PySpark is an open-source, distributed computing framework that provides an interface for programming Apache Spark with the Python programming language, enabling the processing of large-scale data sets across clusters of computers. PySpark is often used to process and learn from voluminous event data. Apache Spark exposes DataFrames and Datasets API that enables writing very concise code, so concise that it is almost tempting to skip unit tests!
In this post, we’ll dive into writing unit tests using my favorite test framework for Python code: Pytest! Before we begin, let’s take a quick peek at unit testing.
Unit Testing
Unit testing PySpark code is crucial to ensure the correctness and robustness of your data processing pipelines. Let’s see with an example why unit testing is necessary:
Imagine you are working on a PySpark project that involves processing customer data for an e-commerce platform. Your task is to implement a transformation logic that calculates the total revenue generated by each customer. This transformation involves several complex operations, including filtering, aggregation, and joining data from multiple sources.
Why You Need Unit Testing
Data Quality Assurance: Unit tests can check the quality of the data transformations. For instance, you can write tests to ensure that the total revenue is always a positive number, or that no null values are present in the output.
Regression Detection: Over time, your codebase may evolve. You or your colleagues may make changes to the transformation logic. Unit tests act as a safety net, catching regressions or unintended side effects when code changes occur.
Edge Cases: Unit tests can cover edge cases that might not be immediately obvious. For instance, you could have tests to verify the behavior when a customer has no purchase history or when there’s a sudden increase in data volume.
Complex Business Logic: In real-world scenarios, transformation logic can become quite complex. Unit tests allow you to break down this complexity into testable components, ensuring that each part of the transformation works as intended.
Maintainability: Well-structured unit tests can serve as documentation for your code. They make it easier for new team members to understand the intended behavior of your transformations and how they fit into the larger data processing pipeline.
Cost Savings: Identifying and fixing issues early in the development cycle is more cost-effective than discovering them in a production environment, where data quality problems can have significant financial implications.
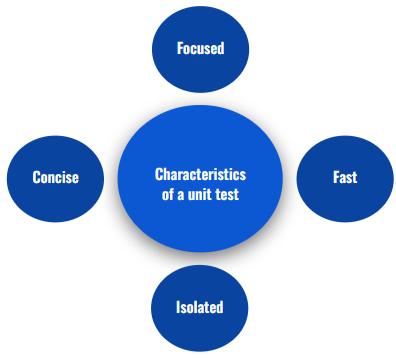
Characteristics of a unit test
-
Focused: Each test should test a single behavior/functionality.
-
Fast: The test must allow iteration and share feedback quickly.
-
Isolated: Each test should be responsible for testing a specific functionality and must not depend on external factors in order to run successfully.
-
Concise: Creating a test shouldn’t include lots of boilerplate code to mock/create complex objects in order for the test to run.
Pytest
Pytest is an open-source testing framework for Python that simplifies and enhances the process of writing and running tests, making it easier to ensure the quality and correctness of Python code. When it comes to writing unit tests for PySpark pipelines, writing focused, fast, isolated, and concise tests can be challenging.
Some of the standout features of Pytest:
- Writing tests in Pytest is less verbose
- Provides great support for fixtures (including reusable fixtures with parameterization)
- Has great debugging support with contexts
- Makes parallel/distributed running of tests easy
- Has well-thought-out command-line options
Spark supports a local mode that creates a cluster on your box that makes it easy to unit tests. To run Spark in local mode, you typically need to set up a SparkSession in your test script and configure it to run in local mode.
