
Step-by-Step Guide to Implementing RAG with Spring Boot and PostgreSQL
Introduction
Generative AI (Gen AI) has revolutionized how machines generate text, code, images, and more by leveraging deep learning models. However, one of its key limitations is its reliance on pre-trained knowledge, which may become outdated or lack domain-specific insights. This is where Retrieval-Augmented Generation(RAG) comes into play. RAG enhances Gen AI models capabilities by integrating real time retrieval mechanisms, allowing them to fetch relevant external knowledge before generating their final response. This significantly improves accuracy, reduces hallucinations, and ensures responses remain contextually relevant.
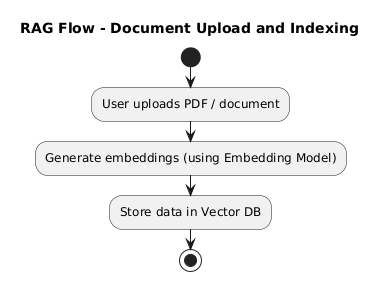
RAG Flow – Document Upload and Indexing
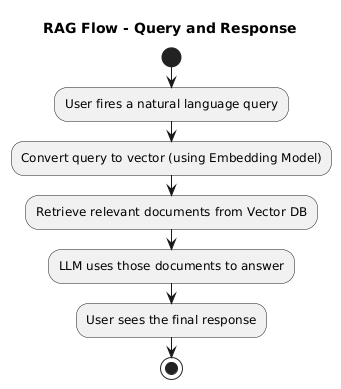
RAG Flow – Query and Response
This blog aims to demonstrate how to integrate RAG with any existing LLM based Chatbot using Spring Boot and PostgreSQL . Specifically, we will:
- Implement a RAG pipeline using a Java based Spring Boot application.
- Integrate a Vector Database, PostgreSQL, to enhance search efficiency.
- Enable Vector Search in PostgreSQL.
- Showcase the benefits of using RAG through a comparative approach.
Key Concepts around RAG
- Vector Database
To achieve RAG, we need an efficient way to store and retrieve high-dimensional representations of data. This is where Vector Databases come into the picture. A Vector database stores embeddings—numerical representations of text, images, or other data—that facilitate similarity searches. When a query is made, the database retrieves the most relevant embeddings, improving the relevance of the generated content. - Embeddings
Embeddings are dense vector representations of text, images, or videos—arrays of floating-point numbers—that capture semantic meaning and relationships in a lower-dimensional space using pre-trained language models. - Vector Search
A technique used to find similar items by comparing embeddings. - System Prompt
It is the predefined instruction or the prompt provided to the AI Model that guides its behavior and response generation. Below is one of the example we’ll be utilizing in our application.

Let’s look at implementing RAG with Spring Boot and PostgreSQL
Suppose we have an LLM based Chatbot integrated to our Campaign Management Tool to help the user for any queries and we ask the Chatbot, “How to create Campaigns based on a target segment in our Campaign Management Tool?”— while the LLM may provide a generic response about creating Marketing, Social Media, or Political Campaigns in general but would not able to explain about the steps to follow in our Campaign Management Tool to create a Campaign since the LLM Model is not aware about the steps for the same.
