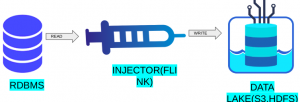
The conveyance of data from many sources to a storage medium where it may be accessed, utilized, and analyzed by an organization is known as data ingestion. Typically, the destination is a data warehouse, data mart, database, or document storage. Sources can include RDBMS such as MySQL, Oracle, and Postgres. The data ingestion layer serves as the foundation for any data engineering framework.
What is Apache Flink?
Apache Flink is a free and open-source distributed stream processing framework that may be used for real-time analytics and massive dataset processing. It was created to handle batch and stream processing cohesively, making it an excellent solution for use cases that require both. Flink accepts data from various sources, including event streams, databases, and file systems. It includes filters, maps, joins, and aggregations among its data transformation and analysis operations. One of Flink’s primary strengths is its capacity to process streaming data in real-time, which means it can manage large amounts of data with minimal delay. It also enables fault tolerance, ensuring that processing can continue even if the system fails.
How are we using Flink?
 X
X 
TO THE NEW has automated the data ingestion process using PyFlink. We wrote a Python wrapper on the top of the SQL code, which automates the process of ingestion, where the user only needs to pass the JSON file with the appropriate details that establish the connection between the source and destination so that ingestion can occur. Our framework offers various features such as reading data from RDBMS sources using PyFlink and writing it to S3, HDFS using the Flink tool, and incremental load.
Basic Features
Reading data from RDBMS sources using PyFlink and writing it to S3 , HDFS.
- Users can utilize Nimbus-Flink to ingest data from many sources into distinct destinations.
- There is no need to write any script or code.
- The user does not need to care about any complex configurations.
- Nimbus-Flink will handle the rest if users give the source and destination details in easily modifiable JSON files.
Support Options:
| Supported Sources: | Supported Destinations: |
| MySql | AWS S3 Bucket, HDFS |
| Oracle | AWS S3 Bucket, HDFS |
| Postgres | AWS S3 Bucket, HDFS |
How to use Nimbus-Flink?
Getting Started:
SETUP
Prerequisite
Java 8 or 11 (sudo apt-get install openjdk-8-jdk)
Pyflink 1.17.0
For mysql
The JDBC connector jar should be within the “lib” folder of pyflink 1.15.3 or upper version.
MySql connector jar
Mysql connector jar should also be within the “lib” folder of pyflink 1.15.3 or upper version.
This jar should be residing within the lib folder of Pyflink
Flink-sql-connector-sql-server jar
Flink-sql-connector-sql-server required in pyflink’s lib’s folder.
For Oracle
Connector :: OJDBC (This jar file should be in lib folder of PyFlink)
For Postgresql
Connector :: JDBC
Jar should be in the lib folder of pyflink :: postgres-sql-jar (( (In (lib fo
For the S3 part
s3-fs-presto jar resides within the lib folder of pyflink.
s3-fs-presto jar resides within its own named folder within the plugins folder of pyflink
NOTE: S3 bucket name should be in the region in which your account exists both(account and bucket) should be in the same region.
Mandatory Steps
Go to the cd pyflink-1.15.3/bin/conf – – – -> open conf.yaml file present in that folder.
AWS ACCESS KEY AND AWS SECRET KEY:
#S3_bucket connection details:
Fs.s3.awsaccesskey: “<Key>”
Fs.s3.awssecretkey: “<Key>”
For Hadoop:
Required jar should be in lib folder of pyflink:
Important points to consider before configuring:
- Path for hdfs hdfs://host:port/target-directory-name/.
- Target directory must be present in the hdfs.
- Target directory must have all the permissions.
- While Ingesting data to the s3 bucket, ensure that your account and s3 bucket are in the same region.
- Ingestion using a nimbus flink will work on SCD type1 model.
Configuration
Create a mysql_hdfs_config.json
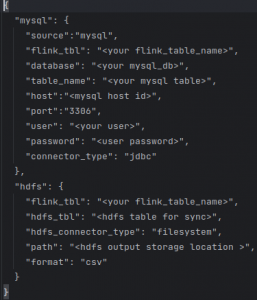
Same as for other sources and destinations, we must create a JSON file with the appropriate details.
Running Nimbus-Flink:
Python main.py <path_to_json_file>
Conclusion:
Apache Flink is a powerful real-time data processing tool that has changed how we handle data for many organizations. Its ability to perform complex computations on large data streams has enabled us to build and scale our real-time systems easily.
Nimbus-flink can perform ingestion faster, and when you are using the nimbus-flink user, do not worry about any complex coding. Users just need to write a simple json file to perform the ingestion.
If you have any further questions, you can comment on the blog. You can also refer to our open-source project: https://github.com/tothenew/nimbus-flink