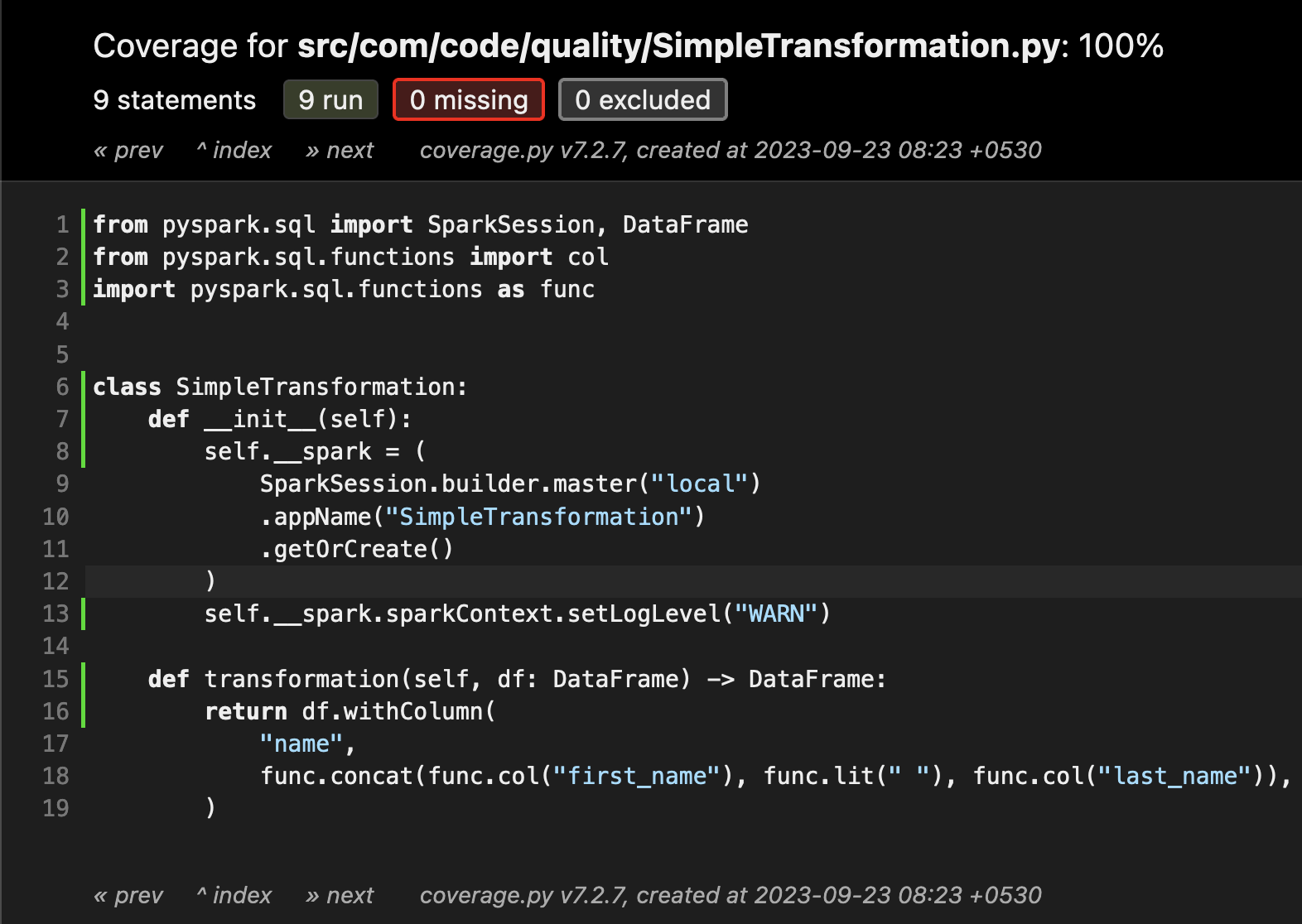
Let’s start by writing a unit test for the following simple transformation function!
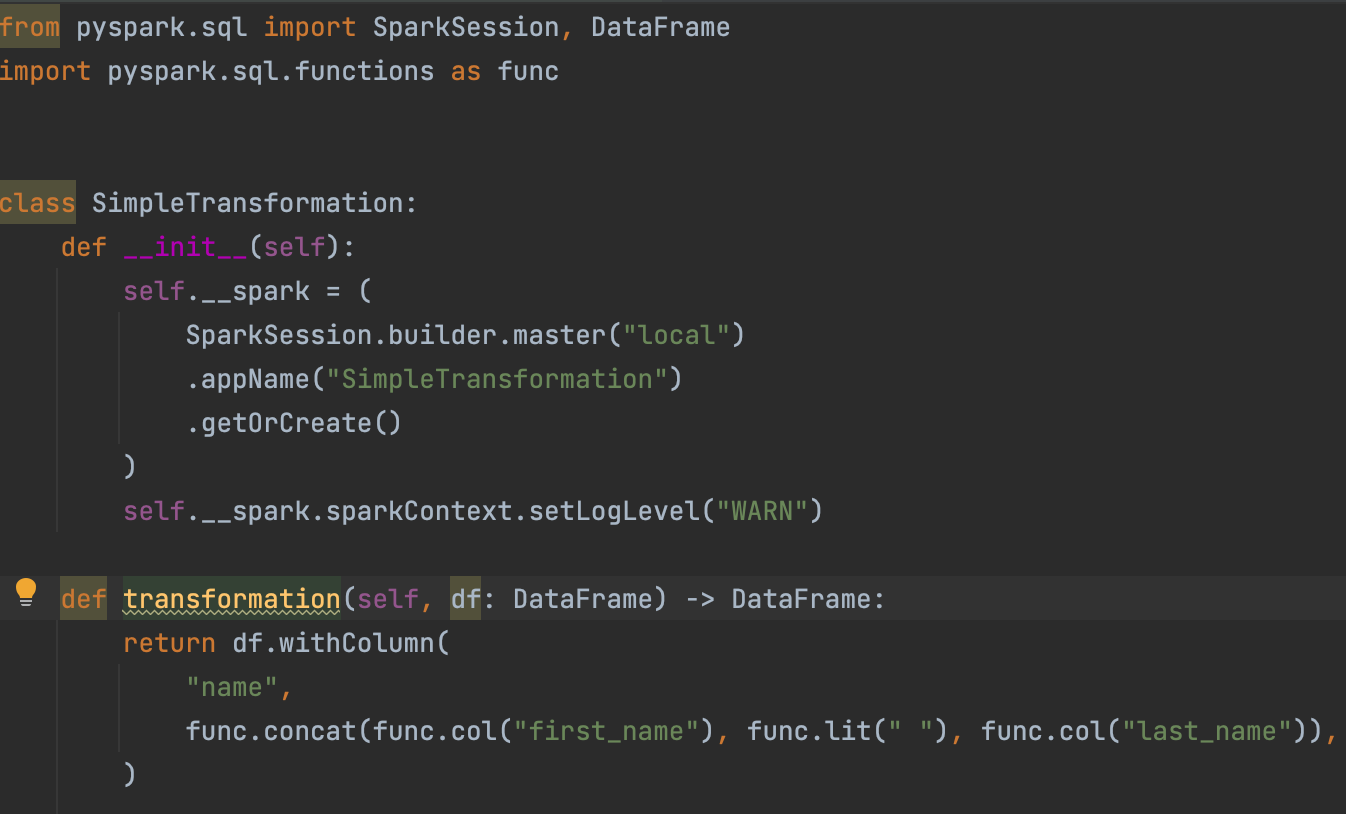
To test this function, we need a spark_session fixture. A test fixture is a fixed state of a set of objects that can be used as a consistent baseline for running tests. We’ll create a local mode SparkContext and decorate it with a Pytest fixture:

Creating a Spark Session (even in local mode) takes time, so we want to reuse it. The scope=session argument