Initial Postman Response Image (Without RAG) Returning Generic Answer
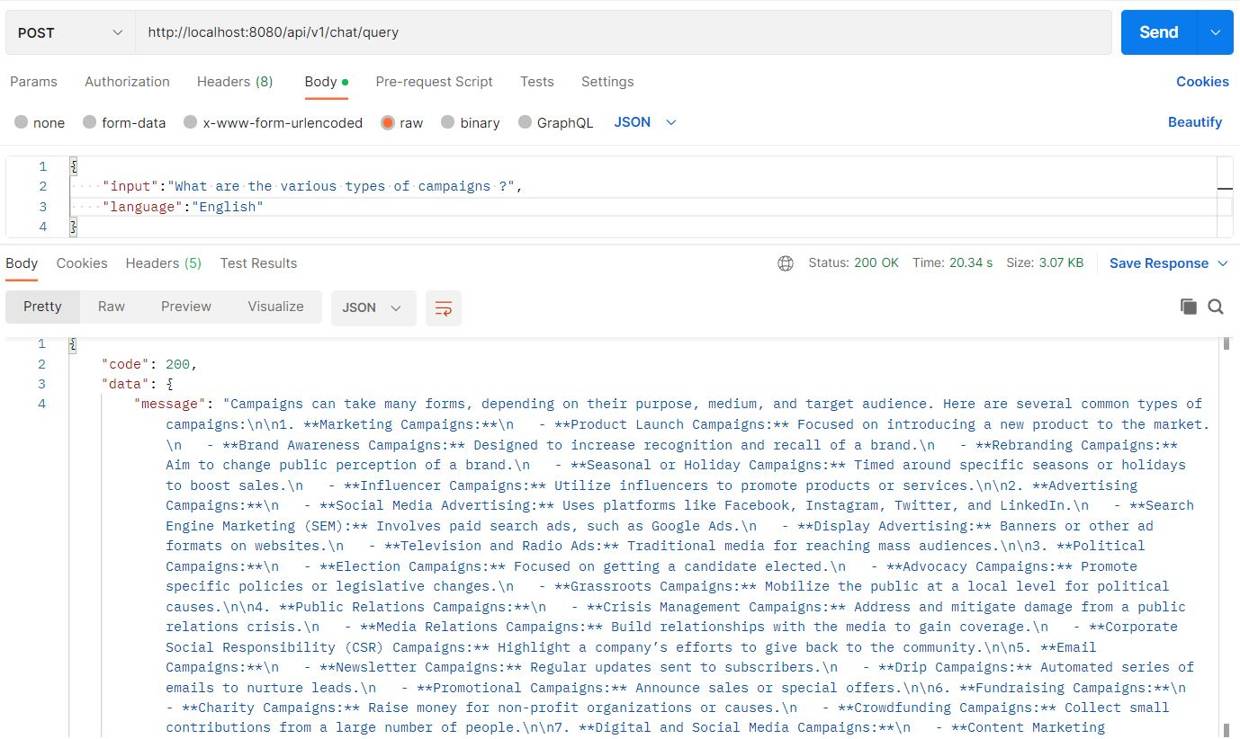
Search Without RAG
With the help of RAG, we can pass additional information to the LLM so that it is able to retrieve the correct information and provide relevant knowledge to the user.
We will build a Spring Boot application using RAG to explore its capabilities.
Prerequisites
– Open AI API key
– Postgres 13+ with the vector extension
Technology Stack
– JDK 21
– Maven
– Spring Boot 3.4.5
The application will have two key APIs, one for inserting content embeddings and another for performing semantic search on the stored embeddings, as outlined below:
- An /insert-pdf API that accepts either a file path or a multipart file in the request body. It reads the Campaign FAQs PDF, generates embeddings for each chunk, and stores them in a PostgreSQL table.
- When the /query API is invoked, the request body includes two keys: ‘language‘ and ‘input‘.
-
- language – This is the provided language by the user, for e.g. English in this case.
- Input – User Prompt provided by the user to the Chatbot
- The API converts ‘input’ into embeddings, performs a similarity search against the Vector column in the table, and retrieves the top N most relevant results—this is the Retrieval step. These results update the {pdf_extract} variable in the system context, forming the Augmentation step. The {language} variable is also updated based on the request body (optional, but useful for generating responses in the user’s preferred language).
- With both {pdf_extract} and {language} updated in the system context, we then pass ‘Input’ as the user context and call ChatClient’s(provided by Spring AI) call() method to generate a response using any underlying LLM —this is called the Generation step. This ensures that the output is a precise, contextually relevant response derived from the company’s internal knowledge base.
Now, Let’s walk through the detailed steps to build your Spring Boot application with RAG integration.
Step 1 – Enabling Vector Search in PostgreSQL
For our implementation, we are using PostgreSQL as our database and will be enabling its Vector Database capabilities by installing pgvector with PostgreSQL
You can refer to the following link for the installation guide: pgvector GitHub Repository
Add Vector Extension In Postgres Schema
- Open PgAdmin, right-click on the schema, select “Create,” and then choose “Extension.”
