Introduction
Amazon Elastic Map Reduce is a managed platform. We can run big data frameworks like Apache Hadoop and Apache Spark on AWS to process and analyze large volumes of data.
We can process huge amounts of data for analytics purposes and business intelligence workloads with help of this framework. Amazon Elastic Map Reduce also allows us to transform and move huge amounts of data into and out of other AWS data stores and databases, such as Amazon S3 and Amazon DynamoDB.
HBase is a distributed database which runs on top of Hadoop Distributed File System and provides non-relational database potentials for the Hadoop ecosystem.
Problem Statement
Migration of Hbase running on EMR cluster from one region to another.
Solution Approach
We need to move EMR hbase tables to s3 and then import it to the newly created EMR cluster.
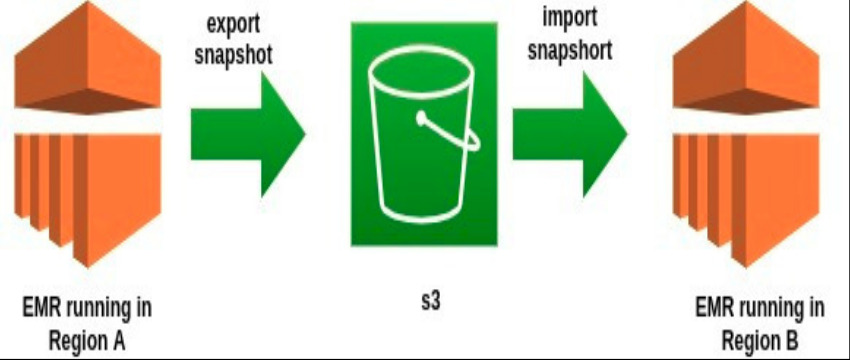
Steps by Step Procedure
These are some steps to migrate EMR cluster to another region:-
1. Create a snapshot of hbase tables from the current cluster.
a. Login to the EMR master node via ssh .
b. Login as root and switch to hbase user.
Command: su – hbase -s /bin/bash
c. Login to hbase shell
Command: hbase shell
d. Create snapshots of tables from hbase
Command: snapshot ‘tablename’, ‘snapshot-name’
2. Export the snapshots to s3 bucket
Command: hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot $snapshotname -copy-to s3://bucketname/folder/
3. Verify the snapshot in s3 bucket.
4. Now create an EMR cluster to the N.Virginia region with the same configuration as of Oregon.
Note: a. Use advanced configuration options to customize more.
b. Please verify ebs volume size from the old cluster nodes and map it accordingly.
5. After the cluster is ready please login to hbase shell with hbase user and then copy the snapshot of tables from s3 bucket .
Command: hbase snapshot export -D hbase.rootdir=s3://bucket-name/folder/ -snapshot snapshotname -copy-to hdfs://110.x.x.x:8020/user/hbase -chuser hbase -chgroup hbase -chmod 700
6. Verify the snapshot in hdfs .
a. Login to hdfs user
Command: su – hdfs
b. Check snapshot copy in hdfs.
Command: hdfs dfs -ls /user/hbase/.hbase-snapshot/
c. Verify hbase snapshot size .
Command: hdfs dfs -du -h /user/hbase/data/default/
7. Login to hbase shell
Command: hbase shell
- Restore table using snapshot
a. Disable table if any of same name
Command: disable “table-name”
b. Restore table
Command: restore_snapshot “snapshot-name”
c. Enable table
Command: enable “table-name”
- Verify the number of rows of new hbase tables and compare them with old tables.
Command: count “table-name”
Debugging
We faced the issue while importing big hbase table snapshots (size > 30 GB) from s3.
When we start copying a snapshot , it imports some gb of data then after some point the command fails and the snapshot also gets deleted from the new EMR cluster.
After debugging we got two solutions for this problem:
- Use mapper in command which import snapshot from s3
- Check volume attached to EMR nodes and increase the number of nodes if required.
Conclusion
We need some downtime in this use case as we need to copy the exact number of objects from hbase tables to be exported in s3 and the same table snapshot will be copied to the new hbase table. So, in order to avoid mismatch of count and size some downtime required.
It took 1 hour to migrate GB of data from EMR Hbase to s3.