does exactly that, allowing reusing the context for all tests in the session. One can also set the scope=module to get a fresh context for tests in a module.
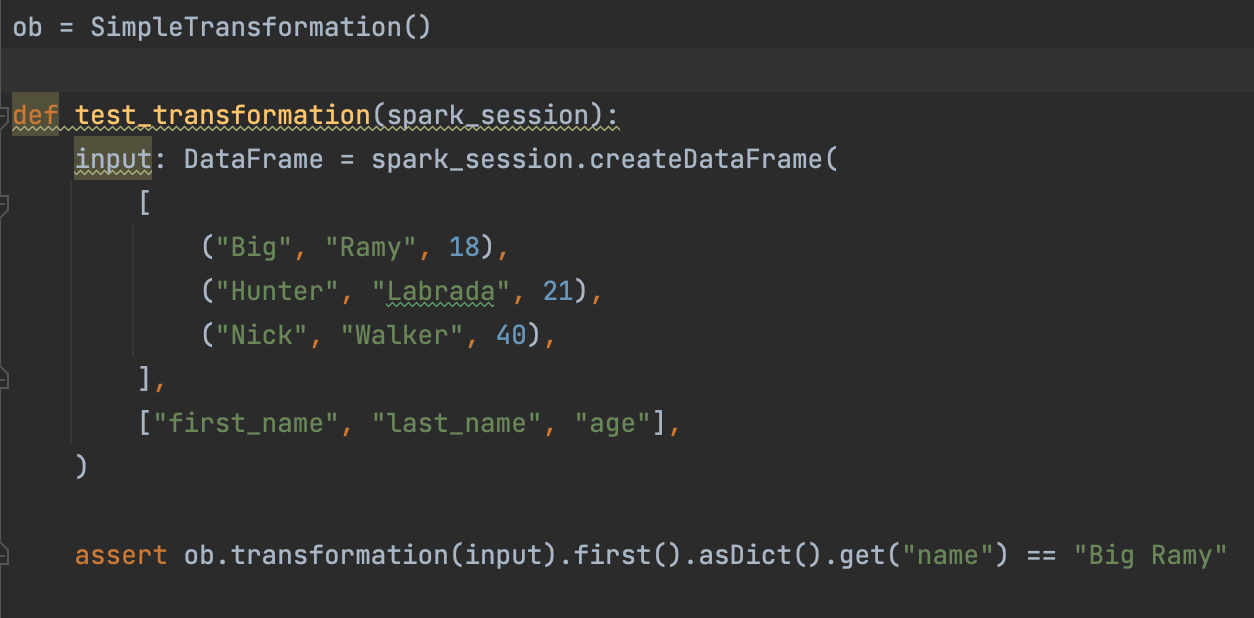
Now, the Spark Session can be used to write a unit test for the transformation function:
Code CoverageWe can run the test using the following command, and it will generate the coverage report in the mentioned directory:
python3 -m pytest –cov –cov-report=html:coverage_re tests/com/code/quality/test_simple_transformation.py