (virtual nodes) which map onto a node. We select N random unique integers (where N is around 100 or 200) for each server and sort those values into an array of N * server.size values. To look up the server for a key, we find the closest value >= the key hash and use the associated server. The values form a virtual circle; the key hash maps to a point on that circle and then we find the server clockwise from that point.
In this scenarios addition or removal of node required minimum data re-distribution, Still the data distribution is non-uniform. As the number of nodes increases the distribution of objects becomes more balanced.
Conclusion – Assuming we have 3 node in cluster and want to add fourth one. The continuum approach will required 1/4 or 25% of data redistribution. While The modulo approach will require 3/4 or 75% of data redistribution. The more servers you have, the worse modulo performs and the better continuum performs.