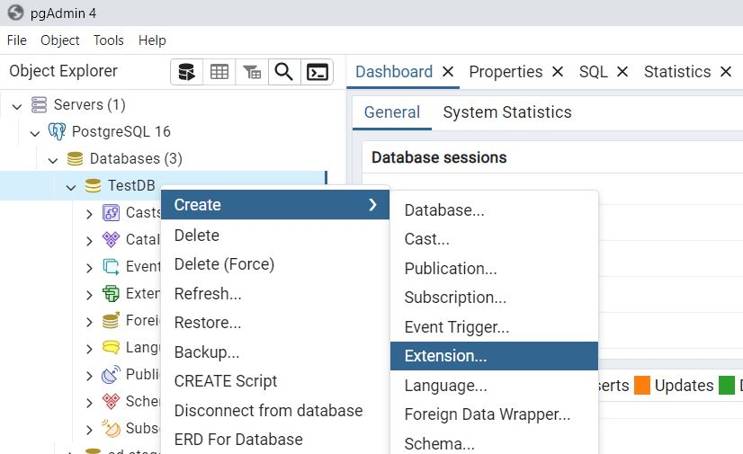
pgadmin
2. Search for the ‘Vector’ extension and add it. Once added, the ‘vector’ extension will be available in your schema, allowing you to use it as a datatype to store embeddings of your data.
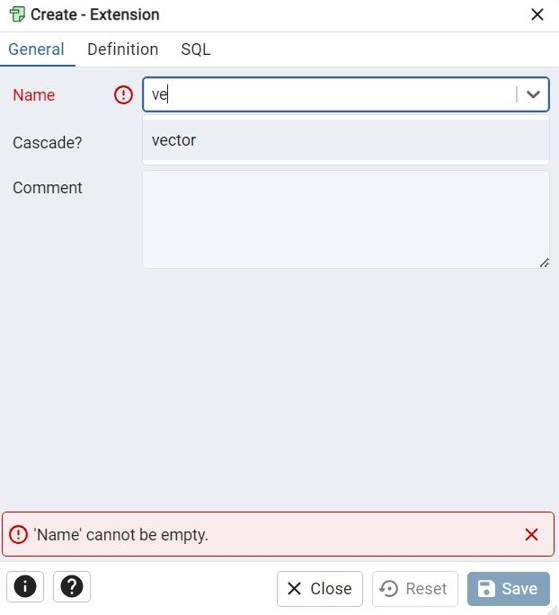
pgadmin-vector
Step 2 – Create Vector Embeddings For Our Custom Data
Consider that our steps to create a Campaign is available in the help guide. So we will create embeddings of our guide and then create vectors for the text.
We will use our Spring Boot application to insert embeddings to our Vector Database i.e. PostgreSQL.
- Let’s specify the Open AI api-key we will be using to connect to our LLM Model in the application.properties file.
spring.ai.openai.api-key=${OPENAI_KEY} spring.ai.openai.chat.model=gpt-4oHere, OPENAI_KEY is fetched from an environment variable and the LLM Model being used is GPT-4o
- Convert the Help Guide PDF paragraph chunks into embeddings using the Open AI Embedding Model.
@Autowired private EmbeddingModel embeddingModel; private void storeTextChunksInPostgres(String chunk, long sequenceNumber) throws IOException { float[] vector = embeddingModel.embed(chunk); pgVectorService.insertRecord(sequenceNumber, chunk, vector); } - Add the embeddings of each chunk into table.
public void insertRecord(Long id, String content, float[] contentEmbeddings) { List<Float> floatList = new ArrayList<>(); for (float value : contentEmbeddings) { floatList.add(value); } String contentEmbeddingsStr = floatList.toString().replace("[", "{").replace("]", "}"); jdbcClient.sql("INSERT INTO campaign_embeddings (id, content, content_embeddings) VALUES (:id, :content, :content_embeddings::double precision[])") .param("id", id) .param("content", content) .param("content_embeddings", contentEmbeddingsStr) .update(); }
This concludes the steps for converting our PDF file to vector embeddings.
Step 3 – Performing Similarity Search in our Vector Database (PostgreSQL)
Since the required data is already added to our Vector Database we can now use it for performing Similarity Search from our Spring Boot Application on the vector table. This step can also be called the R in RAG.
- A user can provide any Search prompt to the Chatbot API.
- The prompt is provided to the searchCampaignEmbeddings Method for performing the Similarity Search.
- The Open AI Embedding Model converts the user input into embeddings / vector.
- These embeddings / vectors are then further used to perform a similarity search with the vector column in the table.
- The output ranges between 0 and 1, with lower numbers indicating higher similarity.
- A threshold condition (MATCH_THRESHOLD) ensures only sufficiently similar results are included.
- The results are sorted by similarity and limited to a set number (MATCH_CNT).
- The query is executed, returning a list of matching content strings.
