Neo4J is a NoSQL database that stores information in the form of a huge property graphs where tuples/rows (nodes) are connected to each other with relationships (edges) both of which can have variable number of properties associated with them. Traversing data in the form of graphs implies that we can explore highly connected neighbouring data more efficiently and faster while leaving the data outside our search perimeter untouched. With just a starting point and a pattern to search, neo4j can execute complex queries without the overhead of evaluating relationships.
To make this a bit more comprehensive, first let’s jot down the primary differences and correspondences between a relational database and Neo4J.
- Tables vs Labels :- In RDBMS tables are responsible for storing data or rows with similar properties, for eg, in a sample database all users will be stored in a single table ‘USER’ and so on. Contrary to this neo4j provides with a property called :label which are assigned to each node(row) that defines the type of the node, i.e, all nodes with user specific data will be assigned a :label ‘USER’. Also a node can be assigned more than one :label and yes it means what you are thinking, speaking in rdbms terms ‘A row can be a part of two tables’, may help in reducing complexity.
for eg :-

- Rows vs Nodes :- Unlike relational databases which store records (tuples/rows) of same type(entity) in large tables, neo4j stores them (tuple/rows) in the form of nodes that are then assigned a type by providing them with one or more labels. This precisely means that nodes corresponds to tuples/rows in a relational db and node-label corresponds to the table name in a relational database.
- Columns vs Properties :- RDBMS uses columns to store information for a tuple whereas Neo4j uses properties that are assigned to nodes. Being a nosql database neo4j can have variable number of properties
- Joins vs Edges(Relationships) :- RDBMS evaluate relationships between multiple tables with the help of joins which are calculated at runtime and thus has to go through huge dataset every time irrespective of the data returned by the join operation. Contrary to this we can say that neo4j stores each and every join that can exist between each and every row(node) at the time of node creation itself. Its documentation states that relationships are first class citizens in neo4j, i.e, all relationships are persisted in neo4j and is only traversed at the time of retrieval, hence providing constant time of access and allows you to quickly traverse millions of connections per second per core.
- SQL vs CQL :- Structured query language(SQL) provides a declrative and easy way to query for data but it is not effecient in quering highly connected datasets that needs multiple joins where as Cypher query Language (CQL) uses symentic queries to select, insert, update, delete data from our graph data. Contrary to SQL where we need to define what to get and how to get it, CQL only wants us to define what to get leaving how to get on the graph engine itself. It uses a pattern matching approach to define the queries.
