Reading text from pdf using OCR Technique (Python)
Why OCR (Optical Character Recognition)?
We can also use the PyPDF2 python library to get text from PDF. But there is a major problem with this library.
– It will not give you a good result if the data in the pdf is not structured.
– You can lose some data.
To overcome this problem, we’ll be using OCR Technique.
Which reads text from images using machine learning algorithms and it give much better result as compared to the PyPDF2 library.
So, OCR (Optical Character Recognition) is a technology that lets computers read text from images. It’s like teaching a computer to understand words in pictures. This helps convert paper documents into digital files and makes searching for text in images possible.
Requirements:
– Tesserct Engine (https://tesseract-ocr.github.io/tessdoc/Installation.html)
– Pdf2image (pip install pdf2image)
– Pytesseract (pip install pytesseract)
– Pillow (pip install Pillow)
– Python version should be 3.6 or later
Practical implementation:
Extracting Text from PDF:
1. First, we need to convert the pages of the pdf to images.
2. Then we will extract text from the images.
So, Here is the practical part.
Make sure you have installed all the dependencies which I have mentioned in the requirements section.
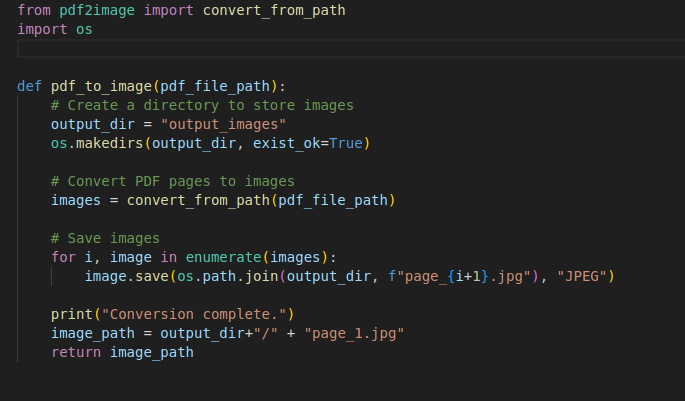
Now, I got the images of the pdf file by executing the above function. We can extract text from the pdf using pytesserect library.
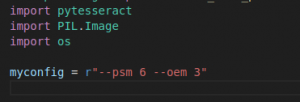
So, there are some configurations which we can use to get a better result from the Image.
The –psm and –oem are configuration options that can be used when using the Tesseract OCR engine through the pytesseract library. These options help customize the behavior of the OCR engine to suit better the specific OCR task you are performing.
Let’s break down each configuration:
–psm (Page Segmentation Mode):
The Page Segmentation Mode (–psm) option defines how Tesseract should interpret the layout of the text on the image. It tells Tesseract how to identify individual characters, words, lines, and blocks of text. Here are some common –psm values:
0 – Orientation and script detection (OSD) only.
1 – Automatic page segmentation with OSD.
2 – Automatic page segmentation, but no OSD, or OCR. (not implemented)
3 – Fully automatic page segmentation, but no OSD. (Default)
4 – Assume a single column of text of variable sizes.
5 – Assume a single uniform block of vertically aligned text.
6 – Assume a single uniform block of text.
7 – Treat the image as a single text line.
8 – Treat the image as a single word.
9 – Treat the image as a single word in a circle.
10 – Treat the image as a single character.
11 – Sparse text. Find as much text as possible in no particular order.
12 – Sparse text with OSD.
13 – Raw line. Treat the image as a single text line, bypassing hacks that are Tesseract-specific.
–oem (OCR Engine Mode):
The OCR Engine Mode (–oem) option defines which OCR engine to use and how it should process the image. Tesseract has several OCR engine modes with varying levels of complexity and accuracy. Here are –oem values:
OCR Engine modes.
0 – TESSERACT_ONLY Tesseract Legacy only.
1 – LSTM_ONLY LSTM only.
2 – TESSERACT_LSTM_COMBINED LSTM + Legacy.
3 – DEFAULT Default, based on what is available. (DEFAULT)
So, above, I have mentioned multiple config values for both –psm and –oem. You have to use config according to your image complexity.
In my case, I am using –psm 6 (Assume a single uniform block of text.)
And –oem 3 (Default, based on what is available.)
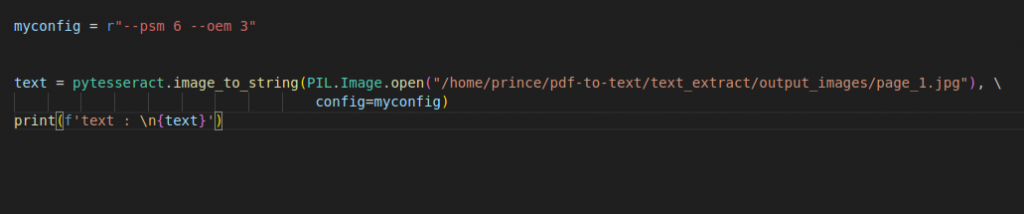
Input Image Of PDF:

Output:
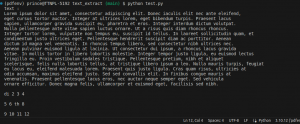
So, you may need to further process the data according to your needs.
NOTE: You will not get 100% accurate results.
Extract Text from different images:
I am using the signboard images:

Output:
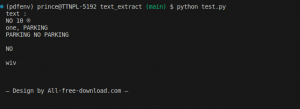
Note: For images like having sign boards, and advertisement boards, you can use a combination of OpenCV and Tesseract to get a better result.
Resources:
https://pypi.org/project/pytesseract/
https://nanonets.com/blog/ocr-with-tesseract/
Youtube Videos
Explore our blogs for an in-depth understanding of various trending topics.