In summary, this method retrieves the most relevant content from the campaign_embeddings table by comparing vector representations of the input prompt and stored data.
public List<String> searchCampaignEmbeddings(String prompt) {
float[] promptEmbedding = embeddingModel.embed(prompt);
List<Float> userPromptEmbeddings = new ArrayList<>();
for (float value : promptEmbedding) {
userPromptEmbeddings.add(value);
}
JdbcClient.StatementSpec query = jdbcClient.sql(
"SELECT content " +
"FROM campaign_embeddings WHERE 1 - (content_embeddings :user_promt::vector) > :match_threshold "
+
"ORDER BY content_embeddings :user_promt::vector LIMIT :match_cnt")
.param("user_promt", userPromptEmbeddings.toString())
.param("match_threshold", MATCH_THRESHOLD)
.param("match_cnt", MATCH_CNT);
return query.query(String.class).list();
}
Step 4 – Calling the LLM Model and provide the RAG context to it.
- The top N similarity text returned from above Step 3 are passed as context in the “pdf_extract” variable in our system prompt.
- The system context is then updated by setting ‘pdf_extract’ with the similarity results and ‘language’ with the specified method parameter. This step can also be called the A in RAG.
- The Spring AI’s ChatClient object calls the LLM model (In our case it is Open AI), using the updated system context as the system prompt and the user’s input as the user prompt.
- The output will then provide an answer to the user’s query. This step is called the G in RAG.
public String searchIndex(String input, String language) throws IOException{
List<String> contextList = pgVectorService.searchCampaignEmbeddings(input);
String context=contextList.stream().collect(Collectors.joining("/n "));
return chatClient.prompt()
.system(s -> {
s.text(extKnowledgeBasePdf);
s.param("pdf_extract",context);
s.param("language",language);
})
.user(u -> {
u.text(input);
})
.call().content();
}
Final Postman Response Image Displaying Information Retrieved by LLM Using RAG
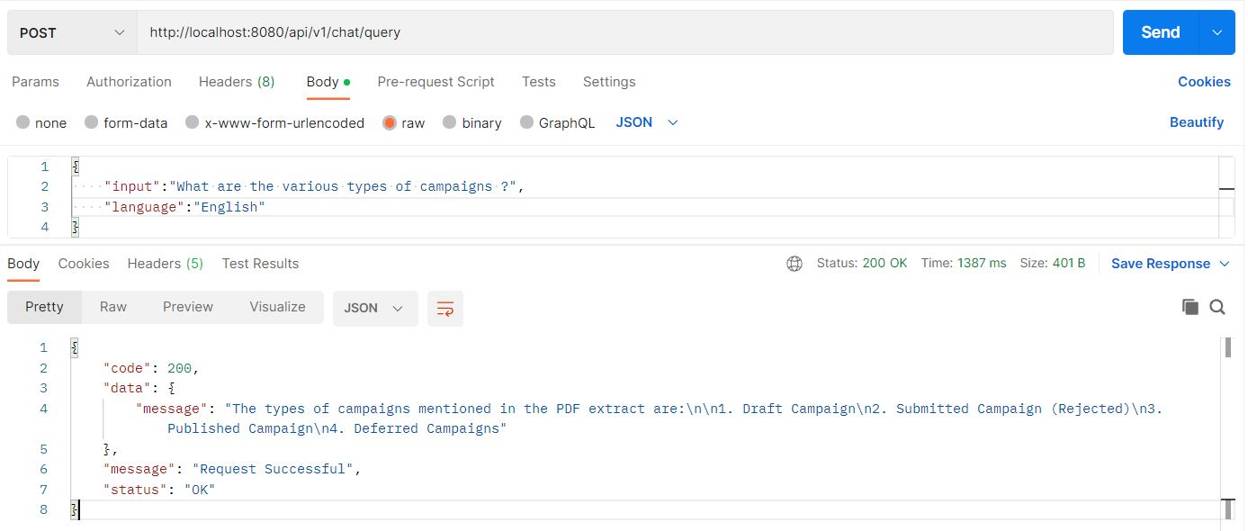
Search with RAG
Conclusion
By combining Gen AI with RAG and vector databases like PostgreSQL with pgvector, we enhance AI-generated content’s accuracy and relevance. This setup enables real-time external knowledge retrieval, reducing hallucinations and improving response quality. Whether for chatbots, search engines, or domain-specific AI, RAG bridges the gap between static and dynamic knowledge.
GitHub Repositories Reference
For a hands-on implementation of RAG using PostgreSQL as a Vector Database, check out the following repository :
- GitHub: semantic-search