Combining all of the above here is a single visual from Neo4j website itself
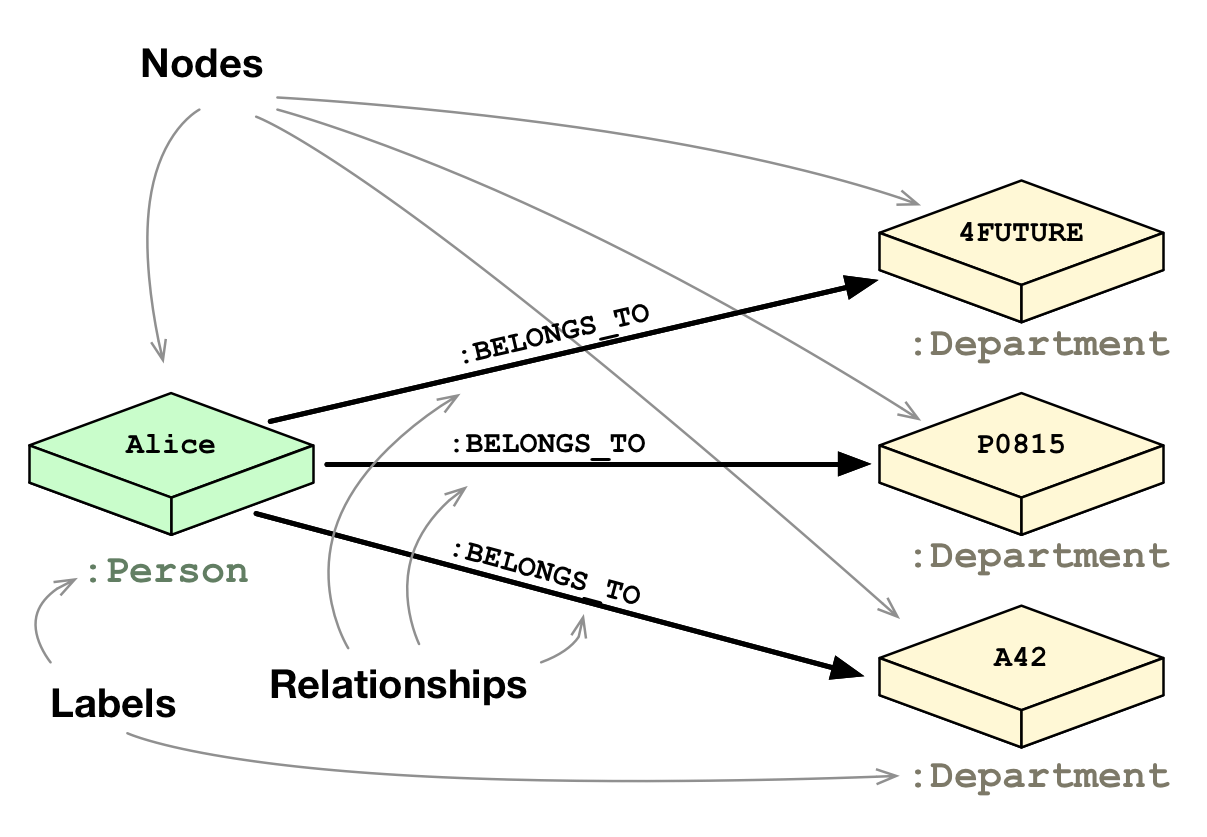
Let’s take an example for making above text much more clear :-
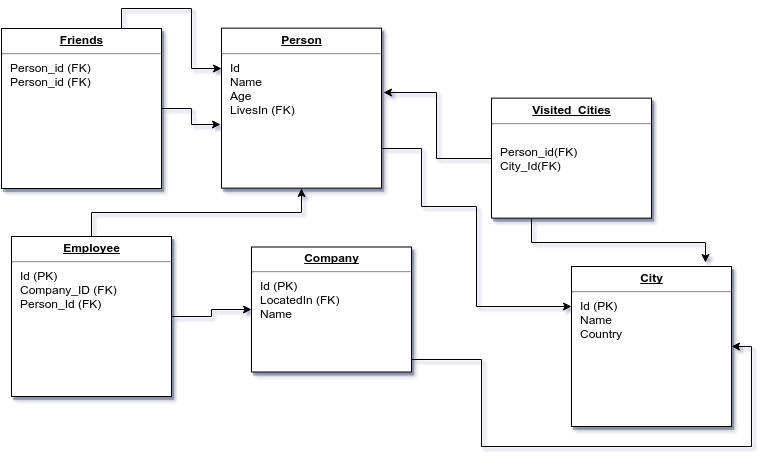
Relational Model
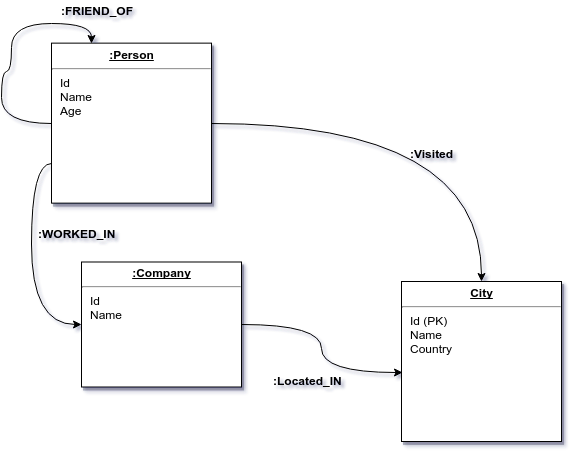
Property Graph Model
Getting started with CQL (Cypher query language) :- According to the documentation “Cypher is a declarative, SQL-inspired language for describing patterns in graphs visually using an ascii-art syntax. It allows us to state what we want to select, insert, update or delete from our graph data without requiring us to describe exactly how to do it.”
A sample query to find ‘Name of Persons who have visited a specific city’
(Consider above domain model)
In SQL :-
SELECT name FROM Person LEFT JOIN VISITED_CITIES ON Person.Id = VISITED_CITIES.Person_Id LEFT JOIN City ON City.Id = VISITED_CITIES.City_Id WHERE CITY.name = “New Delhi”
In CQL :-
MATCH (p:Person)-[:VISITED]->(c:City) WHERE c.name = “New Delhi” RETURN p.name
You may have observed that in SQL we have to define all the process of how to join tables and evaluate relationships to fetch data but in CQL we just have to define what to fetch. Also the use of patterns makes it much more intuitive and different queries can be simplified in CQL because of the same.
The above discussion is useful when you have decided to use Neo4J in your next BIG project, but what before that, one must decide why to prefer this over other NoSQL solutions. Below are some of my readings and findings about Neo4j, it brings the best of both relational and nosql databases.
- Flexible Schema
- Property graph model stores data in its natural form i.e having properties for both the nodes and relationships that exists between them.
- Change properties on the fly as and when your domain model evolves using CYPHER QUERY LANGUAGE
- ACID :- While many NoSQL databases keep ACID out, Neo4j brings
- Scale and Performance :- It provides in-built replication and high availability (Enterprise edition).
- Cypher Query Language :- Powerful SQL like language for traversing and updating graphs with the help of a pattern matching syntax.
- Development Tools :- Built in browser for executing queries and visualization using web-browser
I hope the above points are enough to get you intrigued and start with the same, so go on and install Neo4j. Here are the steps to install neo4j, as per their website :-
Download the archive from https://neo4j.com/download/
- Open up your terminal/shell.
- Extract the contents of the archive, using:
- tar -xf <filecode>.
- For example,
- tar -xf neo4j-enterprise-2.3.1-unix.tar.gz
- the top level directory is referred to as NEO4J_HOME
- Run Neo4j using,
- $NEO4J_HOME/bin/neo4j console
- Instead of ‘neo4j console’, you can use neo4j start to start the server process in the background.
- Visit http://localhost:7474 in your web browser.
- Change the password for the ‘neo4j’ account.
Stay tuned for more on :-
- Cypher Query Language
- Neo4j with Rest
- Spring Data with Neo4j
Thanks for reading, see you next time.